Declaration officielle
Autres déclarations de cette vidéo 4 ▾
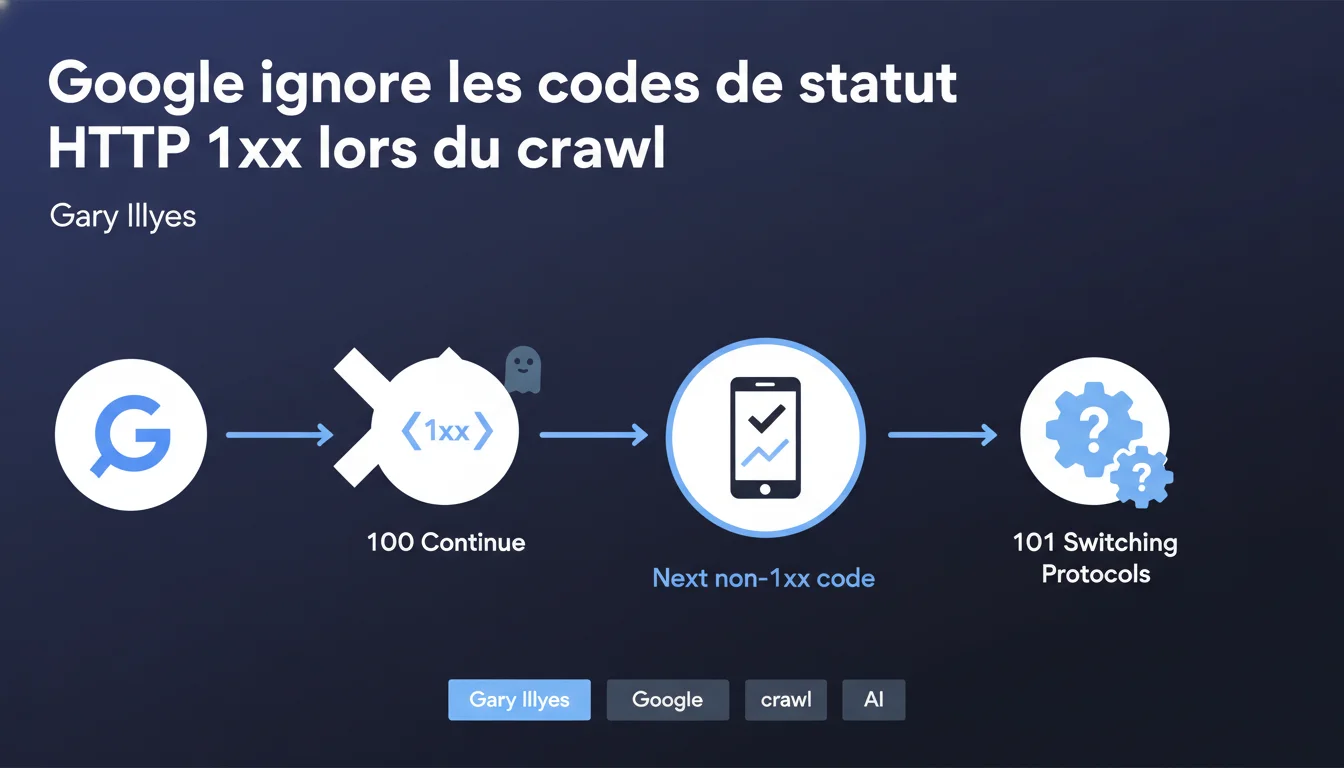
Google ignore purement et simplement les codes HTTP 1xx (100 Continue, 101 Switching Protocols, etc.). Le crawler traverse ces réponses intermédiaires sans les traiter et attend le prochain code de statut non-1xx pour évaluer la requête. En clair : ces codes n'ont aucun impact sur le SEO, ni positif ni négatif.
Ce qu'il faut comprendre
Que sont réellement les codes HTTP 1xx et pourquoi existent-ils ?
Les codes de statut HTTP 1xx sont des réponses informationnelles — des messages temporaires échangés entre le client et le serveur avant la réponse finale. Le plus connu est le 100 Continue, qui permet au serveur de dire « OK, continue d'envoyer ton corps de requête » avant de traiter la demande complète.
Le 101 Switching Protocols, lui, sert à basculer d'un protocole à un autre — par exemple lors d'une connexion WebSocket. Ces codes ne sont jamais définitifs : ils signalent simplement que la transaction HTTP est en cours.
Comment Googlebot réagit-il face à un code 1xx ?
La déclaration de Gary Illyes est limpide : Googlebot ignore complètement ces codes. Il ne les traite pas, ne les enregistre pas, ne les interprète pas. Il attend simplement le code de statut final (200, 301, 404, etc.) pour décider de la suite.
Techniquement, le crawler traverse ces réponses intermédiaires comme s'il passait à travers un rideau transparent. Aucune évaluation, aucune décision d'indexation, rien.
