Declaration officielle
Ce qu'il faut comprendre
Pourquoi bloquer le crawl via robots.txt ne désindexe-t-il pas rapidement un site ?
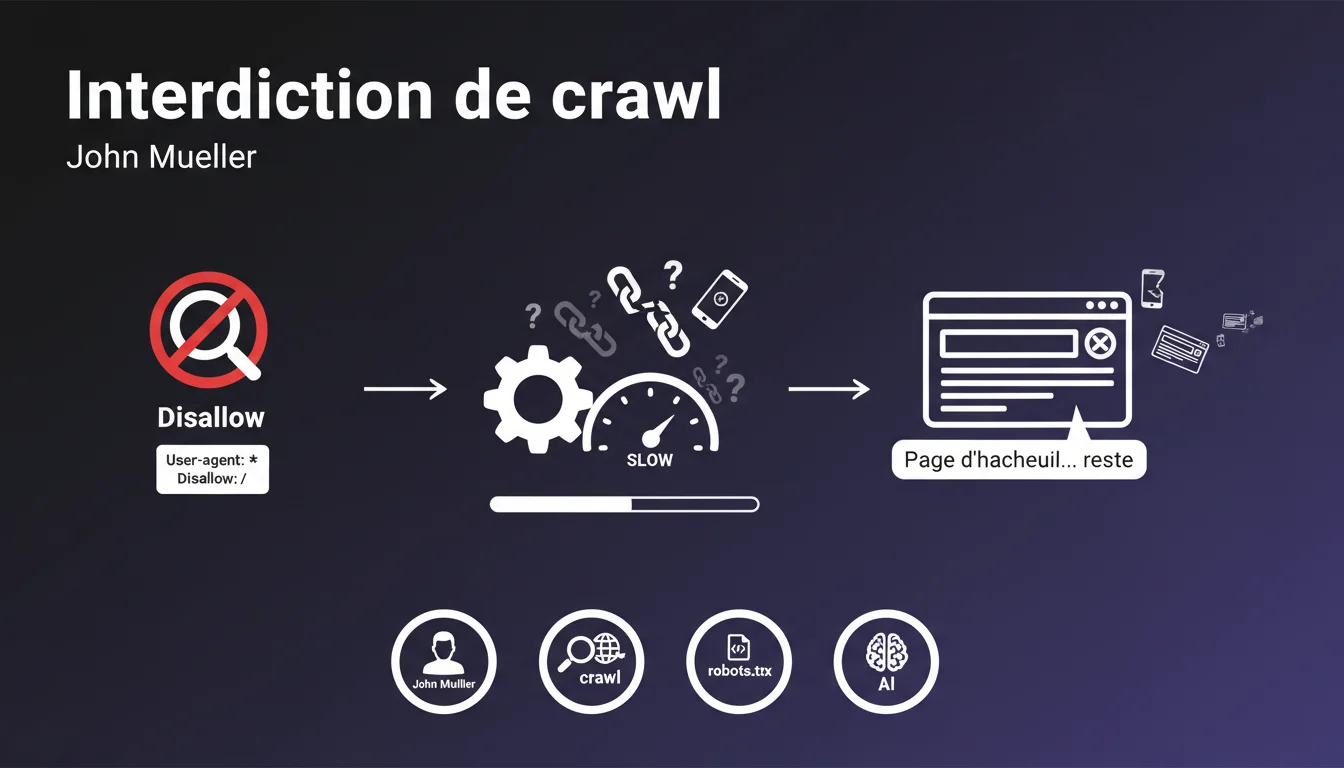
La directive Disallow: / dans le fichier robots.txt empêche les robots de Google de parcourir les pages de votre site. Toutefois, elle n'ordonne pas la suppression des URLs déjà présentes dans l'index.
Google continuera d'afficher les pages dans ses résultats, même sans pouvoir les crawler. La page d'accueil notamment restera visible longtemps dans l'index, car Google la considère comme une URL de référence pour le domaine.
Quelle est la différence entre crawl et indexation ?
Le crawl désigne le processus par lequel Googlebot visite et analyse vos pages. L'indexation correspond à l'enregistrement de ces pages dans la base de données de Google pour les afficher dans les résultats de recherche.
