Declaration officielle
Autres déclarations de cette vidéo 18 ▾
- □ Canonical seul ne suffit pas pour bloquer le contenu syndiqué dans Discover : faut-il vraiment ajouter noindex ?
- □ Deux domaines pour un même pays : où commence vraiment la manipulation ?
- □ Les failles JavaScript de vos bibliothèques font-elles chuter votre positionnement Google ?
- □ Peut-on vraiment empêcher Google de crawler certaines parties d'une page HTML ?
- □ Faut-il encore perdre du temps à soumettre son sitemap XML ?
- □ Pourquoi les données structurées Schema.org ne suffisent-elles pas toujours pour obtenir des résultats enrichis Google ?
- □ Les en-têtes HSTS ont-ils vraiment un impact sur votre référencement ?
- □ Google retraite-t-il vraiment votre sitemap à chaque crawl ?
- □ Sitemap HTML vs XML : pourquoi Google insiste-t-il sur leur différence de fonction ?
- □ Les données structurées avec erreurs sont-elles vraiment ignorées par Google ?
- □ Les chiffres dans vos URLs pénalisent-ils vraiment votre référencement ?
- □ L'index bloat existe-t-il vraiment chez Google ?
- □ Google délivre-t-il vraiment des certifications SEO officielles ?
- □ Plusieurs menus de navigation nuisent-ils vraiment au SEO ?
- □ Les host groups indiquent-ils vraiment une cannibalisation à corriger ?
- □ Peut-on désavouer des backlinks toxiques en ciblant leur adresse IP ?
- □ Faut-il supprimer la balise meta NOODP de vos sites Blogger ?
- □ Comment obtenir une vignette vidéo dans les SERP : qu'entend Google par « contenu principal » ?
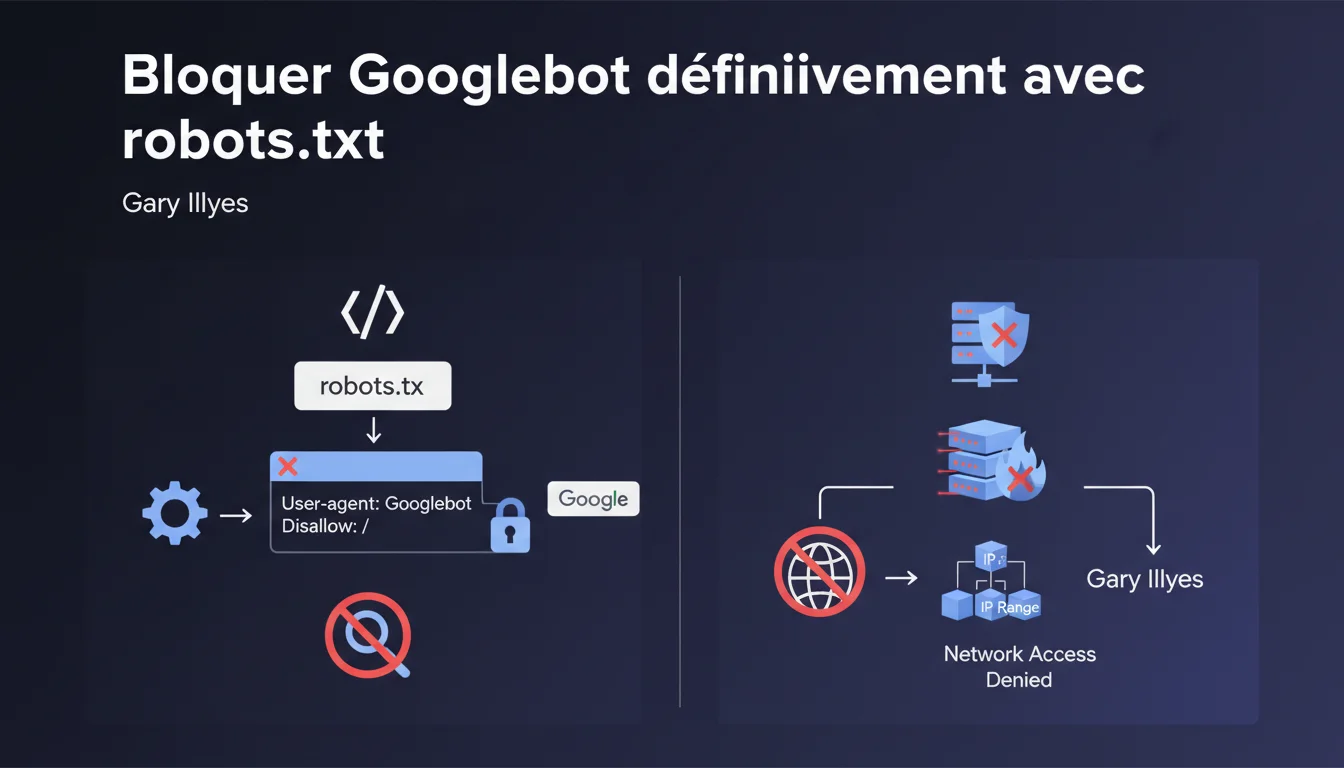
Google confirme deux méthodes pour bloquer Googlebot : une règle disallow / dans robots.txt pour empêcher l'exploration, ou des règles de pare-feu bloquant les plages IP officielles pour couper l'accès réseau complet. La première méthode stoppe le crawl, la seconde empêche toute connexion.
Ce qu'il faut comprendre
Quelle est la différence entre bloquer le crawl et bloquer l'accès réseau ?
Le robots.txt avec disallow / demande à Googlebot de ne pas explorer vos pages, mais le bot peut toujours techniquement accéder à votre serveur. Il respecte simplement la consigne de non-exploration.
