Declaration officielle
Autres déclarations de cette vidéo 18 ▾
- □ Canonical seul ne suffit pas pour bloquer le contenu syndiqué dans Discover : faut-il vraiment ajouter noindex ?
- □ Deux domaines pour un même pays : où commence vraiment la manipulation ?
- □ Les failles JavaScript de vos bibliothèques font-elles chuter votre positionnement Google ?
- □ Faut-il encore perdre du temps à soumettre son sitemap XML ?
- □ Pourquoi les données structurées Schema.org ne suffisent-elles pas toujours pour obtenir des résultats enrichis Google ?
- □ Les en-têtes HSTS ont-ils vraiment un impact sur votre référencement ?
- □ Google retraite-t-il vraiment votre sitemap à chaque crawl ?
- □ Sitemap HTML vs XML : pourquoi Google insiste-t-il sur leur différence de fonction ?
- □ Les données structurées avec erreurs sont-elles vraiment ignorées par Google ?
- □ Les chiffres dans vos URLs pénalisent-ils vraiment votre référencement ?
- □ L'index bloat existe-t-il vraiment chez Google ?
- □ Comment bloquer définitivement Googlebot de votre site ?
- □ Google délivre-t-il vraiment des certifications SEO officielles ?
- □ Plusieurs menus de navigation nuisent-ils vraiment au SEO ?
- □ Les host groups indiquent-ils vraiment une cannibalisation à corriger ?
- □ Peut-on désavouer des backlinks toxiques en ciblant leur adresse IP ?
- □ Faut-il supprimer la balise meta NOODP de vos sites Blogger ?
- □ Comment obtenir une vignette vidéo dans les SERP : qu'entend Google par « contenu principal » ?
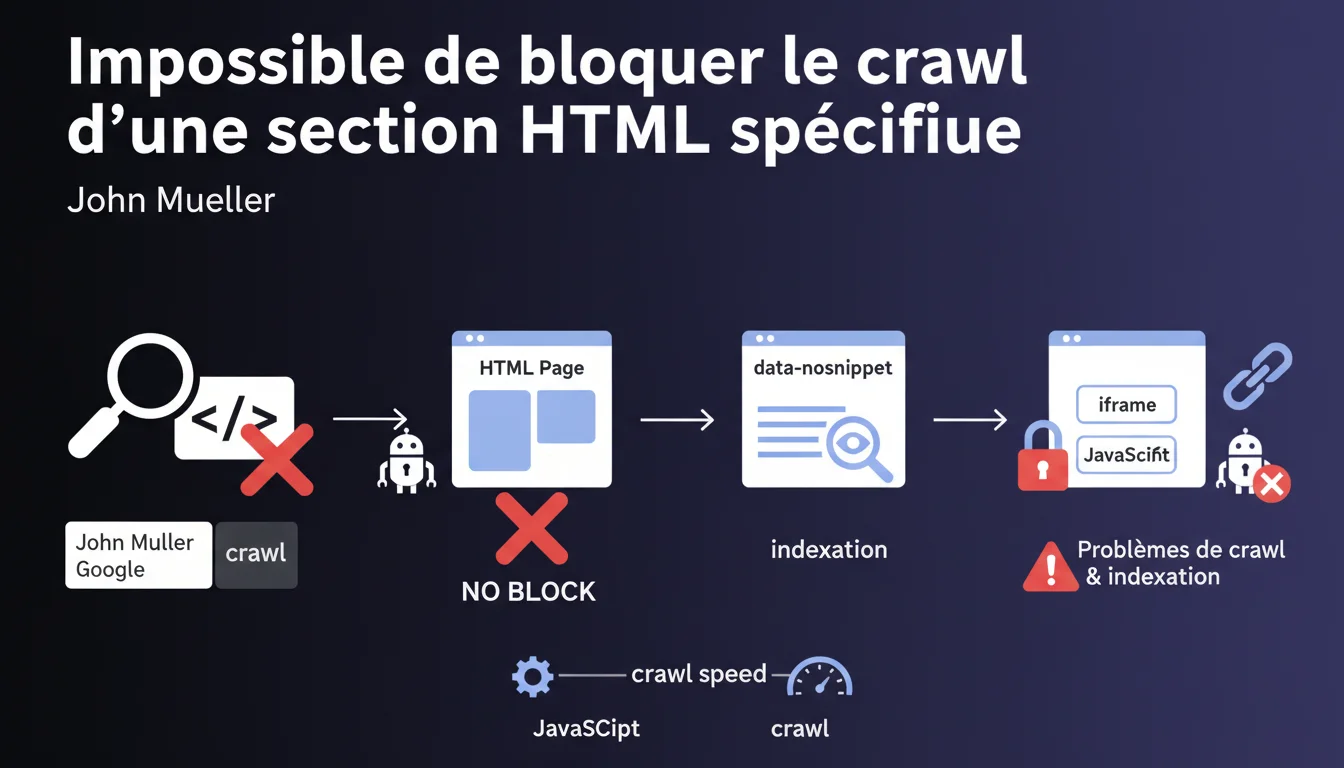
Google affirme qu'il est impossible de bloquer le crawl d'une section HTML spécifique d'une page. Les alternatives comme data-nosnippet ou l'usage d'iframe/JavaScript bloqués par robots.txt existent, mais cette dernière méthode risque de compromettre le crawl et l'indexation.
Ce qu'il faut comprendre
La déclaration de Mueller répond à une question fréquente : comment masquer sélectivement du contenu au robot sans impacter la visibilité globale de la page ? La réponse est sans appel — techniquement, c'est impossible.
Pourquoi cette limitation technique existe-t-elle ?
