Declaration officielle
Autres déclarations de cette vidéo 22 ▾
- □ Pourquoi la position moyenne de Search Console ne reflète-t-elle pas un classement théorique mais des affichages réels ?
- □ Peut-on encore se permettre d'attendre qu'un classement instable se stabilise tout seul ?
- □ Faut-il vraiment produire plus de contenu pour améliorer son SEO ?
- □ Où placer son sitemap XML pour optimiser son crawl ?
- □ Faut-il vraiment utiliser l'outil d'inspection d'URL pour indexer un nouveau site ?
- □ Combien de temps faut-il attendre pour voir les backlinks dans Search Console ?
- □ Pourquoi les données Search Console et Analytics ne concordent-elles jamais vraiment ?
- □ Search Console collecte-t-elle vraiment toutes les données sur les gros sites e-commerce ?
- □ Les produits en rupture de stock peuvent-ils vraiment être traités comme des soft 404 par Google ?
- □ Les outils de test Google crawlent-ils vraiment en temps réel ou utilisent-ils un cache ?
- □ Google utilise-t-il des algorithmes différents selon votre secteur d'activité ?
- □ Pourquoi Google ignore-t-il les sites agrégateurs de faible effort ?
- □ Google compte-t-il vraiment les clics sur les rich results comme des clics organiques ?
- □ L'ordre des liens dans le HTML influence-t-il vraiment la priorité de crawl de Google ?
- □ Faut-il vraiment éviter les URLs avec paramètres pour le SEO ?
- □ Pourquoi robots.txt bloque le crawl mais n'empêche pas l'indexation de vos pages ?
- □ Les produits en rupture de stock nuisent-ils au classement global de votre site e-commerce ?
- □ Le contenu dupliqué partiel pénalise-t-il vraiment vos pages ?
- □ Pourquoi Google refuse-t-il d'indexer plusieurs versions d'une même page malgré une canonicalisation correcte ?
- □ Comment Google choisit-il réellement quelle URL canoniser parmi vos contenus dupliqués ?
- □ Les mentions de marque sans lien ont-elles une valeur SEO ?
- □ Pourquoi un lien sans URL indexée ne sert strictement à rien ?
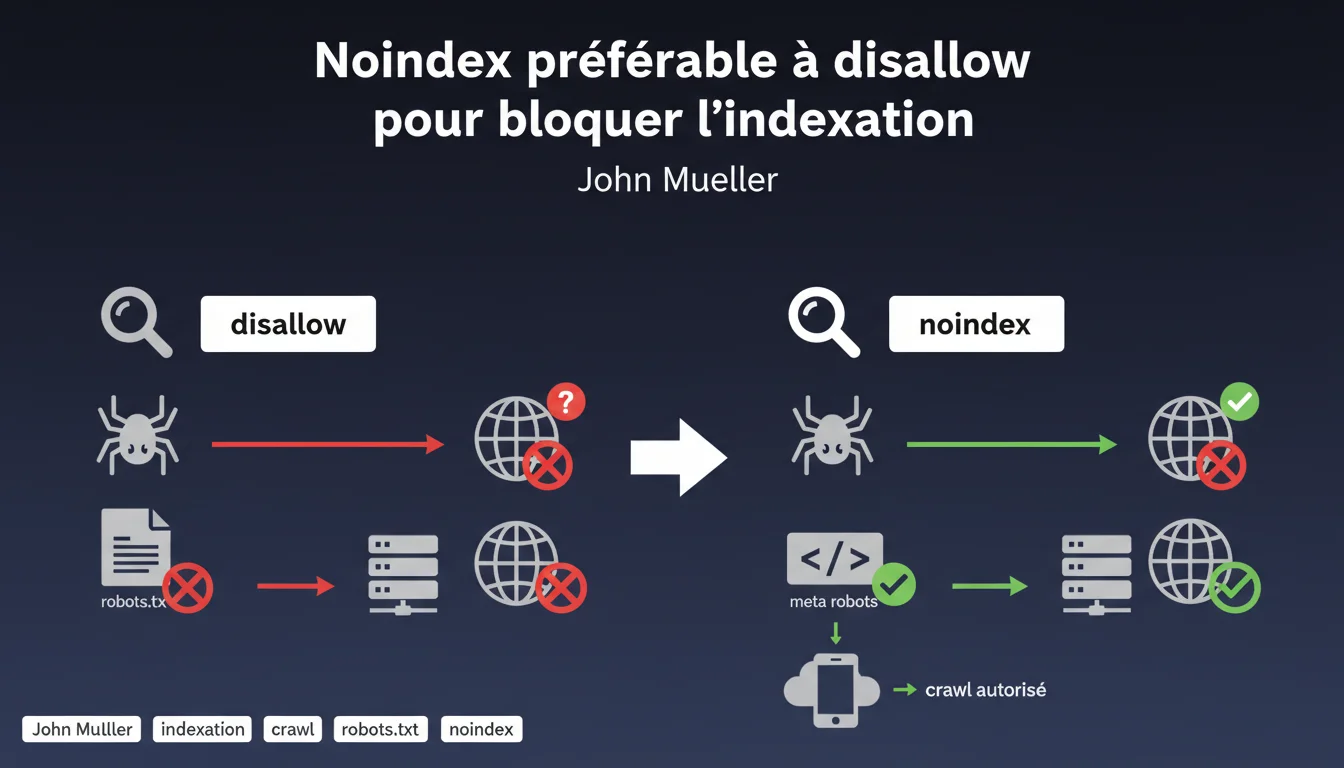
Google recommande explicitement d'utiliser noindex plutôt que disallow dans robots.txt pour bloquer l'indexation. La distinction est cruciale : disallow empêche le crawl, donc Google ne peut pas lire la balise noindex. Pour que noindex fonctionne, vous devez autoriser l'accès des robots à la page.
