Declaration officielle
Autres déclarations de cette vidéo 12 ▾
- □ Pourquoi Google refuse-t-il désormais certaines directives dans le robots.txt ?
- □ Pourquoi robots.txt disallow peut-il indexer vos URLs sans que vous puissiez rien y faire ?
- □ Comment Google gère-t-il réellement les codes de statut HTTP lors du crawl ?
- □ Pourquoi Google extrait-il les balises meta robots et canonical pendant l'indexation plutôt qu'au crawl ?
- □ Pourquoi un noindex sur une page hreflang peut-il contaminer tout votre cluster international ?
- □ Faut-il vraiment compter sur JavaScript pour gérer le noindex ?
- □ Comment désindexer un PDF ou un fichier binaire avec l'en-tête X-Robots-Tag ?
- □ La directive unavailable_after ralentit-elle vraiment le crawling de Google ?
- □ Peut-on vraiment forcer Google à rafraîchir un snippet sans être propriétaire du site ?
- □ L'outil de suppression de Google supprime-t-il vraiment vos URLs de l'index ?
- □ Pourquoi Google met-il des mois à supprimer définitivement une page de son index ?
- □ L'outil de suppression Google bloque-t-il réellement le crawl des pages ?
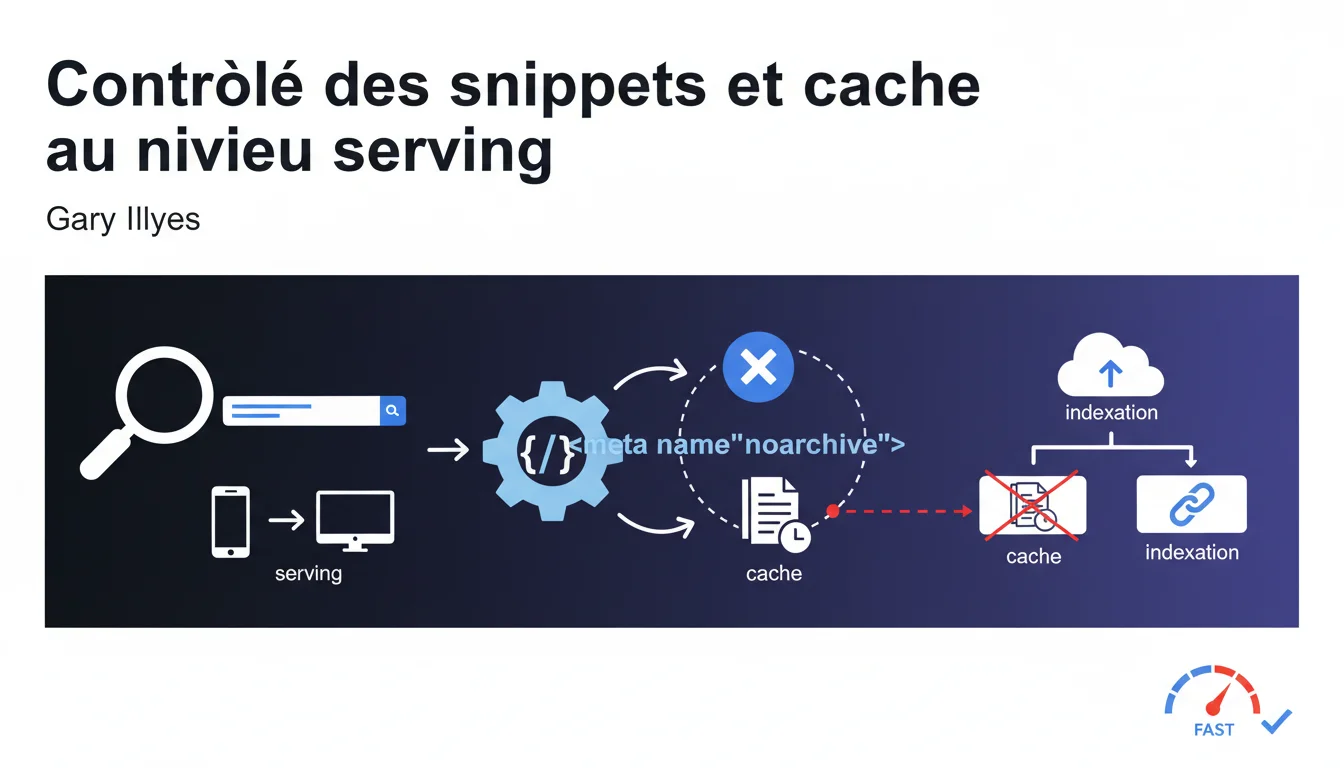
Google permet de contrôler les snippets et le contenu en cache au niveau serving, sans toucher à l'indexation. La balise meta noarchive supprime la page en cache tout en préservant l'indexation intégrale du contenu. Une nuance technique souvent mal comprise qui offre un levier de contrôle granulaire sur l'affichage dans les SERP.
Ce qu'il faut comprendre
Quelle est la différence entre indexation et serving ?
L'indexation concerne la phase où Google analyse, traite et stocke le contenu d'une page dans ses bases de données. Le serving, c'est le moment où Google affiche les résultats de recherche — et c'est à cette étape que les snippets sont générés et que le lien "En cache" apparaît.
Cette distinction est capitale. Désactiver le cache ou limiter les snippets n'impacte pas la capacité de Google à comprendre et indexer votre contenu. Vous contrôlez l'affichage, pas le traitement en amont.
