Declaration officielle
Autres déclarations de cette vidéo 12 ▾
- □ Pourquoi Google refuse-t-il désormais certaines directives dans le robots.txt ?
- □ Pourquoi robots.txt disallow peut-il indexer vos URLs sans que vous puissiez rien y faire ?
- □ Pourquoi Google extrait-il les balises meta robots et canonical pendant l'indexation plutôt qu'au crawl ?
- □ Pourquoi un noindex sur une page hreflang peut-il contaminer tout votre cluster international ?
- □ Faut-il vraiment compter sur JavaScript pour gérer le noindex ?
- □ Comment désindexer un PDF ou un fichier binaire avec l'en-tête X-Robots-Tag ?
- □ La directive unavailable_after ralentit-elle vraiment le crawling de Google ?
- □ Faut-il désactiver le cache Google pour maîtriser l'affichage de vos snippets ?
- □ Peut-on vraiment forcer Google à rafraîchir un snippet sans être propriétaire du site ?
- □ L'outil de suppression de Google supprime-t-il vraiment vos URLs de l'index ?
- □ Pourquoi Google met-il des mois à supprimer définitivement une page de son index ?
- □ L'outil de suppression Google bloque-t-il réellement le crawl des pages ?
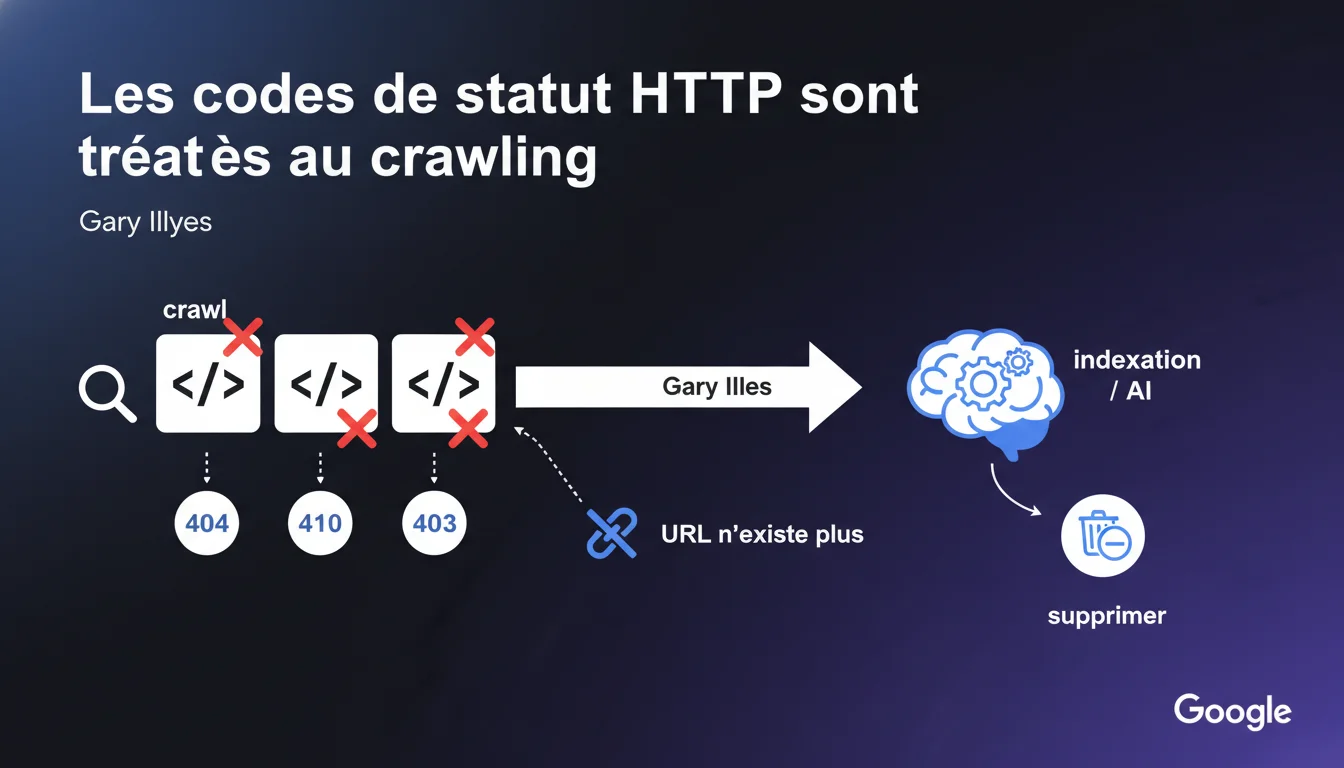
Google détecte les codes 404, 410 et 403 pendant le crawl, pas après. Le crawler transmet un signal à l'indexation pour supprimer l'URL, sans jamais lui transmettre le contenu de la page. Cette distinction entre crawl et indexation change la façon dont on doit penser la gestion des erreurs serveur.
Ce qu'il faut comprendre
Pourquoi cette séparation entre crawl et indexation est-elle importante ?
Google fonctionne avec deux systèmes distincts : le crawler (Googlebot) et l'indexeur. Gary Illyes précise que les codes de statut HTTP ne sont pas évalués au moment de l'indexation, mais bien en amont, pendant le crawl.