Bloquer le crawl n'empêche pas l'indexation des URLs connues. Google peut maintenir des pages dans son index en se basant sur des signaux externes comme les backlinks, même sans accéder au contenu.
Combien de temps faut-il pour qu'un site disparaisse avec cette méthode ?
Sans accès au contenu, Google mettra plusieurs semaines voire mois pour retirer progressivement les pages de son index. Ce processus est lent et imprévisible.
La page d'accueil et les pages ayant de nombreux backlinks persisteront particulièrement longtemps dans les résultats de recherche.
- Robots.txt bloque le crawl mais ne supprime pas l'indexation existante
- Les URLs restent visibles dans les résultats pendant une période prolongée
- La page d'accueil est la plus résistante à la désindexation passive
- Les signaux externes maintiennent les pages dans l'index
Avis d'un expert SEO
Cette recommandation est-elle cohérente avec les pratiques observées sur le terrain ?
Absolument. J'ai observé de nombreux cas où des sites bloqués via robots.txt restaient indexés pendant 3 à 6 mois. Certaines URLs avec une forte autorité persistaient même au-delà.
Google affiche alors des snippets génériques du type "Aucune information disponible" mais conserve le titre et l'URL dans les résultats. C'est particulièrement problématique pour les sites qui souhaitent disparaître rapidement des SERP pour des raisons légales ou stratégiques.
Quelles nuances importantes faut-il apporter à cette déclaration ?
La vitesse de désindexation dépend fortement du profil de liens du site. Un site avec peu de backlinks disparaîtra plus rapidement qu'un domaine avec une forte popularité externe.
De plus, Google peut maintenir l'indexation si d'autres sources référencent vos pages, créant un paradoxe : plus votre site est populaire, plus il est difficile de le désindexer passivement.
Dans quels scénarios cette approche pourrait-elle néanmoins être utilisée ?
Bloquer le crawl peut être pertinent comme mesure temporaire lors d'une migration ou d'une refonte majeure, pour éviter que Google crawle un site en construction.
C'est aussi utile pour économiser le budget de crawl sur des sections de faible valeur tout en les laissant accessibles aux utilisateurs. Mais jamais pour désindexer rapidement un site complet.
Impact pratique et recommandations
Quelle est la méthode correcte pour désindexer rapidement un site ?
La solution recommandée consiste à utiliser la balise meta noindex sur toutes les pages que vous souhaitez retirer de l'index. Cette directive indique explicitement à Google de supprimer ces URLs.
Vous devez impérativement laisser le site crawlable pour que Googlebot puisse détecter ces balises noindex. Combiner robots.txt et noindex est contre-productif.
Pour une désindexation d'urgence, utilisez l'outil de suppression d'URLs dans Google Search Console. Cette méthode offre un retrait temporaire de 6 mois, le temps que les balises noindex soient traitées.
Quelles erreurs critiques faut-il absolument éviter ?
Ne bloquez jamais le crawl si vous avez ajouté des balises noindex. Google ne pourra pas les voir et vos pages resteront indexées indéfiniment.
Évitez également de renvoyer des codes 404 ou 410 trop rapidement sans stratégie de redirection. Vous perdriez le bénéfice SEO de vos backlinks sans garantie de désindexation rapide.
- Ajouter la balise <meta name="robots" content="noindex"> sur toutes les pages à désindexer
- Vérifier que le robots.txt autorise le crawl de ces pages (pas de Disallow)
- Utiliser l'outil de suppression temporaire dans Google Search Console pour accélérer le processus
- Surveiller la désindexation avec une recherche site:votredomaine.com régulièrement
- Pour un site entier, envisager un code HTTP 410 Gone plutôt qu'un 404
- Conserver un fichier robots.txt accessible et valide
- Documenter votre processus pour référence future
Comment s'assurer que la désindexation se déroule correctement ?
Utilisez la Search Console pour monitorer l'évolution du nombre de pages indexées dans le rapport de couverture. Vous devriez constater une baisse progressive sur 2 à 4 semaines.
Effectuez des recherches manuelles avec l'opérateur site: pour vérifier quelles pages persistent dans l'index. Concentrez-vous sur les URLs prioritaires à retirer en premier.
💬 Commentaires (0)
Soyez le premier à commenter.