Comment fonctionne la balise meta noarchive ?
La balise <meta name="robots" content="noarchive"> indique à Google de ne pas proposer le lien "En cache" dans les résultats de recherche. Votre page reste indexée normalement, son contenu est analysé et utilisé pour le classement, mais l'utilisateur ne pourra pas consulter la version en cache.
Concrètement ? Google continue de crawler, d'indexer, d'évaluer votre contenu pour le ranking. Seul l'affichage du cache est désactivé côté utilisateur final.
Pourquoi cette séparation entre indexation et affichage est-elle importante ?
Parce qu'elle permet un contrôle granulaire sans sacrifice. Vous pouvez masquer le cache pour protéger du contenu sensible ou éviter des versions obsolètes visibles, sans pour autant pénaliser votre visibilité organique.
C'est aussi un signal rassurant : utiliser noarchive ou max-snippet ne vous coûte rien en termes de SEO technique. Vous gardez le bénéfice de l'indexation tout en ajustant l'affichage selon vos besoins.
- Le serving concerne uniquement l'affichage dans les SERP, pas le traitement du contenu par Google
- La balise noarchive supprime le cache sans affecter l'indexation ni le ranking
- Les directives de snippet (max-snippet, max-video-preview, max-image-preview) agissent aussi au niveau serving
- Cette séparation offre un levier de contrôle sans compromis sur la visibilité organique
Avis d'un expert SEO
Cette déclaration est-elle cohérente avec les pratiques observées ?
Oui, et c'est même un des rares sujets où Google est transparent et cohérent depuis des années. Les tests terrain confirment : une page avec noarchive reste indexée, rankée, et génère du trafic normalement. Le seul effet visible, c'est l'absence du lien "En cache" dans les résultats.
Mais — et c'est là que ça coince parfois — certains SEO confondent encore noarchive avec noindex, ou pensent que limiter les snippets nuit au ranking. Spoiler : non. Google n'a jamais pénalisé une page parce qu'elle contrôle son affichage.
Dans quels cas cette directive est-elle vraiment utile ?
Soyons honnêtes : pour la majorité des sites, désactiver le cache n'apporte rien. C'est surtout pertinent pour du contenu sensible, évolutif ou payant — sites de presse premium, e-commerce avec des prix fluctuants, pages contenant des informations personnelles.
Le risque ? Qu'un utilisateur accède à une version obsolète via le cache et signale des incohérences (prix périmé, stock épuisé). Dans ces cas, noarchive est un filet de sécurité légitime.
Quelle est la limite de cette approche ?
Google parle de contrôle au niveau serving, mais reste évasif sur la granularité exacte. Par exemple : peut-on contrôler différemment les snippets selon les types de requêtes ? Peut-on forcer un snippet spécifique pour certaines pages stratégiques ? [A vérifier] — les outils disponibles (meta robots, structured data) restent assez binaires.
Autre point : cette déclaration ne dit rien sur les featured snippets. Or, contrôler un snippet classique, c'est une chose ; empêcher Google de vous positionner en position 0 avec un extrait non souhaité, c'en est une autre. Et là, les leviers sont nettement plus limités.
Impact pratique et recommandations
Que faut-il faire concrètement pour contrôler le cache et les snippets ?
Pour désactiver le cache, ajoutez simplement <meta name="robots" content="noarchive"> dans le <head> de vos pages. Vous pouvez aussi combiner avec d'autres directives : noarchive, max-snippet:150 pour limiter la longueur du snippet à 150 caractères.
Pour un contrôle plus fin, utilisez les balises X-Robots-Tag dans vos headers HTTP — utile pour des fichiers non-HTML (PDF, images) ou pour appliquer des règles dynamiques côté serveur.
Quelles erreurs éviter avec ces directives ?
Ne confondez jamais noarchive et noindex. Le premier masque le cache, le second désindexe complètement la page. Combiner les deux par mégarde, c'est perdre toute visibilité organique.
Évitez aussi de bloquer le cache par défaut sur tout le site "au cas où". Ça n'a aucun intérêt SEO et prive les utilisateurs d'un moyen parfois utile d'accéder à votre contenu (page temporairement indisponible, serveur lent).
Comment vérifier que vos directives sont bien appliquées ?
Inspectez vos pages avec l'outil Inspection d'URL dans Google Search Console. Il affiche les directives d'indexation détectées par Google, y compris noarchive, max-snippet, etc.
Côté SERP, faites une recherche site:votredomaine.com et vérifiez manuellement l'absence du lien "En cache" sur les pages concernées. Si le cache persiste après plusieurs semaines, c'est qu'il y a un problème d'implémentation.
- Ajoutez
<meta name="robots" content="noarchive">dans le head des pages sensibles - Utilisez X-Robots-Tag dans les headers HTTP pour les fichiers non-HTML
- Ne combinez jamais noarchive et noindex par erreur
- Testez vos directives avec Google Search Console (Inspection d'URL)
- Vérifiez manuellement l'affichage dans les SERP avec site:votredomaine.com
- Documentez vos choix pour éviter les régressions lors de refontes
❓ Questions frequentes
La balise noarchive affecte-t-elle le classement de ma page ?
Peut-on combiner noarchive avec d'autres directives robots ?
Le cache Google protège-t-il contre le scraping ?
Comment désactiver le cache pour des fichiers PDF ou images ?
Faut-il désactiver le cache sur tout le site par précaution ?
🎥 De la même vidéo 12
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 04/08/2022
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.