Declaration officielle
Autres déclarations de cette vidéo 12 ▾
- □ Pourquoi robots.txt disallow peut-il indexer vos URLs sans que vous puissiez rien y faire ?
- □ Comment Google gère-t-il réellement les codes de statut HTTP lors du crawl ?
- □ Pourquoi Google extrait-il les balises meta robots et canonical pendant l'indexation plutôt qu'au crawl ?
- □ Pourquoi un noindex sur une page hreflang peut-il contaminer tout votre cluster international ?
- □ Faut-il vraiment compter sur JavaScript pour gérer le noindex ?
- □ Comment désindexer un PDF ou un fichier binaire avec l'en-tête X-Robots-Tag ?
- □ La directive unavailable_after ralentit-elle vraiment le crawling de Google ?
- □ Faut-il désactiver le cache Google pour maîtriser l'affichage de vos snippets ?
- □ Peut-on vraiment forcer Google à rafraîchir un snippet sans être propriétaire du site ?
- □ L'outil de suppression de Google supprime-t-il vraiment vos URLs de l'index ?
- □ Pourquoi Google met-il des mois à supprimer définitivement une page de son index ?
- □ L'outil de suppression Google bloque-t-il réellement le crawl des pages ?
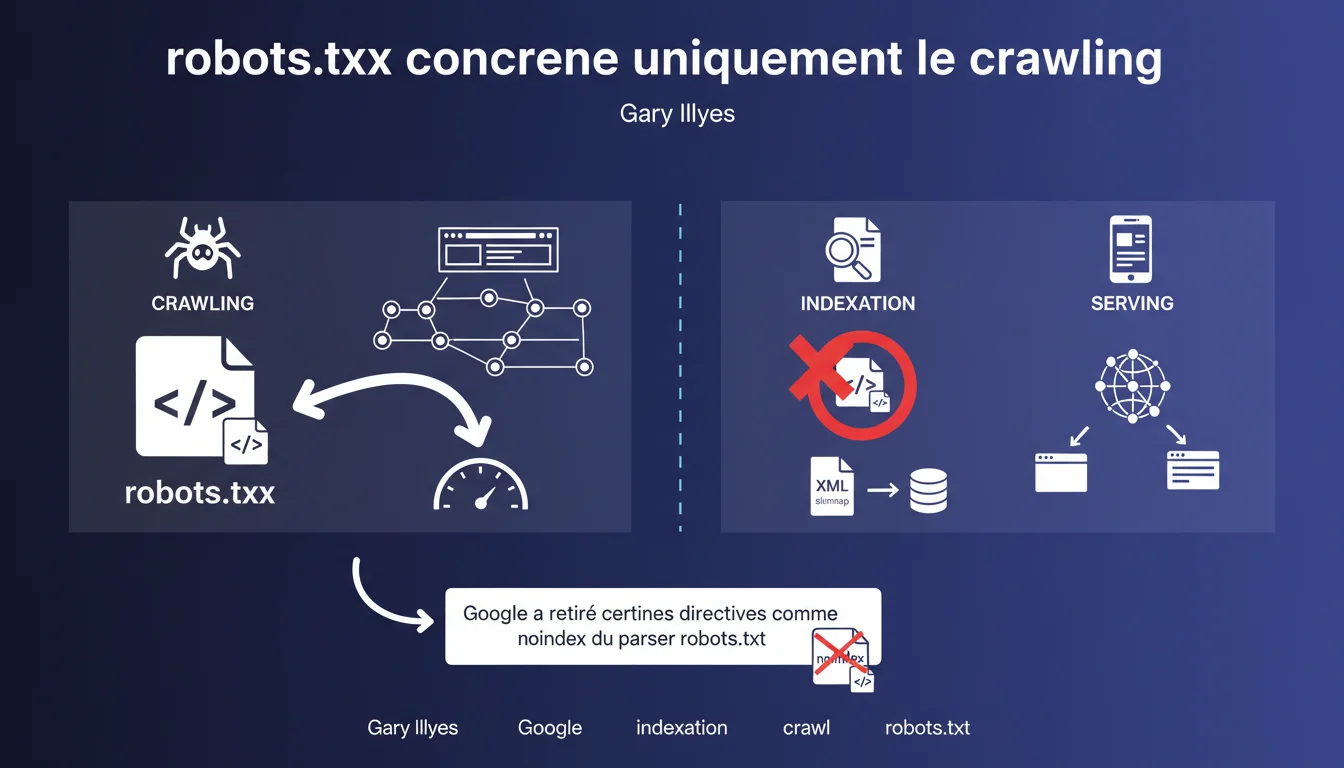
Google a retiré la directive noindex du parser robots.txt et insiste : ce fichier ne doit servir qu'à contrôler le crawling, pas l'indexation. Une clarification qui force à revoir certaines pratiques encore répandues chez les praticiens SEO.
Ce qu'il faut comprendre
Quelle est la fonction réelle du fichier robots.txt ?
