Declaration officielle
Autres déclarations de cette vidéo 18 ▾
- □ Deux domaines pour un même pays : où commence vraiment la manipulation ?
- □ Les failles JavaScript de vos bibliothèques font-elles chuter votre positionnement Google ?
- □ Peut-on vraiment empêcher Google de crawler certaines parties d'une page HTML ?
- □ Faut-il encore perdre du temps à soumettre son sitemap XML ?
- □ Pourquoi les données structurées Schema.org ne suffisent-elles pas toujours pour obtenir des résultats enrichis Google ?
- □ Les en-têtes HSTS ont-ils vraiment un impact sur votre référencement ?
- □ Google retraite-t-il vraiment votre sitemap à chaque crawl ?
- □ Sitemap HTML vs XML : pourquoi Google insiste-t-il sur leur différence de fonction ?
- □ Les données structurées avec erreurs sont-elles vraiment ignorées par Google ?
- □ Les chiffres dans vos URLs pénalisent-ils vraiment votre référencement ?
- □ L'index bloat existe-t-il vraiment chez Google ?
- □ Comment bloquer définitivement Googlebot de votre site ?
- □ Google délivre-t-il vraiment des certifications SEO officielles ?
- □ Plusieurs menus de navigation nuisent-ils vraiment au SEO ?
- □ Les host groups indiquent-ils vraiment une cannibalisation à corriger ?
- □ Peut-on désavouer des backlinks toxiques en ciblant leur adresse IP ?
- □ Faut-il supprimer la balise meta NOODP de vos sites Blogger ?
- □ Comment obtenir une vignette vidéo dans les SERP : qu'entend Google par « contenu principal » ?
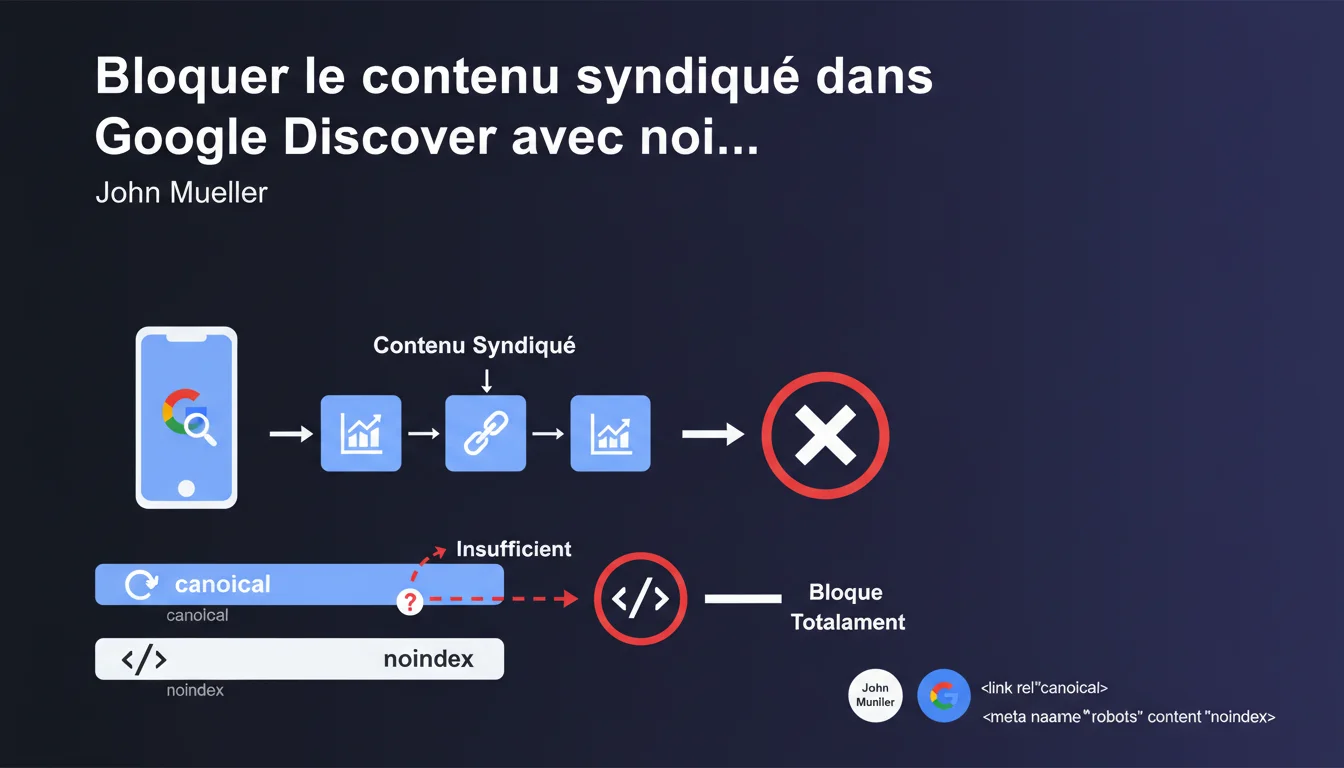
Le canonical seul ne garantit pas l'exclusion du contenu syndiqué de Google Discover. Google recommande d'ajouter une balise meta robots noindex sur les versions syndiquées pour bloquer totalement leur apparition. Une consigne qui bouscule l'usage traditionnel du canonical comme signal de déduplication.
