Declaration officielle
Ce qu'il faut comprendre
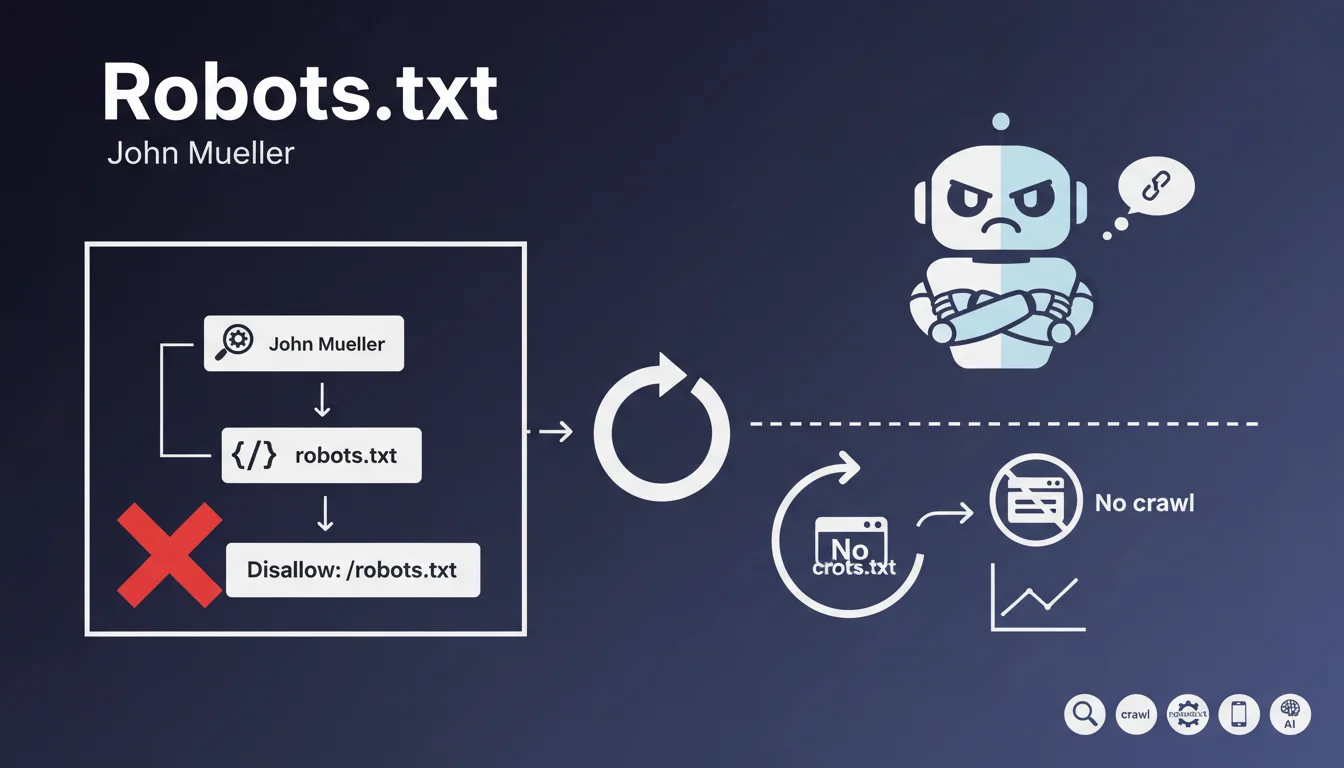
Cette déclaration aborde une situation paradoxale que certains webmasters tentent de mettre en place : interdire l'accès au fichier robots.txt en utilisant... le fichier robots.txt.
Le problème logique est évident : comment un robot pourrait-il lire l'interdiction si celle-ci se trouve dans un fichier auquel il n'a pas le droit d'accéder ? C'est une impossibilité technique pure.
Le fichier robots.txt est nécessairement public et doit être accessible pour que les moteurs puissent connaître les règles de crawl du site. C'est le point d'entrée obligatoire de tout robot avant d'explorer un site web.
- Le robots.txt doit être accessible à l'URL racine du domaine (/robots.txt)
- Les moteurs consultent ce fichier avant toute autre action de crawl
- Interdire son propre accès crée une contradiction logique insurmontable
- Cette pratique révèle une incompréhension du fonctionnement des directives robots
Avis d'un expert SEO
Cette situation illustre parfaitement une confusion fréquente chez certains webmasters sur le fonctionnement du protocole d'exclusion des robots. Le robots.txt n'est pas un fichier de sécurité mais un fichier de communication avec les moteurs.
Dans ma pratique, j'observe régulièrement des tentatives de "sécurisation" du robots.txt qui témoignent d'une mauvaise compréhension fondamentale. Le robots.txt n'empêche pas l'accès au contenu, il indique simplement aux robots bien intentionnés ce qu'ils peuvent ou non crawler.
Cette anecdote rappelle l'importance de bien maîtriser les fondamentaux SEO avant de manipuler des fichiers critiques comme le robots.txt, qui peut bloquer tout votre site si mal configuré.
Impact pratique et recommandations
- Ne jamais tenter de bloquer l'accès au fichier robots.txt lui-même
- Vérifier que votre robots.txt est accessible en HTTPS et HTTP à l'URL /robots.txt
- Utiliser la Search Console pour tester la syntaxe et l'accessibilité de votre robots.txt
- Distinguer clairement contrôle du crawl (robots.txt) et sécurité réelle (authentification serveur)
- Pour les contenus sensibles, utiliser des méthodes de protection côté serveur plutôt que le robots.txt
- Auditer régulièrement votre fichier robots.txt pour éviter les blocages involontaires de sections importantes
- Former vos équipes techniques aux principes fondamentaux du protocole d'exclusion des robots
La configuration optimale du robots.txt nécessite une compréhension approfondie de l'architecture technique et des priorités de crawl. Ces aspects techniques peuvent s'avérer complexes à maîtriser, particulièrement dans le cadre de sites à forte volumétrie ou d'architectures spécifiques. L'accompagnement par une agence SEO spécialisée permet d'éviter les erreurs critiques et d'établir une stratégie de crawl cohérente avec vos objectifs business, tout en bénéficiant d'un regard expert sur l'ensemble de votre écosystème technique.
💬 Commentaires (0)
Soyez le premier à commenter.