Declaration officielle
Ce qu'il faut comprendre
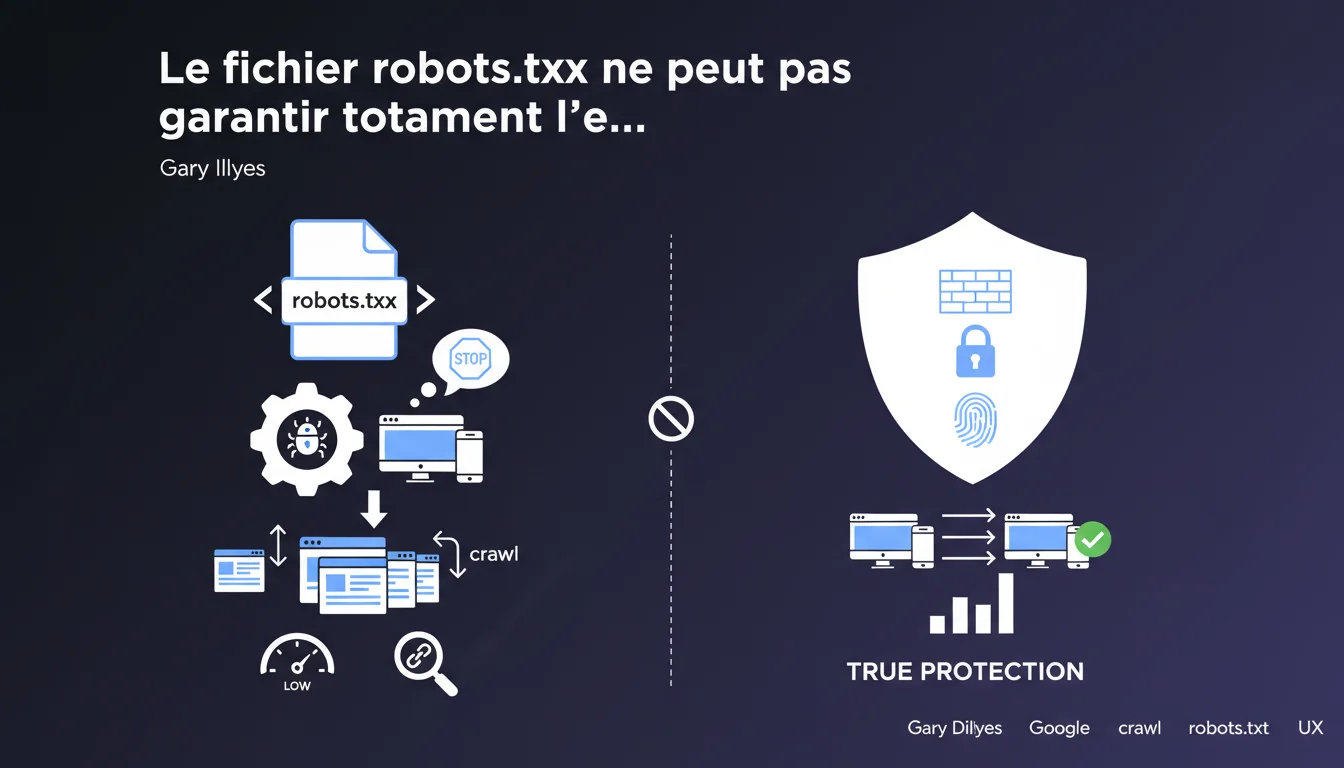
Le fichier robots.txt est souvent perçu à tort comme une barrière de sécurité. En réalité, il s'agit simplement d'un fichier de directives que les robots des moteurs de recherche sont invités à respecter, sans aucune garantie d'application.
Google rappelle ici une vérité fondamentale : robots.txt n'est qu'une demande polie, pas un mécanisme de sécurité. N'importe quel crawler malveillant ou non conforme peut choisir de l'ignorer totalement et accéder aux contenus que vous pensiez protéger.
Cette clarification est essentielle car de nombreux propriétaires de sites utilisent robots.txt pour masquer des contenus sensibles : pages de staging, données personnelles, ou sections en développement. Cette approche crée une fausse impression de sécurité.
- Robots.txt = recommandation, pas un blocage technique
- Les crawlers respectueux (Google, Bing) suivent ces directives
- Les bots malveillants peuvent totalement ignorer ces instructions
- Le fichier robots.txt est public et consultable par tous
- Une vraie protection nécessite authentification ou pare-feu
Avis d'un expert SEO
Cette déclaration est parfaitement cohérente avec ce que nous observons sur le terrain depuis des années. Les SEO expérimentés savent que robots.txt sert à gérer le crawl budget et l'indexation, jamais à sécuriser du contenu.
La nuance importante concerne le double usage du fichier. D'un côté, il reste un outil précieux pour optimiser l'exploration de votre site par les moteurs légitimes : bloquer les pages dupliquées, les filtres à facettes infinis, ou les URLs avec paramètres. De l'autre, il ne doit jamais être votre seule ligne de défense.
Dans les cas d'environnements de développement ou de staging, l'erreur classique est de se reposer uniquement sur robots.txt. Ces environnements doivent impérativement être protégés par authentification HTTP, restriction IP, ou hébergement sur domaine privé.
Impact pratique et recommandations
- Auditer immédiatement votre fichier robots.txt actuel : identifiez toutes les sections bloquées et demandez-vous pourquoi
- Identifier les contenus sensibles actuellement "protégés" uniquement par robots.txt (admin, staging, données privées)
- Mettre en place une authentification par mot de passe (.htaccess, HTTP Basic Auth) pour tous les contenus réellement confidentiels
- Configurer des restrictions IP pour les environnements de développement et préproduction
- Utiliser la balise meta noindex (ou X-Robots-Tag) pour empêcher l'indexation de pages qui peuvent être crawlées
- Combiner robots.txt et noindex stratégiquement : bloquez le crawl des pages sans valeur SEO, utilisez noindex pour les pages crawlables mais non-indexables
- Vérifier régulièrement dans Google Search Console les URLs bloquées par robots.txt qui apparaissent quand même dans l'index
- Former les équipes de développement sur cette distinction fondamentale entre directive et protection
- Documenter votre stratégie : créez un tableau précisant pourquoi chaque section est bloquée dans robots.txt (optimisation crawl vs tentative de sécurité)
La mise en place d'une architecture de sécurité et d'indexation robuste nécessite une compréhension approfondie des interactions entre robots.txt, balises meta, en-têtes HTTP et mécanismes d'authentification. Ces aspects techniques touchent à la fois la sécurité web et le SEO avancé.
Pour les sites d'envergure ou les architectures complexes, l'accompagnement d'une agence SEO spécialisée permet d'établir une stratégie cohérente qui protège véritablement vos contenus sensibles tout en optimisant la découvrabilité de vos pages importantes. Un audit technique complet peut révéler des vulnérabilités insoupçonnées dans votre configuration actuelle.
💬 Commentaires (0)
Soyez le premier à commenter.