Ce qu'il faut comprendre
Pourquoi le canonical ne suffit-il plus pour Discover ?
Le lien canonical a toujours été présenté comme l'outil privilégié pour indiquer à Google quelle version d'un contenu dupliqué privilégier. Dans la logique classique du référencement, un canonical bien implémenté devrait suffire à consolider les signaux vers la version originale.
Sauf que Google Discover fonctionne différemment. Le flux ne se contente pas de crawler et d'indexer : il sélectionne des contenus pour les pousser de manière proactive aux utilisateurs. Dans ce contexte, le canonical reste un signal indicatif — Google peut choisir de l'ignorer si d'autres critères (fraîcheur perçue, domaine de confiance du syndicateur, engagement anticipé) pointent vers la version syndiquée.
Que signifie concrètement cette déclaration de Mueller ?
Mueller recommande d'ajouter une balise meta robots noindex sur les versions syndiquées si vous voulez garantir leur exclusion de Discover. Le noindex transforme un signal faible (canonical) en directive stricte : la page ne doit pas apparaître dans les résultats, Discover inclus.
C'est un changement de paradigme. Jusqu'ici, on utilisait le canonical pour dire « cette page existe ailleurs en mieux ». Maintenant, pour Discover, il faut dire « cette page ne doit pas être montrée du tout ». La nuance est importante.
Quels sont les risques si on ignore cette recommandation ?
Sans noindex, vos versions syndiquées peuvent apparaître dans Discover à la place de l'original. Résultat : vous perdez le trafic qualifié, les signaux d'engagement (clics, temps passé) et potentiellement la visibilité que vous auriez dû capter sur votre propre domaine.
Pire encore, si le syndicateur est un gros site d'actualités avec une forte autorité, Google peut privilégier sa version — même si le canonical pointe vers vous. C'est exactement le scénario que cette directive vise à éviter.
- Le canonical seul est un signal indicatif, pas une directive absolue pour Discover
- Le noindex bloque totalement l'apparition du contenu syndiqué dans Discover
- Sans noindex, les versions syndiquées peuvent supplanter l'original dans le flux
- Cette recommandation s'applique spécifiquement à Discover, pas nécessairement à la recherche classique
Avis d'un expert SEO
Cette consigne est-elle cohérente avec les observations terrain ?
Oui et non. On observe effectivement des cas où des versions syndiquées apparaissent dans Discover malgré un canonical bien implémenté. Cela confirme que Google traite Discover avec ses propres règles — et que le canonical n'y a pas le poids absolu qu'on lui prête ailleurs.
En revanche, recommander un noindex pour du contenu syndiqué pose un problème évident : un noindex strict empêche toute indexation, pas seulement l'apparition dans Discover. Si le syndicateur souhaite que son contenu reste dans la recherche classique (avec canonical vers l'original), cette directive devient inapplicable. [A vérifier] : Mueller ne précise pas si Google envisage un mécanisme plus fin (type data-nosnippet ou X-Robots-Tag conditionnel) pour cibler Discover uniquement.