Le blocage par pare-feu coupe l'accès au niveau infrastructure : les requêtes provenant des plages IP de Googlebot sont refusées avant même d'atteindre votre application. C'est un blocage dur, sans négociation possible.
Pourquoi Google propose-t-il deux approches distinctes ?
Parce que les besoins diffèrent selon le contexte. Un site qui souhaite sortir temporairement de l'index préférera robots.txt, facilement réversible. Un serveur confronté à des problèmes de charge ou de sécurité optera pour le pare-feu, plus radical.
Concrètement ? Si vous bloquez par robots.txt, vos URLs déjà indexées resteront visibles dans les résultats avec la mention « Aucune information disponible ». Avec un pare-feu, Google ne peut même pas vérifier le fichier robots.txt.
Où trouver les plages IP officielles de Googlebot ?
Google maintient une documentation de vérification listant les plages IP utilisées par ses crawlers. Ces plages évoluent, d'où l'importance de ne jamais coder en dur des IPs fixes dans vos règles de pare-feu.
La méthode recommandée consiste à utiliser des reverse DNS lookups pour vérifier que l'IP appartient bien à googlebot.com, puis confirmer avec un forward DNS lookup. Sinon, vous risquez de bloquer de faux Googlebots ou, pire, de laisser passer des crawlers malveillants se faisant passer pour Google.
- robots.txt disallow / = demande polie de non-exploration, Googlebot respecte mais peut techniquement accéder
- Blocage pare-feu = refus technique au niveau réseau, aucune requête n'atteint le serveur
- Les URLs déjà indexées restent visibles avec robots.txt, deviennent inaccessibles avec pare-feu
- Les plages IP Google changent : toujours vérifier via reverse/forward DNS
- Ne jamais bloquer par IP fixe sans vérification régulière
Avis d'un expert SEO
Cette déclaration est-elle complète pour tous les scénarios ?
Non, et c'est là que ça coince. Gary Illyes présente deux méthodes sans préciser leurs implications sur la désindexation. Bloquer le crawl via robots.txt n'empêche pas Google de garder vos URLs en index avec des métadonnées obsolètes.
