Declaration officielle
Autres déclarations de cette vidéo 18 ▾
- □ Canonical seul ne suffit pas pour bloquer le contenu syndiqué dans Discover : faut-il vraiment ajouter noindex ?
- □ Deux domaines pour un même pays : où commence vraiment la manipulation ?
- □ Les failles JavaScript de vos bibliothèques font-elles chuter votre positionnement Google ?
- □ Peut-on vraiment empêcher Google de crawler certaines parties d'une page HTML ?
- □ Faut-il encore perdre du temps à soumettre son sitemap XML ?
- □ Pourquoi les données structurées Schema.org ne suffisent-elles pas toujours pour obtenir des résultats enrichis Google ?
- □ Les en-têtes HSTS ont-ils vraiment un impact sur votre référencement ?
- □ Google retraite-t-il vraiment votre sitemap à chaque crawl ?
- □ Sitemap HTML vs XML : pourquoi Google insiste-t-il sur leur différence de fonction ?
- □ Les chiffres dans vos URLs pénalisent-ils vraiment votre référencement ?
- □ L'index bloat existe-t-il vraiment chez Google ?
- □ Comment bloquer définitivement Googlebot de votre site ?
- □ Google délivre-t-il vraiment des certifications SEO officielles ?
- □ Plusieurs menus de navigation nuisent-ils vraiment au SEO ?
- □ Les host groups indiquent-ils vraiment une cannibalisation à corriger ?
- □ Peut-on désavouer des backlinks toxiques en ciblant leur adresse IP ?
- □ Faut-il supprimer la balise meta NOODP de vos sites Blogger ?
- □ Comment obtenir une vignette vidéo dans les SERP : qu'entend Google par « contenu principal » ?
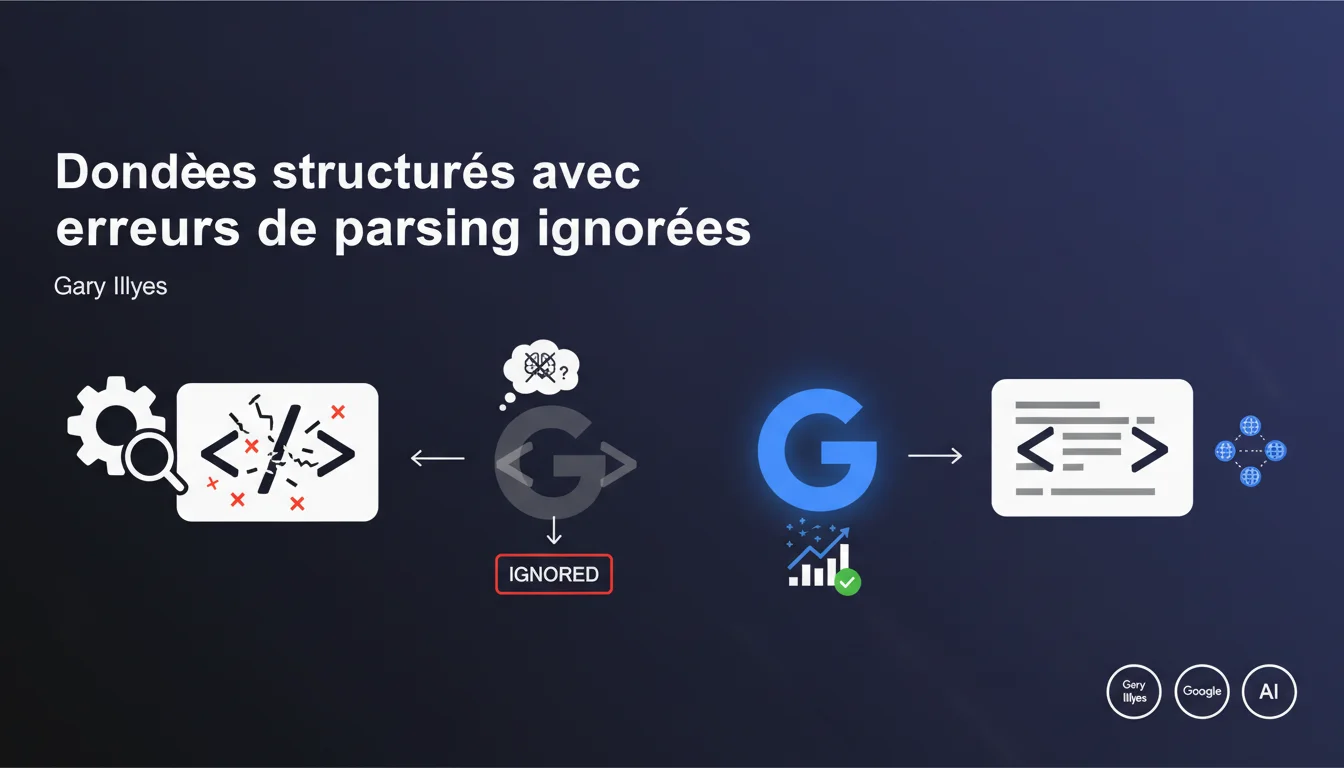
Google ignore complètement les données structurées qui contiennent des erreurs de parsing — pas de traitement partiel, pas de récupération gracieuse. Si votre balisage Schema.org est mal formé, il n'existe tout simplement pas aux yeux du moteur. C'est un signal binaire : ça passe ou ça casse.