Concrètement ? Le Googlebot fait sa requête, reçoit un 404, 410 ou 403, et envoie immédiatement un signal à l'indexation : « Cette URL n'existe plus, supprime-la. » Le contenu de la page n'est jamais transmis ni analysé par l'indexeur.
Qu'est-ce que ça change par rapport à ce qu'on croyait savoir ?
Beaucoup de SEO pensaient que Google analysait d'abord la page, puis vérifiait le code de statut. Erreur. Le code HTTP est traité avant toute analyse de contenu.
Cette logique explique pourquoi une page en 404 disparaît rapidement de l'index, même si son contenu était excellent. L'indexeur ne le voit jamais — il reçoit juste l'ordre de supprimer l'URL.
Quels sont les codes de statut concernés par ce processus ?
Gary Illyes cite explicitement trois codes : 404 (ressource introuvable), 410 (suppression définitive) et 403 (accès refusé). Ces trois codes déclenchent le même mécanisme : signal de suppression envoyé à l'indexation.
- Le crawler détecte le code HTTP pendant la requête
- Un signal de suppression est transmis à l'indexation
- L'indexeur ne reçoit jamais le contenu de la page
- La décision de désindexation appartient à l'indexation, mais elle suit quasi-systématiquement le signal du crawler
- Ce processus s'applique aux 404, 410 et 403 de manière identique
Avis d'un expert SEO
Cette déclaration est-elle cohérente avec les observations terrain ?
Oui, et elle clarifie un point que beaucoup de SEO avaient mal compris. On observe effectivement que les pages en 404 disparaissent de l'index sans période de grâce, même si elles étaient bien rankées.
Mais — et c'est là que ça coince — Gary ne précise pas combien de temps l'indexation met à réagir au signal. On constate que certaines URLs persistent plusieurs semaines en cache Google malgré un 404. [À vérifier] : ce délai est-il lié à la fréquence de crawl, à la priorité de l'URL, ou à un autre facteur ?
Quelle nuance importante faut-il apporter ici ?
Gary dit que « l'indexation décide de supprimer » l'URL. Cette formulation laisse entendre qu'il y a une décision, donc une marge d'interprétation. Dans la réalité, cette décision semble automatique pour les 404/410/403.
Attention : cette déclaration ne couvre pas les redirections 301/302, ni les codes 5xx (erreurs serveur). Pour les 5xx, Google adopte une stratégie différente — il réessaye plusieurs fois avant de considérer la page comme inaccessible.
Que faire des pages en soft 404 dans ce cadre ?
Gary ne mentionne pas les soft 404 (page avec contenu d'erreur mais code 200). C'est révélateur. Google les traite différemment : le crawler transmet la page à l'indexation, qui doit analyser le contenu pour détecter qu'il s'agit d'une erreur.
Résultat : les soft 404 restent plus longtemps dans l'index et consomment du crawl budget inutilement. Soyons honnêtes — c'est une plaie pour les gros sites e-commerce avec des milliers de produits épuisés.
Impact pratique et recommandations
Que faut-il faire concrètement sur mon site ?
Première règle : renvoyer le bon code HTTP au bon moment. Pas de 200 sur une page d'erreur, pas de 404 sur une page temporairement indisponible.
Pour les produits épuisés en e-commerce, plusieurs stratégies existent. Certains mettent un 404 immédiat (risque de perdre des backlinks), d'autres maintiennent la page en 200 avec un message « rupture de stock » (risque de soft 404). Le choix dépend de votre stratégie de réapprovisionnement.
Quelles erreurs éviter absolument ?
Ne confondez pas 403 et 503. Un 403 déclenche une désindexation, un 503 indique une indisponibilité temporaire — Google va réessayer plus tard sans désindexer.
Évitez les chaînes de redirections qui aboutissent à un 404. Google crawle la première URL, suit la redirection, rencontre le 404 — et désindexe. Résultat : vous avez perdu l'équité de lien et la page disparaît de l'index.
Comment vérifier que mon site gère correctement ces codes ?
Utilisez la Search Console : l'onglet « Couverture » ou « Pages » liste toutes les URLs exclues avec leur code de statut. Filtrez par 404/410/403 et vérifiez qu'il n'y a pas de mauvaise surprise.
Testez manuellement avec curl -I ou un outil comme Screaming Frog. Vérifiez que chaque type de page renvoie le bon code : page supprimée = 410, page jamais existé = 404, accès restreint temporaire = 503.
- Auditer les codes de statut HTTP de toutes les URLs indexées
- Remplacer les soft 404 par de vrais 404 quand c'est pertinent
- Utiliser 410 pour les suppressions définitives (produits abandonnés, contenus obsolètes)
- Configurer un 503 avec Retry-After pour les maintenances planifiées
- Monitorer la Search Console pour détecter les nouvelles erreurs 404/403
- Mettre en place des redirections 301 pour les pages supprimées ayant des backlinks de qualité
- Tester régulièrement avec curl ou Screaming Frog pour valider les codes renvoyés
❓ Questions frequentes
Un 410 est-il vraiment différent d'un 404 pour Google ?
Pourquoi une page en 404 reste-t-elle parfois visible dans l'index pendant plusieurs semaines ?
Que se passe-t-il si je remets en ligne une page qui était en 404 ?
Les erreurs 5xx sont-elles traitées de la même façon que les 404 ?
Faut-il utiliser un 403 pour bloquer l'accès à certaines sections du site ?
🎥 De la même vidéo 12
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 04/08/2022
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.