Official statement
What you need to understand
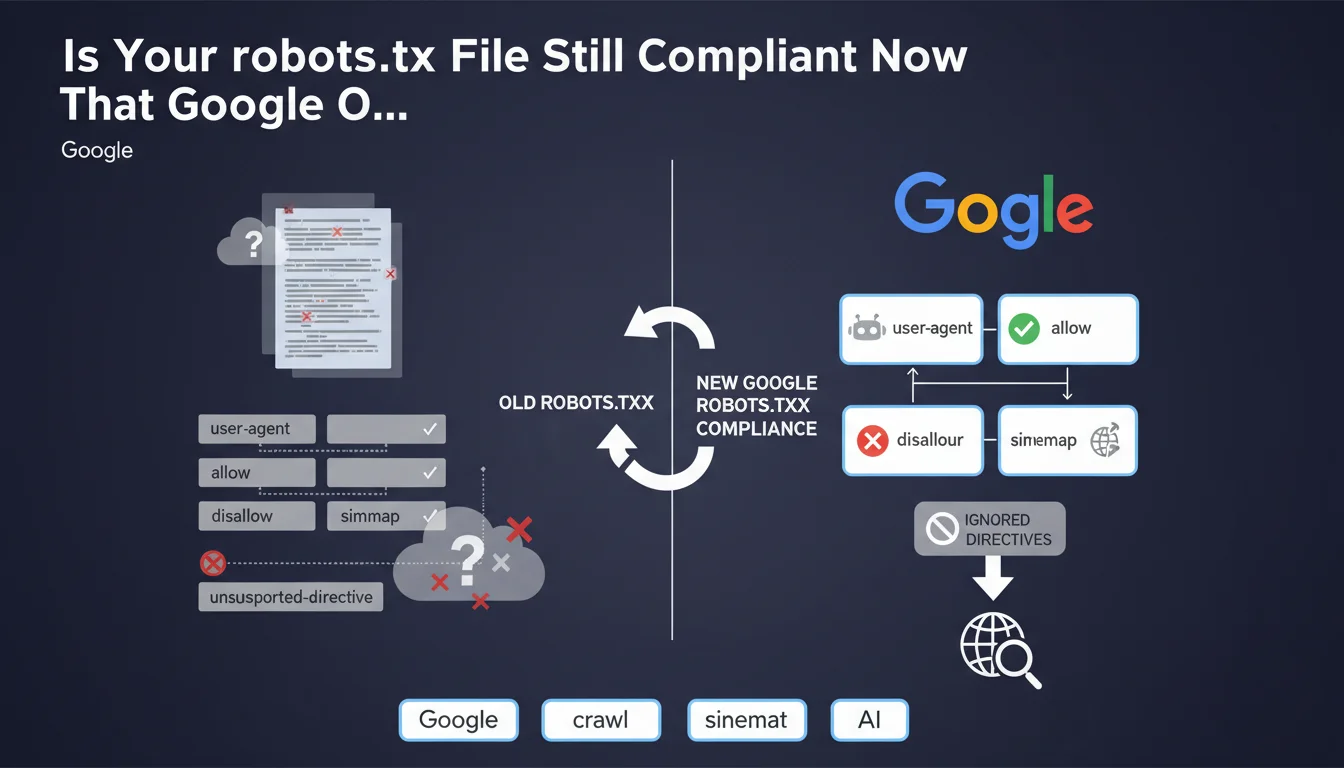
Google has just officially clarified its position regarding the robots.txt file by specifying that it only supports four specific fields. This clarification puts an end to certain ambiguities concerning directives that SEOs sometimes use in their configurations.
Concretely, this means that all other directives you may have added to your robots.txt will be purely and simply ignored by Google's crawlers. They will produce neither errors nor warnings, but will simply have no effect on the bot's behavior.
This statement aims to encourage webmasters and SEOs to clean up their robots.txt files and avoid relying on unsupported directives that create a false sense of control.
- User-agent: identifies the crawler concerned by the rules
- Allow: explicitly authorizes access to resources
- Disallow: blocks access to directories or files
- Sitemap: indicates the location of the XML sitemap
- All other directives (crawl-delay, noindex, etc.) are ignored by Google
SEO Expert opinion
This clarification from Google is consistent with what we've been observing in the field for years. Directives like crawl-delay have never been officially supported by Googlebot, even though other engines like Bing do take them into account. Google manages its own crawl rate algorithmically.
The noindex directive in robots.txt deserves particular attention. Some SEOs were still using it, but Google officially discontinued it in 2019. Using this directive creates false security: you think you're blocking indexation when nothing is actually happening. To deindex, you must use the meta robots tag or the X-Robots-Tag HTTP header.
It should also be noted that other search engines like Bing, Yandex or Baidu may support additional directives. If you're targeting these engines, certain directives remain relevant, but you need to understand clearly that Google will completely ignore them.
Practical impact and recommendations
- Audit your current robots.txt file to identify all directives that are not part of the 4 fields supported by Google
- Remove or comment out crawl-delay directives if you're using them for Google (they remain valid for Bing)
- Replace any noindex directives in robots.txt with meta robots noindex tags in HTML or X-Robots-Tag HTTP headers
- Verify that your sitemaps are correctly declared with the sitemap directive (the only way to communicate them via robots.txt)
- Document the reasons why you're keeping certain non-Google directives if you're targeting other search engines
- Test your robots.txt with the testing tool in Google Search Console to validate the syntax of the 4 supported directives
- Use Google Search Console settings (such as URL parameter handling) to fine-tune crawl behavior rather than unsupported directives
- Set up monitoring to ensure that pages you thought were protected by unsupported directives are not being indexed
Optimal management of the robots.txt file and compliance with Google's standards may seem simple in theory, but often involve complex technical trade-offs depending on your architecture and SEO objectives. Incorrect configuration can have significant consequences on your visibility.
For sites with complex architecture or strategic SEO challenges, support from a specialized SEO agency can prove valuable for auditing your entire configuration, identifying hidden risks, and implementing a truly effective crawl and indexation strategy that complies with Google's recommendations.
💬 Comments (0)
Be the first to comment.