Ce qu'il faut comprendre
Que signifie concrètement une « erreur de parsing » ?
Une erreur de parsing, c'est quand Google ne parvient pas à lire correctement la structure JSON-LD, Microdata ou RDFa que vous avez implémentée. Virgule manquante, guillemet mal fermé, propriété Schema.org mal orthographiée, type incompatible — tout ce qui empêche le parseur de construire un objet valide.
Contrairement à ce que certains espèrent, Google ne fait pas de « réparation automatique ». Le parseur n'est pas votre IDE : il ne devine pas votre intention. Si le JSON est cassé, l'intégralité du bloc de données structurées est ignorée, même si 95% du contenu est correct.
Pourquoi Google adopte-t-il une posture aussi stricte ?
Parce que l'ambiguïté coûte cher en ressources de crawl et en fiabilité des rich snippets. Imaginez que Google tente de « réparer » vos erreurs : il devrait alors interpréter vos intentions, ce qui ouvrirait la porte à des résultats imprévisibles et non reproductibles.
En exigeant un balisage strictement valide, Google garantit que les données qu'il affiche dans les SERP (prix, avis, disponibilité) reflètent exactement ce que le webmaster a déclaré — sans approximation ni hallucination algorithmique.
Qu'est-ce qui différencie cette approche d'autres moteurs ou crawlers ?
Certains crawlers sont plus permissifs et tentent une récupération partielle. Bing, par exemple, peut parfois extraire des fragments de données structurées même en présence d'erreurs mineures. Google, lui, a clairement choisi la voie du tout ou rien.
Cette déclaration de Gary Illyes vient lever toute ambiguïté : pas de zone grise, pas de traitement dégradé. Si la Search Console signale une erreur de parsing, votre balisage est invisible pour les algorithmes de Google.
- Les erreurs de parsing rendent l'intégralité du bloc de données structurées invisible pour Google
- Aucun traitement partiel ou récupération automatique n'est effectué
- La validation stricte garantit la fiabilité des rich snippets affichés dans les SERP
- Google adopte une approche binaire : valide ou ignoré, sans zone grise
- La Search Console est l'outil de référence pour détecter ces erreurs
Avis d'un expert SEO
Cette déclaration est-elle cohérente avec les observations terrain ?
Oui, et c'est d'ailleurs l'une des rares déclarations Google qui correspond exactement à ce qu'on observe. Sur des milliers d'audits, je n'ai jamais vu Google exploiter des données structurées avec erreurs de parsing signalées dans la Search Console. Le comportement est systématique et reproductible.
En revanche — et c'est là que ça devient intéressant — Google fait parfois preuve d'une tolérance surprenante sur des erreurs sémantiques (propriétés mal utilisées, types approximatifs) qui ne cassent pas le parsing. Ça passe, mais le rich snippet peut ne pas s'afficher comme prévu. [A vérifier] : la frontière entre « erreur de parsing » et « erreur sémantique » reste floue dans la documentation officielle.
Quelles nuances faut-il apporter à cette règle absolue ?
Premier point : cette règle s'applique au niveau du bloc de données structurées, pas nécessairement à toute la page. Si vous avez trois scripts JSON-LD sur une page et qu'un seul contient une erreur, les deux autres peuvent être exploités normalement. C'est une isolation granulaire que beaucoup ignorent.
