Declaration officielle
Autres déclarations de cette vidéo 12 ▾
- □ Pourquoi Google refuse-t-il désormais certaines directives dans le robots.txt ?
- □ Pourquoi robots.txt disallow peut-il indexer vos URLs sans que vous puissiez rien y faire ?
- □ Comment Google gère-t-il réellement les codes de statut HTTP lors du crawl ?
- □ Pourquoi Google extrait-il les balises meta robots et canonical pendant l'indexation plutôt qu'au crawl ?
- □ Pourquoi un noindex sur une page hreflang peut-il contaminer tout votre cluster international ?
- □ Faut-il vraiment compter sur JavaScript pour gérer le noindex ?
- □ Comment désindexer un PDF ou un fichier binaire avec l'en-tête X-Robots-Tag ?
- □ La directive unavailable_after ralentit-elle vraiment le crawling de Google ?
- □ Faut-il désactiver le cache Google pour maîtriser l'affichage de vos snippets ?
- □ Peut-on vraiment forcer Google à rafraîchir un snippet sans être propriétaire du site ?
- □ L'outil de suppression de Google supprime-t-il vraiment vos URLs de l'index ?
- □ Pourquoi Google met-il des mois à supprimer définitivement une page de son index ?
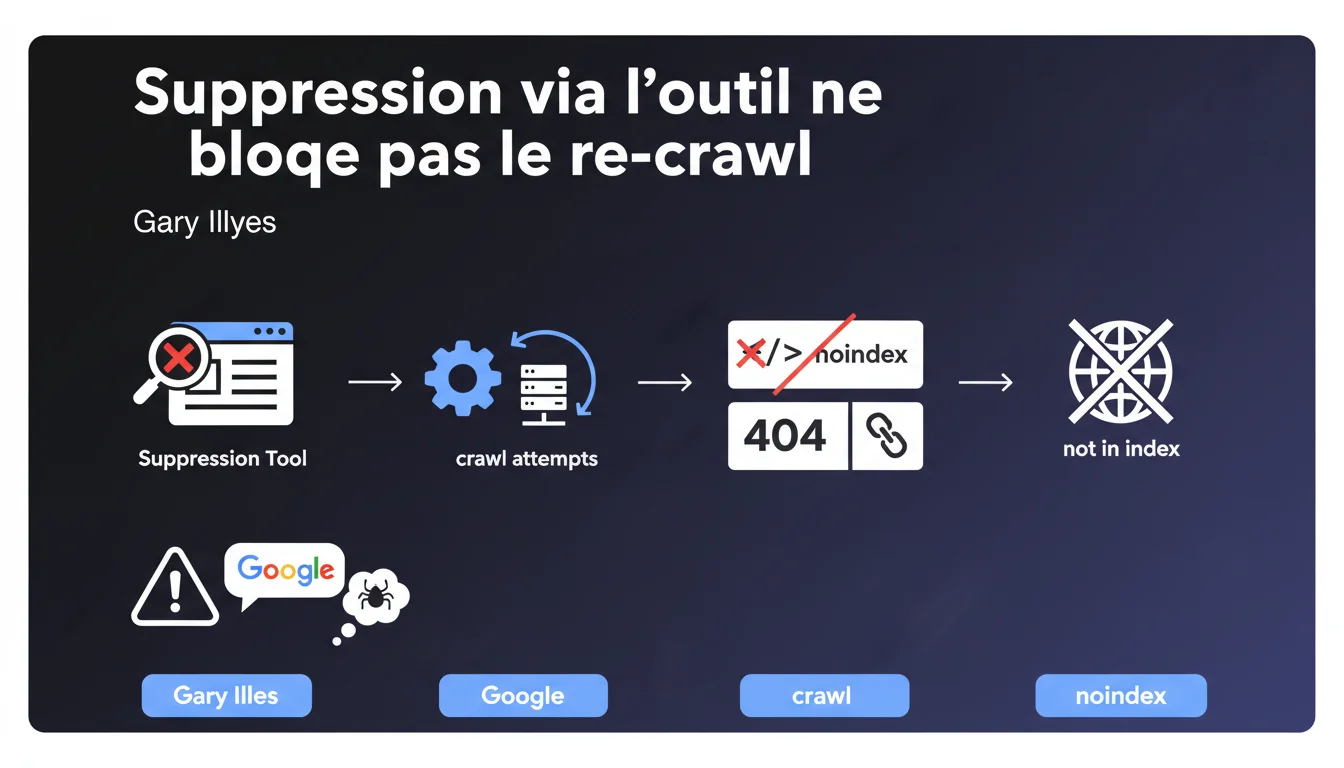
L'outil de suppression d'URL de Google ne stoppe pas le crawl. Googlebot continue de tenter d'explorer la page supprimée. Pour bloquer définitivement l'indexation, il faut ajouter une directive noindex ou renvoyer un code 404/410 — l'outil seul ne suffit pas.
Ce qu'il faut comprendre
Que fait vraiment l'outil de suppression d'URL ?
L'outil de suppression d'URL dans la Search Console retire temporairement une page des résultats de recherche. C'est une action cosmétique côté affichage, pas une instruction d'arrêt de crawl.