Ce qu'il faut comprendre
Pourquoi cette distinction entre noindex et disallow est-elle importante ?
Les deux directives semblent similaires en apparence, mais elles agissent à des niveaux totalement différents. Disallow dans robots.txt bloque le crawl : Googlebot ne peut même pas accéder à la page pour en analyser le contenu.
Noindex, en revanche, nécessite que le robot crawle la page pour détecter la balise meta robots. C'est là que le paradoxe survient pour beaucoup de SEO : comment Google peut-il lire une directive sur une page qu'il n'a pas le droit de crawler ?
Que se passe-t-il concrètement si on bloque avec disallow ?
Si vous bloquez une URL via robots.txt, Google ne peut pas crawler la page. Résultat : il ne détecte jamais la balise noindex que vous auriez pu placer dessus.
Dans certains cas, Google peut quand même indexer l'URL (sans contenu ni meta description) s'il la découvre via des backlinks externes. Vous vous retrouvez avec une page indexée sans avoir voulu, juste parce que vous avez utilisé le mauvais outil.
Quand utiliser l'un ou l'autre ?
La logique est simple : si vous ne voulez pas qu'une page apparaisse dans les SERP, utilisez noindex. Si vous voulez économiser du crawl budget sur des ressources inutiles (fichiers JS/CSS lourds, URL de session, facettes infinies), là disallow peut avoir du sens.
- Noindex = contrôle de l'indexation (la page peut être crawlée, mais ne doit pas apparaître dans les résultats)
- Disallow = économie de crawl budget (la page ne sera pas visitée par les robots)
- Bloquer une page avec disallow n'empêche pas son indexation si elle reçoit des liens externes
- Pour qu'une balise noindex soit lue, le crawl doit être autorisé
Avis d'un expert SEO
Cette recommandation est-elle cohérente avec les observations terrain ?
Oui, et c'est même un piège classique. J'ai vu des dizaines de sites bloquer des pages sensibles via robots.txt en pensant les protéger de l'indexation, pour ensuite les retrouver dans Google avec la mention « Aucune information disponible pour cette page ».
Le problème, c'est que beaucoup de CMS et plugins SEO mélangent encore les deux concepts. Certains outils proposent même de cocher « bloquer l'indexation » en ajoutant automatiquement un disallow, ce qui est contre-productif.
Dans quels cas cette règle mérite-t-elle d'être nuancée ?
Il existe des situations où combiner les deux peut avoir du sens — mais c'est rare. Par exemple, si vous avez déjà désindexé une section entière avec noindex et que vous voulez ensuite stopper le crawl pour récupérer du budget, vous pouvez ajouter disallow après coup.
Mais attention : une fois le crawl bloqué, Google ne pourra plus vérifier que le noindex est toujours en place. Si vous retirez le noindex avant d'ajouter disallow, vous risquez une réindexation. [A vérifier] sur des volumes importants avec Search Console avant toute manipulation.
Quel est le risque réel d'une mauvaise configuration ?
Le risque principal, c'est d'exposer des URLs que vous voulez garder privées. Pages de test, environnements de staging, contenus dupliqués, filtres à facettes — tout ça peut se retrouver indexé malgré un robots.txt censé les protéger.
Impact pratique et recommandations
Que faut-il faire concrètement pour corriger une mauvaise configuration ?
D'abord, identifiez toutes les URLs actuellement bloquées dans robots.txt qui ne devraient pas être indexées. Exportez la liste depuis votre fichier robots.txt, puis croisez-la avec les URLs indexées dans Search Console.
Ensuite, pour chaque URL concernée : retirez la directive disallow, ajoutez une balise <meta name="robots" content="noindex, follow"> dans le head, et laissez Google recrawler. Vous pouvez forcer le crawl via l'outil d'inspection d'URL dans GSC.
Quelles erreurs éviter absolument ?
Ne bloquez jamais une page via robots.txt en espérant qu'elle disparaîtra de l'index. Si elle est déjà indexée, le blocage du crawl l'y maintiendra indéfiniment.
Autre erreur fréquente : ajouter noindex et disallow simultanément sur des pages neuves. Google ne verra jamais le noindex, et vous perdez le contrôle.
- Auditer le fichier robots.txt actuel et lister toutes les directives disallow
- Vérifier dans Search Console si des URLs bloquées apparaissent dans l'index
- Remplacer disallow par noindex pour toutes les pages à exclure des SERP
- Conserver disallow uniquement pour les ressources inutiles (paramètres de session, fichiers annexes)
- Tester les modifications sur un environnement de staging avant déploiement
- Utiliser l'outil d'inspection d'URL pour forcer le recrawl après modification
Comment vérifier que la configuration est correcte ?
Utilisez l'outil de test du fichier robots.txt dans Search Console pour valider que les URLs critiques ne sont pas bloquées. Ensuite, inspectez manuellement quelques pages avec l'outil d'inspection d'URL pour confirmer que la balise noindex est bien détectée.
Un crawl avec Screaming Frog ou Sitebulb en mode Googlebot peut également révéler les incohérences : pages bloquées mais présentes dans le sitemap, ou pages avec noindex inaccessible à cause d'un disallow.
❓ Questions frequentes
Peut-on utiliser disallow et noindex en même temps ?
Si une page est déjà indexée, disallow va-t-il la désindexer ?
Comment désindexer rapidement une page indexée par erreur ?
Le noindex empêche-t-il le passage de PageRank ?
Faut-il ajouter nofollow en plus de noindex ?
🎥 De la même vidéo 22
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 28/03/2022
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.