Official statement
Other statements from this video 12 ▾
- □ Pourquoi Google refuse-t-il désormais certaines directives dans le robots.txt ?
- □ Pourquoi robots.txt disallow peut-il indexer vos URLs sans que vous puissiez rien y faire ?
- □ Comment Google gère-t-il réellement les codes de statut HTTP lors du crawl ?
- □ Pourquoi Google extrait-il les balises meta robots et canonical pendant l'indexation plutôt qu'au crawl ?
- □ Pourquoi un noindex sur une page hreflang peut-il contaminer tout votre cluster international ?
- □ Faut-il vraiment compter sur JavaScript pour gérer le noindex ?
- □ Comment désindexer un PDF ou un fichier binaire avec l'en-tête X-Robots-Tag ?
- □ La directive unavailable_after ralentit-elle vraiment le crawling de Google ?
- □ Faut-il désactiver le cache Google pour maîtriser l'affichage de vos snippets ?
- □ Peut-on vraiment forcer Google à rafraîchir un snippet sans être propriétaire du site ?
- □ L'outil de suppression de Google supprime-t-il vraiment vos URLs de l'index ?
- □ L'outil de suppression Google bloque-t-il réellement le crawl des pages ?
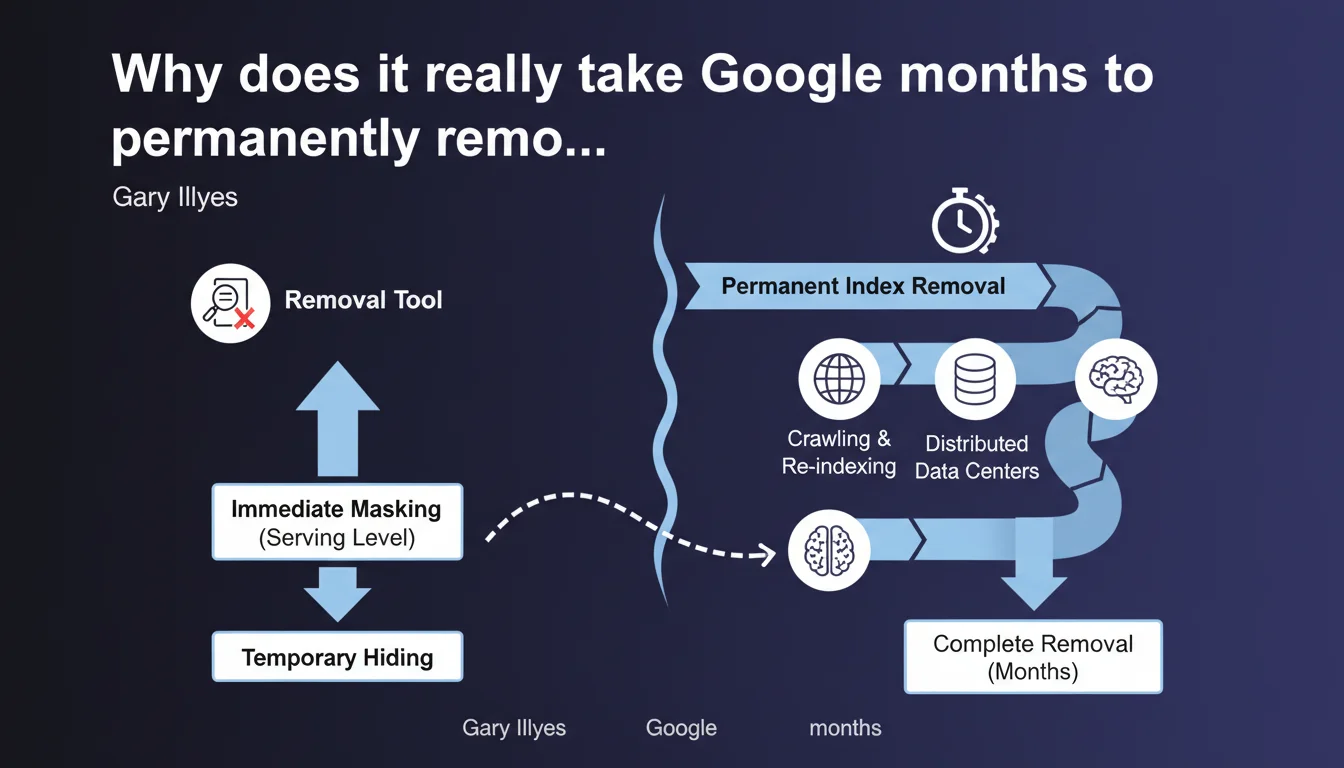
Google distinguishes between two removal levels: immediate masking at the serving level (what you see in search results) and permanent removal from the actual index, which can take several months. The URL removal tool works instantly on the first level, but doesn't accelerate the second. This technical distinction explains why URLs can temporarily reappear or continue consuming crawl budget long after their apparent removal.