Quelles implications concrètes pour le référencement ?
Si votre serveur envoie des codes 1xx avant de répondre avec un 200, cela n'a aucun impact SEO. Googlebot les ignore et passe directement au code suivant.
- Pas de pénalité si votre serveur envoie un 100 Continue avant un 200 OK
- Pas de ralentissement du crawl — le temps de réponse compte, mais pas la présence d'un code 1xx
- Aucune optimisation possible via ces codes : ils sont invisibles pour le moteur
- Seul le code de statut final (200, 301, 404…) compte pour l'indexation et le positionnement
Avis d'un expert SEO
Cette déclaration change-t-elle quelque chose aux pratiques terrain ?
Non — et c'est justement ça qui est intéressant. Très peu de sites utilisent activement des codes 1xx dans leurs configurations serveur. La plupart des professionnels SEO n'ont jamais eu à s'en soucier, et cette déclaration confirme qu'ils ont raison de les ignorer.
Ce qui mérite attention, c'est que cette clarification ferme une porte à d'éventuelles tentatives d'optimisation ou de manipulation via ces codes. Inutile de bricoler une architecture serveur exotique en espérant un gain SEO : Google s'en fiche.
Quelles zones d'ombre subsistent dans cette annonce ?
Gary Illyes reste vague sur un point : que se passe-t-il si le serveur envoie un code 1xx puis plante ? Googlebot attend-il indéfiniment le code final, ou y a-t-il un timeout qui déclenche une erreur crawl ?
[À vérifier] Le comportement exact en cas d'absence de code final après un 1xx n'est pas documenté. En pratique, un timeout classique se déclenche probablement — mais Google ne le précise pas explicitement.
Un détail technique… ou un rappel utile ?
Cette déclaration semble anodine — et elle l'est pour 99 % des sites. Mais elle a le mérite de rappeler une règle SEO fondamentale : seuls les codes de statut HTTP finaux (2xx, 3xx, 4xx, 5xx) influencent le comportement du crawler.
Tout ce qui relève de la mécanique interne du protocole HTTP (négociations, confirmations intermédiaires) n'a aucune importance pour le référencement. Google ne s'intéresse qu'au résultat final de la requête.
Impact pratique et recommandations
Faut-il modifier votre configuration serveur ?
Non. Sauf si vous utilisez des codes 1xx pour des raisons techniques spécifiques (API complexes, WebSockets, requêtes volumineuses avec 100 Continue), vous n'avez rien à changer.
Si votre serveur envoie déjà ces codes, ils n'ont aucun impact négatif sur le crawl. Si vous ne les utilisez pas, inutile de les ajouter.
Comment vérifier que Google crawle correctement vos pages ?
Concentrez-vous sur les codes de statut finaux — ceux qui comptent réellement pour l'indexation. Ignorez les codes 1xx dans vos logs : ils ne vous apprennent rien sur le comportement de Googlebot.
- Analysez les logs serveur pour identifier les codes de statut renvoyés aux crawlers (200, 301, 404…)
- Utilisez la Search Console pour détecter les erreurs crawl (timeout, 5xx, 4xx)
- Vérifiez que vos redirections 301/302 fonctionnent correctement — ce sont elles qui guident le crawler
- Si des codes 1xx apparaissent dans vos logs, ne perdez pas de temps à les corriger : Google les ignore
- Concentrez vos efforts sur la vitesse de réponse (TTFB) et la stabilité serveur — pas sur les codes intermédiaires
Quelle stratégie adopter à long terme ?
Simplifiez votre architecture HTTP autant que possible. Moins il y a d'étapes entre la requête et la réponse finale, mieux c'est — pour la performance comme pour la maintenabilité.
Si vous gérez un site complexe avec des configurations serveur sur mesure, assurez-vous que les codes de statut finaux sont cohérents et prévisibles. C'est ce que Google analyse, point final.
Cette déclaration confirme que les codes HTTP 1xx sont invisibles pour Googlebot. Aucun changement nécessaire dans vos pratiques SEO : concentrez-vous sur les codes finaux (2xx, 3xx, 4xx, 5xx), optimisez la vitesse de réponse et assurez une configuration serveur stable.
Si vous gérez une infrastructure technique complexe avec des architectures HTTP avancées, ces optimisations peuvent nécessiter un audit approfondi et des ajustements délicats. Faire appel à une agence SEO spécialisée permet de bénéficier d'un accompagnement personnalisé pour auditer vos logs, identifier les erreurs crawl critiques et stabiliser vos codes de statut sur l'ensemble de votre architecture.
❓ Questions frequentes
Un code 100 Continue peut-il ralentir le crawl de Google ?
Faut-il désactiver les codes 1xx pour améliorer le SEO ?
Les codes 1xx apparaissent-ils dans les rapports de la Search Console ?
Un serveur qui envoie un 101 Switching Protocols peut-il être pénalisé ?
🎥 De la même vidéo 4
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 15/05/2025
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.