Declaration officielle
Autres déclarations de cette vidéo 18 ▾
- □ Canonical seul ne suffit pas pour bloquer le contenu syndiqué dans Discover : faut-il vraiment ajouter noindex ?
- □ Deux domaines pour un même pays : où commence vraiment la manipulation ?
- □ Les failles JavaScript de vos bibliothèques font-elles chuter votre positionnement Google ?
- □ Peut-on vraiment empêcher Google de crawler certaines parties d'une page HTML ?
- □ Pourquoi les données structurées Schema.org ne suffisent-elles pas toujours pour obtenir des résultats enrichis Google ?
- □ Les en-têtes HSTS ont-ils vraiment un impact sur votre référencement ?
- □ Google retraite-t-il vraiment votre sitemap à chaque crawl ?
- □ Sitemap HTML vs XML : pourquoi Google insiste-t-il sur leur différence de fonction ?
- □ Les données structurées avec erreurs sont-elles vraiment ignorées par Google ?
- □ Les chiffres dans vos URLs pénalisent-ils vraiment votre référencement ?
- □ L'index bloat existe-t-il vraiment chez Google ?
- □ Comment bloquer définitivement Googlebot de votre site ?
- □ Google délivre-t-il vraiment des certifications SEO officielles ?
- □ Plusieurs menus de navigation nuisent-ils vraiment au SEO ?
- □ Les host groups indiquent-ils vraiment une cannibalisation à corriger ?
- □ Peut-on désavouer des backlinks toxiques en ciblant leur adresse IP ?
- □ Faut-il supprimer la balise meta NOODP de vos sites Blogger ?
- □ Comment obtenir une vignette vidéo dans les SERP : qu'entend Google par « contenu principal » ?
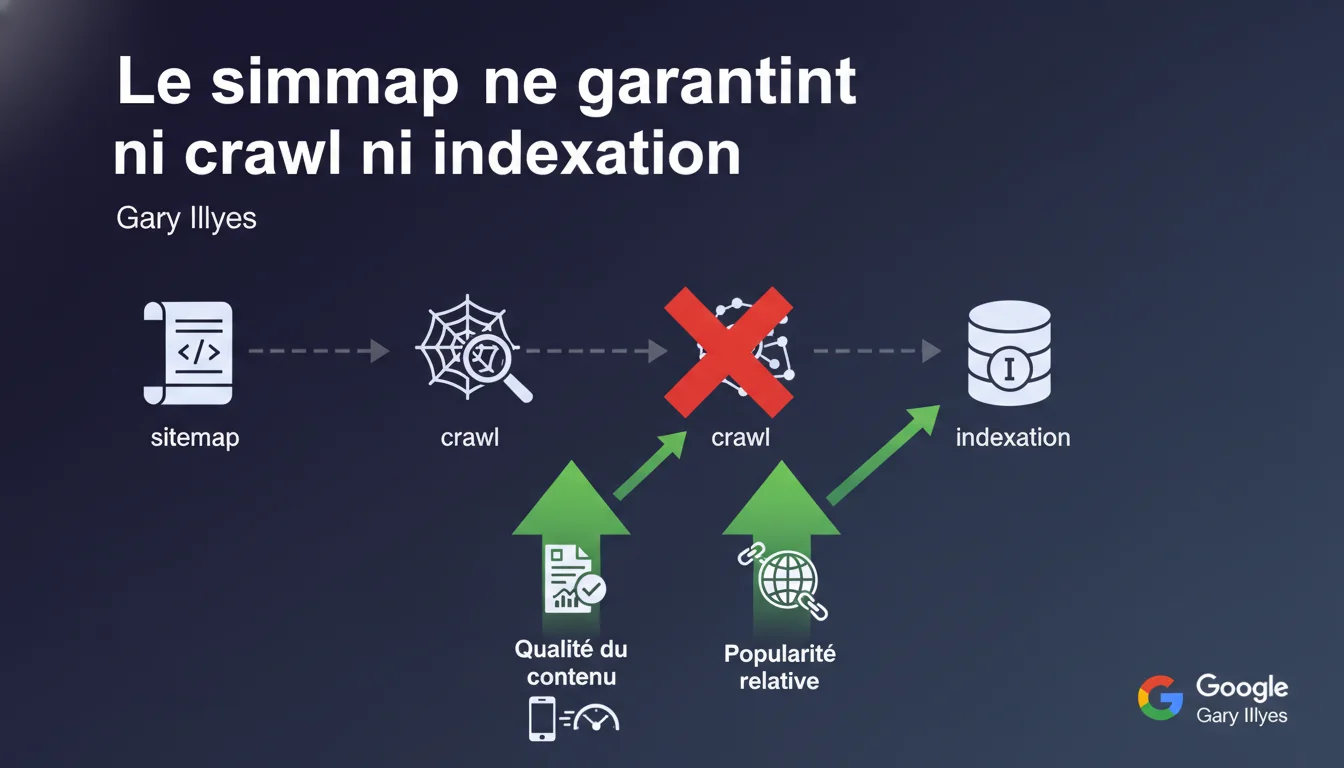
Soumettre un sitemap ne garantit strictement rien : ni crawl, ni indexation. Google décidera selon la qualité du contenu et sa popularité relative. Le sitemap n'est qu'une indication de localisation, pas un passe-droit.
Ce qu'il faut comprendre
Quel est le vrai rôle d'un sitemap si Google ne promet rien ?
Le sitemap XML sert avant tout de carte routière : il indique à Googlebot où trouver vos URLs, notamment celles enfouies dans l'arborescence ou mal maillées. Mais il ne force absolument pas le moteur à les crawler ou à les indexer.