Le robots.txt est un fichier de contrôle du crawl — rien de plus. Il indique aux robots quelles URLs ne doivent pas être explorées, ce qui permet de gérer le budget de crawl et d'éviter l'exploration de zones inutiles.
Ce n'est pas un outil d'indexation. Bloquer une URL dans robots.txt empêche Googlebot de la crawler, mais ne garantit en rien qu'elle disparaîtra de l'index si elle a déjà été découverte par d'autres moyens — backlinks, sitemaps partagés ailleurs, etc.
Pourquoi Google a-t-il retiré la directive noindex du robots.txt ?
Parce qu'elle ne concernait jamais le crawl. La directive noindex, initialement supportée par certains moteurs comme extension non-officielle, servait à contrôler l'indexation — ce qui sort du périmètre strict du fichier robots.txt.
Google a formalisé cette position en retirant la directive de son parser. Le message est clair : utilisez les meta robots, les en-têtes HTTP X-Robots-Tag ou la Search Console pour gérer l'indexation.
Quelles sont les conséquences pratiques de cette décision ?
- Le robots.txt reste efficace uniquement pour bloquer le crawl
- Toute directive d'indexation (noindex, nofollow dans robots.txt) est désormais ignorée
- Les sites qui utilisaient noindex dans robots.txt doivent migrer vers des méthodes officielles
- Une URL bloquée en robots.txt peut toujours apparaître dans l'index si elle dispose de backlinks externes
- Pour désindexer proprement, il faut autoriser le crawl ET ajouter une balise noindex
Avis d'un expert SEO
Cette clarification change-t-elle vraiment la donne sur le terrain ?
Soyons honnêtes — la plupart des praticiens SEO sérieux n'utilisaient déjà plus noindex dans robots.txt. Cette directive n'a jamais fait partie du standard officiel, même si Google l'a tolérée pendant des années.
Ce qui change, c'est la formalisation. Google retire le support, ce qui force les retardataires à nettoyer leurs pratiques. Certains sites legacy utilisaient encore cette méthode par habitude ou méconnaissance — ils vont découvrir que leurs directives sont devenues inopérantes.
Cette position de Google est-elle cohérente avec les pratiques observées ?
Totalement. On observe depuis longtemps que bloquer une URL en robots.txt n'empêche pas son indexation si elle reçoit des signaux externes (liens, mentions). Google peut indexer une page sans la crawler — il lui suffit de connaître son existence et d'avoir des signaux de pertinence.
Le problème, c'est que certains référenceurs continuent de croire qu'un blocage robots.txt = désindexation garantie. Faux. Si vous voulez retirer une URL de l'index, il faut qu'elle soit crawlable ET qu'elle porte une directive noindex — sinon Google ne peut pas lire l'instruction.
Quelles zones grises subsistent malgré cette clarification ?
Google ne précise pas toujours ce qui se passe quand une URL déjà indexée est ensuite bloquée en robots.txt. En théorie, elle devrait rester dans l'index avec une mention "pas de description disponible" — mais les comportements varient. [À vérifier] selon les contextes et les signaux externes.
Impact pratique et recommandations
Que faut-il vérifier immédiatement sur son site ?
Ouvrez votre robots.txt et cherchez toute mention de noindex, nofollow, noarchive ou autres directives d'indexation. Si vous en trouvez, elles sont ignorées — il faut migrer vers des méthodes valides.
Vérifiez également les URLs bloquées en robots.txt qui apparaissent encore dans l'index Google (requête site:votredomaine.com). Si elles sont présentes, c'est normal — le blocage crawl n'est pas une désindexation.
Comment gérer proprement l'indexation désormais ?
Pour bloquer l'indexation d'une page, vous avez trois options officielles :
- Balise
<meta name="robots" content="noindex">dans le <head> HTML - En-tête HTTP X-Robots-Tag: noindex (utile pour PDFs, images, fichiers non-HTML)
- Suppression via la Search Console (temporaire — 6 mois, puis renouveler ou implémenter une solution technique)
Pour ces trois méthodes, il est impératif que l'URL soit crawlable. Ne bloquez jamais en robots.txt une URL que vous souhaitez désindexer — sinon Google ne peut pas lire la directive noindex.
Quelles erreurs éviter absolument ?
Ne confondez jamais crawl et indexation. Bloquer le crawl n'empêche pas l'indexation. Autoriser le crawl ne force pas l'indexation. Ce sont deux mécanismes distincts avec des outils distincts.
Évitez de bloquer en robots.txt des sections entières juste pour "économiser du budget crawl" si ces sections contiennent des pages que vous ne voulez pas indexer. Vous risquez de les voir apparaître dans l'index sans description ni contrôle.
❓ Questions frequentes
Puis-je encore utiliser noindex dans le robots.txt ?
Une URL bloquée en robots.txt peut-elle être indexée ?
Comment désindexer proprement une page ?
Le fichier robots.txt impacte-t-il le ranking ?
Que faire si j'ai des directives noindex dans mon robots.txt actuel ?
🎥 De la même vidéo 12
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 04/08/2022
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.