Googlebot traite une page HTML comme un document unique. Il n'existe aucune directive standard permettant de dire « crawle tout sauf cette <div> ». Les robots.txt fonctionnent au niveau de l'URL, pas au niveau d'un fragment de code.
Les méthodes alternatives mentionnées ne bloquent pas réellement le crawl. L'attribut data-nosnippet empêche l'affichage dans les extraits de résultats, mais le contenu est bien crawlé et peut influencer le classement. Quant aux iframe ou scripts bloqués par robots.txt, ils créent des zones opaques qui perturbent la compréhension de la page par Google.
Quelles sont les conséquences d'un blocage via robots.txt ?
Bloquer JavaScript ou iframe via robots.txt introduit des angles morts dans l'analyse de votre page. Google ne peut pas évaluer si ces ressources contiennent du contenu essentiel, des liens internes, ou des éléments impactant l'UX.
Résultat : vous risquez une indexation partielle, voire une dévaluation si Google soupçonne que des informations critiques lui sont cachées. C'est un pari risqué, rarement justifié.
- Aucune directive HTML ne permet de bloquer le crawl d'une section précise
- L'attribut data-nosnippet masque du texte dans les snippets, sans bloquer le crawl
- Bloquer iframe/JS par robots.txt peut nuire à l'indexation globale de la page
- Le crawl fonctionne au niveau de l'URL, pas au niveau d'un élément DOM
Avis d'un expert SEO
Cette déclaration correspond-elle aux observations terrain ?
Absolument. En 15 ans de pratique, je n'ai jamais vu de méthode fiable pour bloquer sélectivement le crawl d'une section sans effet de bord. Les tentatives via obfuscation JavaScript ou lazy-loading agressif créent plus de problèmes qu'elles n'en résolvent.
La confusion vient souvent d'une mauvaise compréhension des objectifs. Si vous voulez masquer du contenu aux utilisateurs tout en le gardant crawlable (pour le SEO), c'est une chose. Si vous voulez le cacher à Google, c'est une autre — et la seconde est quasi impossible à faire proprement.
Quand cette limitation pose-t-elle vraiment problème ?
Franchement ? Rarement. Les cas d'usage légitimes sont limités. Vous voulez peut-être éviter que du contenu dupliqué interne (filtres, facettes) soit crawlé — mais alors, le vrai sujet c'est la gestion des paramètres d'URL et le canonical, pas le blocage d'une <section>.
Les sites e-commerce avec des widgets tiers (avis, chat) s'inquiètent parfois de leur impact. [A vérifier] : Google prétend ignorer le contenu non-pertinent, mais personne n'a de visibilité réelle sur ce tri. Si un bloc tiers pollue vraiment votre sémantique, mieux vaut le charger en différé après le rendu initial — pas le bloquer via robots.txt.
Existe-t-il des contournements viables ?
Techniquement, oui. Charger du contenu en Ajax après le crawl initial, utiliser des attributs loading="lazy" combinés à du rendu conditionnel... Mais ces gymnastiques fragilisent votre architecture et créent des décalages entre ce que voit Google et ce que voit l'utilisateur.
Impact pratique et recommandations
Que faire si vous voulez vraiment masquer du contenu à Google ?
Première question : pourquoi voulez-vous le faire ? Si c'est pour éviter du contenu dupliqué, utilisez noindex sur les pages concernées ou travaillez vos canoniques. Si c'est pour cacher du spam ou du keyword stuffing... arrêtez ça immédiatement.
Si le besoin est légitime (données sensibles, contenu réservé), la bonne approche est de placer ce contenu derrière un login obligatoire ou de le servir en PDF bloqué par robots.txt. Mais soyons honnêtes — ces cas sont marginaux.
Comment utiliser data-nosnippet efficacement ?
L'attribut data-nosnippet (ou sa version balise <span class="nosnippet">) empêche l'affichage dans les extraits enrichis, les featured snippets et les réponses rapides. Le contenu reste crawlé et indexé, mais invisible dans les SERP.
Cas d'usage concret : masquer des mentions légales, des CGV, des informations de contact que vous ne voulez pas voir apparaître dans les snippets. Utile, mais aucun impact sur le crawl lui-même.
- Acceptez que le crawl partiel d'une page HTML n'est pas possible sans risque
- Utilisez
data-nosnippetuniquement pour contrôler l'affichage dans les résultats, pas le crawl - Évitez de bloquer JavaScript ou iframe par robots.txt sauf cas très spécifiques et maîtrisés
- Pour du contenu sensible, privilégiez l'authentification ou le noindex au niveau de la page
- Testez systématiquement l'impact avec l'outil Inspection d'URL de la Search Console
- Ne cherchez pas à manipuler ce que voit Googlebot — la cohérence utilisateur/bot est clé
La gestion fine du crawl au niveau des éléments HTML demande une expertise technique solide et une compréhension approfondie des mécanismes de Googlebot. Les erreurs de configuration peuvent impacter lourdement votre visibilité organique. Si vous hésitez sur l'architecture de crawl de votre site ou si vous gérez des contenus complexes (facettes, filtres, widgets tiers), un audit mené par une agence SEO spécialisée vous permettra d'identifier les zones à risque et de mettre en place des solutions pérennes, adaptées à votre contexte métier.
❓ Questions frequentes
L'attribut data-nosnippet empêche-t-il Googlebot de crawler le contenu ?
Puis-je bloquer une iframe tierce pour éviter qu'elle pollue mon crawl budget ?
Existe-t-il une balise HTML pour dire à Google de ne pas crawler une div spécifique ?
Si je charge du contenu en Ajax après le rendu initial, Google le verra-t-il ?
Le lazy-loading d'images ou de sections peut-il bloquer leur crawl ?
🎥 De la même vidéo 18
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 07/06/2023
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.