Declaration officielle
Ce qu'il faut comprendre
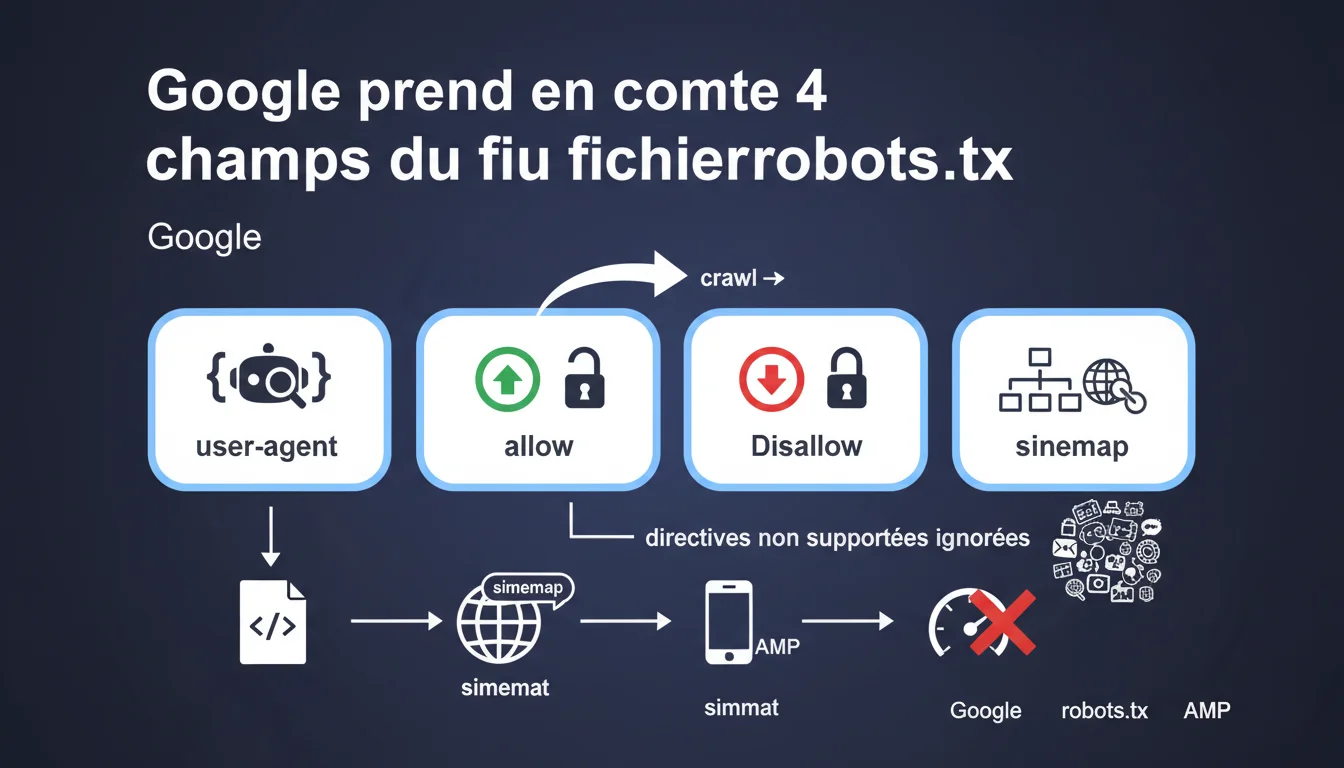
Google vient de clarifier officiellement sa position concernant le fichier robots.txt en précisant qu'il ne prend en charge que quatre champs spécifiques. Cette mise au point met fin à certaines ambiguïtés concernant les directives que les SEO utilisent parfois dans leurs configurations.
Concrètement, cela signifie que toutes les autres directives que vous pourriez avoir ajoutées dans votre robots.txt seront purement et simplement ignorées par les crawlers de Google. Elles ne produiront ni erreur, ni avertissement, mais n'auront tout simplement aucun effet sur le comportement du bot.
Cette déclaration a pour objectif d'encourager les webmasters et SEO à nettoyer leurs fichiers robots.txt et à éviter de s'appuyer sur des directives non supportées qui créent une fausse impression de contrôle.
- User-agent : identifie le crawler concerné par les règles
- Allow : autorise explicitement l'accès à des ressources
- Disallow : bloque l'accès à des répertoires ou fichiers
- Sitemap : indique l'emplacement du sitemap XML
- Toutes les autres directives (crawl-delay, noindex, etc.) sont ignorées par Google
Avis d'un expert SEO
Cette clarification de Google est cohérente avec ce que nous observons depuis des années sur le terrain. Les directives comme crawl-delay n'ont jamais été officiellement supportées par Googlebot, même si d'autres moteurs comme Bing les prennent en compte. Google gère son propre rythme de crawl de manière algorithmique.
La directive noindex dans le robots.txt mérite une attention particulière. Certains SEO l'utilisaient encore, mais Google l'a officiellement abandonnée depuis 2019. Utiliser cette directive crée une fausse sécurité : vous pensez bloquer l'indexation alors que rien ne se passe réellement. Pour désindexer, il faut utiliser la balise meta robots ou l'en-tête HTTP X-Robots-Tag.
Il faut également noter que les autres moteurs de recherche comme Bing, Yandex ou Baidu peuvent supporter des directives additionnelles. Si vous ciblez ces moteurs, certaines directives restent pertinentes, mais il faut bien comprendre que Google les ignorera totalement.
Impact pratique et recommandations
- Auditez votre fichier robots.txt actuel pour identifier toutes les directives qui ne font pas partie des 4 champs supportés par Google
- Supprimez ou commentez les directives crawl-delay si vous les utilisez pour Google (elles restent valables pour Bing)
- Remplacez toute directive noindex dans le robots.txt par des balises meta robots noindex dans le HTML ou des en-têtes HTTP X-Robots-Tag
- Vérifiez que vos sitemaps sont correctement déclarés avec la directive sitemap (seul moyen de les communiquer via robots.txt)
- Documentez les raisons pour lesquelles vous conservez certaines directives non-Google si vous ciblez d'autres moteurs de recherche
- Testez votre robots.txt avec l'outil de test de Google Search Console pour valider la syntaxe des 4 directives supportées
- Utilisez les paramètres de Google Search Console (comme l'exploration des paramètres d'URL) pour affiner le comportement de crawl plutôt que des directives non supportées
- Mettez en place un monitoring pour vous assurer que les pages que vous pensiez protégées par des directives non supportées ne sont pas indexées
La gestion optimale du fichier robots.txt et la mise en conformité avec les standards de Google peuvent sembler simples en théorie, mais impliquent souvent des arbitrages techniques complexes selon votre architecture et vos objectifs SEO. Un mauvais paramétrage peut avoir des conséquences importantes sur votre visibilité.
Pour les sites avec une architecture complexe ou des enjeux SEO stratégiques, l'accompagnement par une agence SEO spécialisée peut s'avérer précieux pour auditer l'ensemble de votre configuration, identifier les risques cachés et mettre en place une stratégie de crawl et d'indexation véritablement efficace et conforme aux recommandations de Google.
💬 Commentaires (0)
Soyez le premier à commenter.