Deuxième nuance : Google peut quand même indexer et classer votre page normalement, même si vos données structurées sont ignorées. Vous perdez les rich snippets, les étoiles, les prix affichés — mais pas votre positionnement organique de base. Le dommage est principalement sur le taux de clic, pas sur le ranking direct.
Dans quels cas cette règle peut-elle poser un problème insoupçonné ?
Les sites e-commerce multi-langues avec génération dynamique de Schema.org sont particulièrement exposés. Une variable mal échappée dans une seule langue peut casser le JSON-LD pour toutes les fiches produits de cette locale. Et comme le parsing échoue, zéro rich snippet ne remonte, même si 99% du catalogue est techniquement correct.
Autre cas vicieux : les caractères spéciaux dans les avis clients ou descriptions de produits. Un guillemet simple non échappé dans un témoignage dynamique suffit à invalider tout le bloc Product. Vous pouvez avoir un schéma parfait en théorie, et un chaos en production à cause d'un input utilisateur mal sanitisé.
Impact pratique et recommandations
Que faut-il faire concrètement pour éviter ces erreurs ?
Première ligne de défense : valider systématiquement vos données structurées avec le Rich Results Test de Google et le validateur Schema.org avant toute mise en production. Ces outils détectent la majorité des erreurs de syntaxe JSON et de structure.
Ensuite, automatisez la surveillance. Configurez des alertes dans la Search Console pour être notifié dès qu'une erreur de parsing apparaît sur un type de balisage critique (Product, Article, FAQ). Ne comptez pas sur une vérification manuelle hebdomadaire — les erreurs peuvent surgir après un déploiement ou une mise à jour de plugin.
- Valider tout nouveau balisage avec le Rich Results Test avant déploiement
- Configurer des alertes Search Console sur les erreurs de données structurées
- Auditer les pages à fort trafic au moins mensuellement
- Échapper correctement les caractères spéciaux dans les contenus dynamiques
- Tester les données structurées après chaque mise à jour de CMS ou plugin
- Isoler les blocs JSON-LD pour limiter l'impact d'une erreur à un seul type de markup
- Maintenir un environnement de staging pour tester les modifications de schéma
Quelles erreurs critiques méritent une attention immédiate ?
Les erreurs de syntaxe JSON (virgules, guillemets, accolades) doivent être corrigées en priorité absolue — elles cassent tout le bloc. Les propriétés manquantes obligatoires (comme @type, name, ou image selon le schéma) viennent juste après.
Les erreurs sémantiques (mauvais type de propriété, valeur hors format attendu) sont moins binaires, mais peuvent quand même empêcher l'affichage du rich snippet. Google ne les qualifie pas toujours d'« erreurs de parsing », mais le résultat pratique est identique : pas de snippet enrichi.
Comment vérifier que mon site est conforme et protégé ?
Mettez en place un monitoring continu avec un outil comme OnCrawl, Screaming Frog ou Sitebulb qui parse vos données structurées à chaque crawl. Comparez les rapports mensuels pour détecter toute régression.
Pour les sites de plus de 10 000 pages, envisagez un script automatisé qui teste un échantillon représentatif via l'API Rich Results Test. Vous identifierez ainsi les patterns d'erreurs (templates défectueux, catégories problématiques) sans inspecter manuellement chaque URL.
Les données structurées avec erreurs de parsing sont totalement invisibles pour Google — aucune exception, aucune tolérance. La prévention passe par une validation systématique avant déploiement et une surveillance continue en production.
Sachant que la complexité des implémentations Schema.org augmente avec les rich snippets éligibles (Product, Recipe, FAQ, HowTo, Video...), et que chaque erreur peut coûter des dizaines de points de CTR, il devient stratégique de s'appuyer sur une expertise spécialisée. Faire appel à une agence SEO qui maîtrise ces balisages techniques permet de sécuriser l'implémentation, d'automatiser les contrôles et de réagir rapidement aux alertes — souvent bien plus efficacement qu'une gestion interne fragmentée.
❓ Questions frequentes
Une erreur de parsing sur un bloc JSON-LD affecte-t-elle les autres blocs de la même page ?
Mes données structurées invalides peuvent-elles nuire à mon classement organique ?
Comment savoir si Google a détecté une erreur de parsing sur mes pages ?
Les erreurs sémantiques (propriété mal utilisée) sont-elles considérées comme des erreurs de parsing ?
Faut-il supprimer complètement un balisage défectueux ou peut-on le laisser en attendant de le corriger ?
🎥 De la même vidéo 18
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 07/06/2023
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.