Google utilise ce fichier comme donnée d'entrée parmi d'autres (logs internes, liens découverts, historique de crawl). Le sitemap ne contourne ni les quotas de crawl, ni les critères de qualité, ni les signaux de popularité. Il facilite la découverte — rien de plus.
Qu'est-ce qui détermine vraiment le crawl et l'indexation ?
Deux facteurs principaux : la qualité intrinsèque du contenu et sa popularité relative sur le web. Concrètement, Google évalue la pertinence, l'originalité, l'expertise, et compare votre page à ce qui existe déjà sur le même sujet.
La popularité — mesurée par les backlinks, les signaux d'engagement, l'autorité du domaine — joue aussi un rôle clé. Une URL orpheline, sans lien entrant, sans signal de qualité, peut rester dans le sitemap sans jamais être crawlée.
Le sitemap peut-il nuire si mal utilisé ?
Absolument. Soumettre des milliers d'URLs de faible qualité (contenus dupliqués, thin content, pages sans valeur) pollue le signal envoyé à Google. Le moteur peut interpréter cela comme un manque de discernement éditorial et réduire la fréquence de crawl globale du site.
Un sitemap bloaté génère du bruit. Mieux vaut un fichier de 200 URLs stratégiques qu'un fichier de 20 000 pages médiocres.
- Le sitemap ne garantit ni crawl ni indexation, seulement la découverte des URLs
- La qualité du contenu et la popularité relative déterminent la décision finale de Google
- Un sitemap mal conçu peut envoyer des signaux négatifs et nuire au crawl budget
- La soumission d'un sitemap reste utile pour accélérer la découverte, mais ne remplace pas un bon maillage interne
Avis d'un expert SEO
Cette déclaration contredit-elle les pratiques observées sur le terrain ?
Pas vraiment. Les SEO expérimentés savent depuis longtemps que le sitemap n'est pas magique. On observe régulièrement des URLs présentes dans le sitemap qui ne sont jamais crawlées — ou crawlées avec des mois de délai — si elles manquent de backlinks ou de profondeur éditoriale.