What you need to understand
What's the real difference between masking and actual removal?
Google operates on two distinct layers: the serving index (what feeds the SERPs) and deep storage index. When you use the URL removal tool in Search Console, you trigger immediate masking at the serving level — the page disappears from results within minutes.
But that page remains physically stored in Google's infrastructure. Its permanent removal from the actual index follows a separate and much slower process, potentially stretching across several months depending on the situation.
Why does this time gap actually exist?
Google's distributed architecture relies on multiple datacenters spread geographically worldwide. A removed URL must be progressively deleted from each node, each copy, each caching system.
Google doesn't immediately reallocate resources — it waits for natural recrawl cycles to confirm deletion, for link signals to dissipate, for historical data to be archived. It's a matter of system consistency more than speed.
When does removal actually take the longest?
- Pages with a significant backlink history — Google keeps traces to detect manipulation
- URLs present in multiple index versions (mobile, desktop, geolocation-specific)
- Sites with high crawl budget — paradoxically, large sites can experience longer delays because propagation affects more systems
- Pages removed without clean 410 status code (404, temporary redirects) that trigger repeated checks
- Content archived in secondary indexes (Google Discover, Google News, image search)
SEO Expert opinion
Does this statement truly illuminate real-world practices we observe?
Yes and no. Gary Illyes confirms what many suspected: the removal tool is cosmetic. In practice, we regularly observe "removed" URLs temporarily reappearing in SERPs after a few weeks, or pages continuing to consume crawl budget months after their apparent removal.
What's missing here — and it's typical of Google — is granularity. "Several months" means what exactly? 3 months? 6 months? 12 months? This vagueness makes rigorous planning impossible during migrations or redesigns.
What are the real implications of this two-layer architecture for site migrations?
Let's be honest: if you're migrating a site and counting on rapid removal of old URLs to "clean up" the index, you're headed for serious trouble. Old pages will coexist with new ones for months.
Concretely? You risk duplicate content issues if your redirects aren't perfect, PageRank dilution if Google keeps massively crawling old URLs, and potentially cannibalization if both versions temporarily compete.
Is Google transparent about criteria that lengthen or shorten these delays?
No. And that's where the problem lies. Gary mentions "certain cases" without specifying which ones. [To verify]: Does crawl frequency influence actual removal speed? Does submitting a sitemap with 410 URLs accelerate the process?
We're still largely flying blind. SEOs must therefore continue to test and document their own observations, because Google will probably never provide a precise mapping between technical context and removal timeline.
Practical impact and recommendations
What should you actually do when removing pages?
First rule: never rely on the URL removal tool for permanent deindexation. Use it only to temporarily mask sensitive content (exposed personal data, publishing errors) while implementing a permanent technical solution.
For lasting removal, the method remains unchanged: HTTP 410 Gone status code (preferable to 404 to signal permanent intent), maintained for at least 6 months. If the page has historical value, prioritize a 301 redirect to the most relevant content.
How do you anticipate crawl budget impact during the transition period?
During these "several months" of gradual purge, Google will keep checking removed URL status. On a site with tens of thousands of pages, this represents non-negligible crawl budget waste.
Mitigation strategy: block entire removed sections in robots.txt once the 410 code is live. This doesn't accelerate index removal, but it reduces unnecessary recrawl frequency. Monitor your server logs to confirm the gradual decline in Googlebot requests to these URLs.
Which signals should you monitor to track actual removal?
site:yourdomain.comquery filtered by affected URLs — imperfect but indicative method- Crawl volume in server logs on removed URL patterns (gradual decline expected)
- "Pages explored" report in Search Console — verify URL disappearance from the list
- Third-party index tracking tools (OnCrawl, Screaming Frog) to detect temporary reappearances
- Monitoring of backlinks pointing to these URLs — if Google keeps crawling them, it's often still following external links
Permanent removal of a page from Google's index is a long and opaque process. The URL removal tool is merely a visual cache with no effect on actual deindexation. For complex migrations or major site redesigns, this technical reality seriously complicates planning.
If you manage a site with thousands of pages, you're preparing a large-scale migration, or you need to orchestrate massive deindexation while preserving visibility, partnering with a specialized SEO agency can prove invaluable — if only to properly monitor signals during transition and adjust strategy in real time.
❓ Frequently Asked Questions
L'outil de suppression d'URL accélère-t-il la désindexation définitive ?
Combien de temps faut-il maintenir un code 410 sur une page supprimée ?
Pourquoi certaines URLs supprimées réapparaissent-elles temporairement dans les résultats ?
Bloquer les URLs supprimées dans le robots.txt accélère-t-il leur disparition de l'index ?
Quel code HTTP privilégier pour une suppression définitive : 404 ou 410 ?
🎥 From the same video 12
Other SEO insights extracted from this same Google Search Central video · published on 04/08/2022
🎥 Watch the full video on YouTube →
💬 Comments (0)
Be the first to comment.