Pour une désindexation propre, il faut combiner robots.txt avec des codes 410 Gone ou utiliser la Search Console. Le pare-feu, lui, provoque des erreurs serveur qui peuvent maintenir les URLs en index pendant des semaines avant que Google ne les retire. [A vérifier] : le délai exact de purge après blocage IP reste flou dans la documentation officielle.
Quels risques avec un blocage par pare-feu mal configuré ?
Le premier piège : bloquer par erreur les autres crawlers Google (Google-InspectionTool, AdsBot, etc.) qui utilisent des plages IP différentes. Si vous ne bloquez que googlebot.com, vous laissez passer des dizaines d'autres user-agents Google.
Le second : les faux positifs. Certains proxies, VPNs ou CDNs peuvent temporairement partager des plages IP proches de celles de Google. Un blocage trop large coupe l'accès à des utilisateurs légitimes.
Dans quel cas éviter ces méthodes de blocage ?
Si votre objectif est de désindexer proprement des pages, robots.txt + noindex meta tag reste supérieur. Google doit pouvoir crawler la page une dernière fois pour lire le noindex.
Le pare-feu est pertinent pour des environnements de staging, des sites victimes d'attaques par scraping agressif, ou des migrations où l'ancien domaine doit être coupé brutalement. Mais pour un site de production qui souhaite juste sortir temporairement de l'index ? C'est un marteau-piqueur pour planter un clou.
Impact pratique et recommandations
Comment implémenter un blocage robots.txt efficace ?
Ajoutez ces deux lignes au sommet de votre fichier robots.txt :
User-agent: Googlebot
Disallow: /
Vérifiez immédiatement dans Google Search Console avec l'outil de test robots.txt. Une syntaxe incorrecte (espace manquant, casse mal respectée) rend la directive inopérante.
Attention : cette règle ne bloque que Googlebot. Pour bloquer tous les crawlers Google (Google-InspectionTool, AdsBot-Google, Googlebot-Image, etc.), utilisez User-agent: *. Mais soyez conscient que ça bloque aussi Bing, Yandex, et tous les autres moteurs.
Quelle est la procédure pour un blocage par pare-feu ?
Récupérez d'abord la liste officielle des plages IP depuis la documentation Google (googlebot.com via DNS lookup). Configurez ensuite vos règles de pare-feu (iptables, AWS Security Groups, Cloudflare, etc.) pour refuser ces plages.
Testez avec un outil comme cURL en simulant une requête depuis une IP Googlebot. Si vous obtenez une erreur de connexion, le blocage fonctionne. Sinon, vérifiez que votre pare-feu est bien au niveau le plus proche du réseau (pas juste un .htaccess).
Programmez une vérification mensuelle des plages IP Google. Elles changent sans préavis, et un blocage obsolète laisse passer de nouveaux crawlers ou coupe l'accès à des services légitimes.
Quelles erreurs éviter absolument ?
- Ne jamais bloquer Googlebot sans d'abord supprimer les URLs de l'index via Search Console
- Ne pas confondre
User-agent: Googlebot(crawl web) etUser-agent: *(tous les bots) - Ne jamais coder en dur des IPs Google dans un pare-feu sans process de mise à jour
- Toujours tester le robots.txt avec l'outil GSC avant déploiement en production
- Prévoir une whitelist IP pour vos outils d'admin si vous bloquez au pare-feu
- Documenter la raison du blocage pour éviter qu'un collègue ne le retire par erreur
❓ Questions frequentes
Le blocage par robots.txt retire-t-il mes pages de l'index Google ?
Puis-je bloquer Googlebot tout en laissant passer Bing et les autres moteurs ?
Combien de temps après un blocage pare-feu mes pages disparaissent-elles de Google ?
Le blocage robots.txt affecte-t-il Google Search Console ?
Les plages IP de Googlebot changent-elles souvent ?
🎥 De la même vidéo 18
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 07/06/2023
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.