En revanche, Google reste flou sur les seuils de qualité et de popularité qui déclenchent réellement le crawl. Aucune métrique précise n'est communiquée. [À vérifier] : est-ce que la fraîcheur du contenu ou le taux de mise à jour influencent la priorité de crawl au-delà de la popularité ? Aucune donnée officielle.
Quelles nuances faut-il apporter à cette déclaration ?
Gary Illyes simplifie volontairement. Dans la pratique, certains types de sites bénéficient davantage du sitemap : les sites d'actualité (avec Google News XML), les plateformes e-commerce avec un catalogue renouvelé fréquemment, ou les sites avec une architecture profonde où le maillage interne est complexe.
Pour ces sites, le sitemap accélère effectivement la découverte — même si l'indexation finale reste conditionnée par la qualité. Il ne faut donc pas jeter le bébé avec l'eau du bain.
Dans quels cas cette règle s'applique-t-elle avec le plus de sévérité ?
Sur les sites de faible autorité ou les nouveaux domaines. Un site sans historique de crawl, sans backlinks, peut soumettre un sitemap de 10 000 URLs et n'en voir que quelques dizaines crawlées dans les premiers mois.
À l'inverse, un domaine établi avec une bonne autorité verra ses URLs découvertes et crawlées plus rapidement — avec ou sans sitemap. La popularité relative amplifie ou réduit l'effet du sitemap.
Impact pratique et recommandations
Que faut-il faire concrètement avec son sitemap ?
Adoptez une approche sélective : ne soumettez que les URLs de qualité, avec un contenu original et utile. Excluez les pages dupliquées, les thin content, les filtres de facettes sans valeur ajoutée, les archives inutiles.
Utilisez les balises <lastmod> et <priority> avec parcimonie — Google les ignore souvent, mais elles peuvent servir de signal secondaire. Mettez à jour le sitemap dès qu'une URL importante est ajoutée ou modifiée.
- Auditez votre sitemap actuel : retirez toutes les URLs de faible qualité ou sans objectif SEO clair
- Segmentez vos sitemaps par typologie de contenu (blog, produits, catégories) pour faciliter le suivi
- Vérifiez dans la Search Console quelles URLs du sitemap sont crawlées, indexées, ou ignorées
- Renforcez le maillage interne des URLs stratégiques : ne comptez pas sur le sitemap seul
- Évitez de soumettre des milliers d'URLs générées automatiquement sans valeur éditoriale
- Surveillez le taux d'indexation réel et croisez-le avec les logs serveur pour détecter les URLs crawlées mais non indexées
Quelles erreurs éviter absolument ?
Ne soumettez jamais un sitemap contenant des URLs en noindex, en 404, ou redirigées en 301. Google interprète cela comme un manque de cohérence technique et cela nuit à la confiance accordée au reste du fichier.
Évitez aussi de créer des sitemaps gigantesques (plusieurs dizaines de milliers d'URLs) si votre crawl budget est limité. Vous risquez de diluer l'attention de Googlebot sur des pages secondaires au détriment des pages stratégiques.
Comment vérifier que votre stratégie de sitemap est efficace ?
Croisez les données de la Search Console (section Sitemaps) avec vos logs serveur. Identifiez les URLs soumises mais jamais crawlées : c'est un signal clair qu'elles manquent de qualité ou de popularité.
Analysez aussi le délai entre la soumission d'une nouvelle URL et son premier crawl. Si ce délai est systématiquement long (plusieurs semaines), renforcez votre maillage interne et votre stratégie de backlinks plutôt que de vous reposer sur le sitemap.
❓ Questions frequentes
Un sitemap accélère-t-il vraiment l'indexation des nouvelles pages ?
Dois-je supprimer les URLs non indexées de mon sitemap ?
Le sitemap influence-t-il le crawl budget ?
Faut-il soumettre un sitemap pour un petit site bien maillé ?
Google respecte-t-il les balises priority et lastmod dans le sitemap ?
🎥 De la même vidéo 18
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 07/06/2023
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.