Googlebot n'interprète pas cette suppression comme un signal d'exclusion permanente. Le robot continue ses tentatives d'exploration selon son calendrier de crawl habituel. La page disparaît de l'index pour environ 6 mois, mais rien n'empêche Google de revenir la crawler entre-temps.
Pourquoi Google continue-t-il à crawler une URL supprimée ?
Le crawl et l'indexation sont deux processus distincts. L'outil de suppression agit uniquement sur l'affichage dans les résultats, pas sur le comportement de Googlebot.
Si la page reste accessible et crawlable — sans noindex, sans 404 — Google la recrawle normalement. C'est logique : le bot ne peut pas deviner que vous voulez l'exclure définitivement si le serveur répond 200 OK et que le contenu reste indexable.
Quelle est la bonne méthode pour bloquer définitivement une page ?
Pour empêcher un retour dans l'index après suppression, il faut combiner l'outil avec une directive technique. Deux options principales :
- Directive noindex dans le HTML ou via en-tête HTTP X-Robots-Tag
- Code HTTP 404 (page introuvable) ou 410 (ressource supprimée définitivement)
- Éventuellement blocage via robots.txt, mais cette méthode empêche le crawl donc Google ne voit jamais le noindex — à utiliser avec précaution
- L'outil de suppression sert alors à accélérer le retrait temporaire pendant que la directive technique fait effet
Avis d'un expert SEO
Cette distinction crawl/indexation est-elle nouvelle ?
Non. C'est un rappel de base que trop de praticiens oublient encore. La confusion vient du fait que l'outil de suppression porte mal son nom — il ne supprime rien techniquement, il masque temporairement.
Sur le terrain, on voit régulièrement des clients surpris de retrouver des pages « supprimées » dans l'index après quelques semaines. Ils ont utilisé l'outil, mais n'ont jamais mis de noindex ni modifié le code HTTP. Résultat : Googlebot recrawle, trouve un 200 OK, réindexe.
Dans quels cas cette règle pose-t-elle problème ?
Le vrai souci, c'est la gestion d'urgence. Imaginons une fuite de contenu sensible indexé par erreur — données client, pages de test en prod, duplicate massif suite à une migration ratée.
L'outil de suppression permet un retrait rapide (quelques heures), mais si vous comptez uniquement sur lui, la page reviendra. Il faut donc intervenir en parallèle sur le serveur : ajouter noindex ou passer en 404. [A vérifier] : le délai exact de réindexation après suppression varie selon le crawl budget du site — Google ne donne aucun chiffre précis.
Faut-il privilégier 404 ou noindex pour bloquer définitivement ?
Ça dépend de votre intention. Un 404/410 signale une suppression définitive — Google finit par retirer l'URL de son index et arrête de la crawler. C'est net, définitif.
Le noindex permet de garder la page accessible aux visiteurs tout en l'excluant de l'index. Utile pour des pages à faible valeur SEO mais nécessaires (confirmations de commande, espaces membres). Attention : avec noindex, Googlebot continue de crawler pour vérifier la directive — consommation de crawl budget inutile si la page n'a aucune utilité.
Impact pratique et recommandations
Que faut-il faire concrètement pour désindexer une page ?
Procédure en deux temps pour un retrait propre et définitif :
Étape 1 : Retrait immédiat via l'outil de suppression — uniquement si vous avez besoin que la page disparaisse rapidement des résultats (quelques heures). C'est une rustine temporaire, pas une solution pérenne.
Étape 2 : Mise en place d'une directive technique — soit vous ajoutez une balise <meta name="robots" content="noindex"> dans le HTML, soit vous configurez le serveur pour renvoyer un 404 ou 410. Sans cette étape, la page revient dans l'index au bout de quelques semaines ou mois.
Quelles erreurs éviter lors d'une suppression d'URL ?
- Ne jamais compter uniquement sur l'outil de suppression pour un retrait définitif
- Ne pas bloquer via robots.txt une page que vous voulez désindexer — Googlebot doit pouvoir crawler pour lire le noindex
- Ne pas oublier de vérifier les variantes d'URL (HTTP/HTTPS, www/non-www, trailing slash) — chacune peut être indexée séparément
- Ne pas laisser un noindex sur une page que vous voulez indexer plus tard — basculer en 404 temporaire puis réactiver proprement
- Ne pas ignorer les liens internes pointant vers une page supprimée — nettoyer le maillage pour éviter 404 côté UX
Comment vérifier que la suppression est bien effective ?
Utilisez la commande site:votreurl.com dans Google pour vérifier la présence dans l'index. Inspectez l'URL via la Search Console pour voir le statut d'indexation et la dernière tentative de crawl.
Côté serveur, vérifiez les logs pour confirmer que Googlebot reçoit bien le code HTTP attendu (404, 410) ou détecte le noindex. Si le bot continue de crawler une page en 200 OK sans noindex, elle finira par revenir.
❓ Questions frequentes
Combien de temps dure l'effet de l'outil de suppression ?
Peut-on bloquer définitivement via robots.txt ?
Quelle différence entre 404 et 410 pour désindexer ?
Le noindex consomme-t-il du crawl budget ?
Faut-il utiliser l'outil de suppression après avoir mis un noindex ?
🎥 De la même vidéo 12
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 04/08/2022
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.