Dans quels cas cette règle ne s'applique-t-elle pas ?
Si vous êtes l'éditeur original et que vous souhaitez que vos partenaires syndicateurs indexent le contenu tout en pointant vers vous via canonical, le noindex n'est pas une option. Vous perdriez la distribution de liens, les signaux de marque et la portée élargie que la syndication peut offrir.
La directive de Mueller s'adresse plutôt aux situations où vous contrôlez les deux versions (original + syndiqué) ou lorsque vous avez un accord avec le syndicateur pour bloquer complètement sa version de Discover. Dans les autres cas, vous êtes face à un arbitrage entre visibilité Discover et bénéfices SEO classiques de la syndication.
Quelle alternative si on veut garder le contenu syndiqué indexable ?
Franchement, Google ne propose pas de solution propre pour ce cas. Le data-nosnippet empêche les extraits enrichis, mais n'affecte pas Discover. Le X-Robots-Tag avec des conditions serveur pourrait théoriquement cibler Discover, mais rien n'est documenté officiellement.
En pratique, vous êtes coincé : soit vous acceptez que le syndiqué apparaisse parfois dans Discover (et vous perdez du trafic), soit vous le bloquez totalement avec noindex (et vous perdez les bénéfices SEO de la syndication). [A verifier] : il serait utile que Google clarifie s'il existe un moyen de cibler Discover sans impacter l'indexation classique.
Impact pratique et recommandations
Que faut-il faire concrètement si vous syndiquez votre contenu ?
Si vous contrôlez les versions syndiquées (par exemple, republication sur un site partenaire ou une plateforme tierce), ajoutez meta name="robots" content="noindex, follow" dans le de la version syndiquée. Le follow permet de conserver le jus SEO du canonical, même si la page n'est pas indexée.
Si vous ne contrôlez pas directement le syndicateur, intégrez cette clause dans vos contrats de syndication : exigez que le partenaire applique noindex sur sa version pour préserver votre visibilité Discover. C'est une négociation à mener en amont.
Comment vérifier que votre implémentation est correcte ?
Utilisez l'outil d'inspection d'URL de la Search Console sur les versions syndiquées. Vérifiez que Google détecte bien le noindex et que la page n'est pas indexée. Parallèlement, contrôlez que le canonical pointe vers l'original.
Surveillez vos apparitions dans Discover via le rapport Discover de la Search Console. Si des URLs syndiquées continuent d'apparaître malgré le noindex, il y a un problème d'implémentation ou un délai de traitement côté Google.
Quelles erreurs éviter absolument ?
Ne mettez jamais de noindex sur l'original — cela semble évident, mais des erreurs de déploiement arrivent plus souvent qu'on ne le croit. Un template mal configuré ou un CMS qui applique la directive au mauvais niveau peut vous faire perdre toute visibilité.
Évitez aussi de combiner noindex et canonical de manière contradictoire. Si une page est en noindex, le canonical n'a plus vraiment de sens du point de vue de l'indexation — même si techniquement Google peut encore suivre le lien. Clarifiez votre intention : soit vous déduplication (canonical seul), soit vous bloquez (noindex).
- Ajouter meta robots noindex sur toutes les versions syndiquées destinées à être exclues de Discover
- Conserver le canonical vers l'original même avec noindex, pour préserver les signaux de consolidation
- Vérifier l'implémentation via l'outil d'inspection d'URL de la Search Console
- Intégrer cette clause dans les contrats de syndication si vous ne contrôlez pas directement le partenaire
- Surveiller le rapport Discover pour détecter d'éventuelles apparitions non désirées
- Documenter clairement quelle version doit être indexée et laquelle doit être bloquée
❓ Questions frequentes
Le noindex sur une version syndiquée empêche-t-il aussi son indexation dans la recherche classique ?
Peut-on utiliser le robots.txt pour bloquer uniquement Discover ?
Si le syndicateur refuse d'ajouter noindex, quelles options reste-t-il ?
Le noindex affecte-t-il le transfert de jus SEO via le canonical ?
Cette recommandation s'applique-t-elle aussi aux agrégateurs de flux RSS ?
🎥 De la même vidéo 18
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 07/06/2023
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.