Declaration officielle
Autres déclarations de cette vidéo 22 ▾
- □ Pourquoi la position moyenne de Search Console ne reflète-t-elle pas un classement théorique mais des affichages réels ?
- □ Peut-on encore se permettre d'attendre qu'un classement instable se stabilise tout seul ?
- □ Faut-il vraiment produire plus de contenu pour améliorer son SEO ?
- □ Où placer son sitemap XML pour optimiser son crawl ?
- □ Faut-il vraiment utiliser l'outil d'inspection d'URL pour indexer un nouveau site ?
- □ Combien de temps faut-il attendre pour voir les backlinks dans Search Console ?
- □ Pourquoi les données Search Console et Analytics ne concordent-elles jamais vraiment ?
- □ Search Console collecte-t-elle vraiment toutes les données sur les gros sites e-commerce ?
- □ Faut-il vraiment préférer noindex à disallow pour contrôler l'indexation ?
- □ Les produits en rupture de stock peuvent-ils vraiment être traités comme des soft 404 par Google ?
- □ Les outils de test Google crawlent-ils vraiment en temps réel ou utilisent-ils un cache ?
- □ Google utilise-t-il des algorithmes différents selon votre secteur d'activité ?
- □ Pourquoi Google ignore-t-il les sites agrégateurs de faible effort ?
- □ Google compte-t-il vraiment les clics sur les rich results comme des clics organiques ?
- □ L'ordre des liens dans le HTML influence-t-il vraiment la priorité de crawl de Google ?
- □ Faut-il vraiment éviter les URLs avec paramètres pour le SEO ?
- □ Pourquoi robots.txt bloque le crawl mais n'empêche pas l'indexation de vos pages ?
- □ Les produits en rupture de stock nuisent-ils au classement global de votre site e-commerce ?
- □ Le contenu dupliqué partiel pénalise-t-il vraiment vos pages ?
- □ Pourquoi Google refuse-t-il d'indexer plusieurs versions d'une même page malgré une canonicalisation correcte ?
- □ Comment Google choisit-il réellement quelle URL canoniser parmi vos contenus dupliqués ?
- □ Les mentions de marque sans lien ont-elles une valeur SEO ?
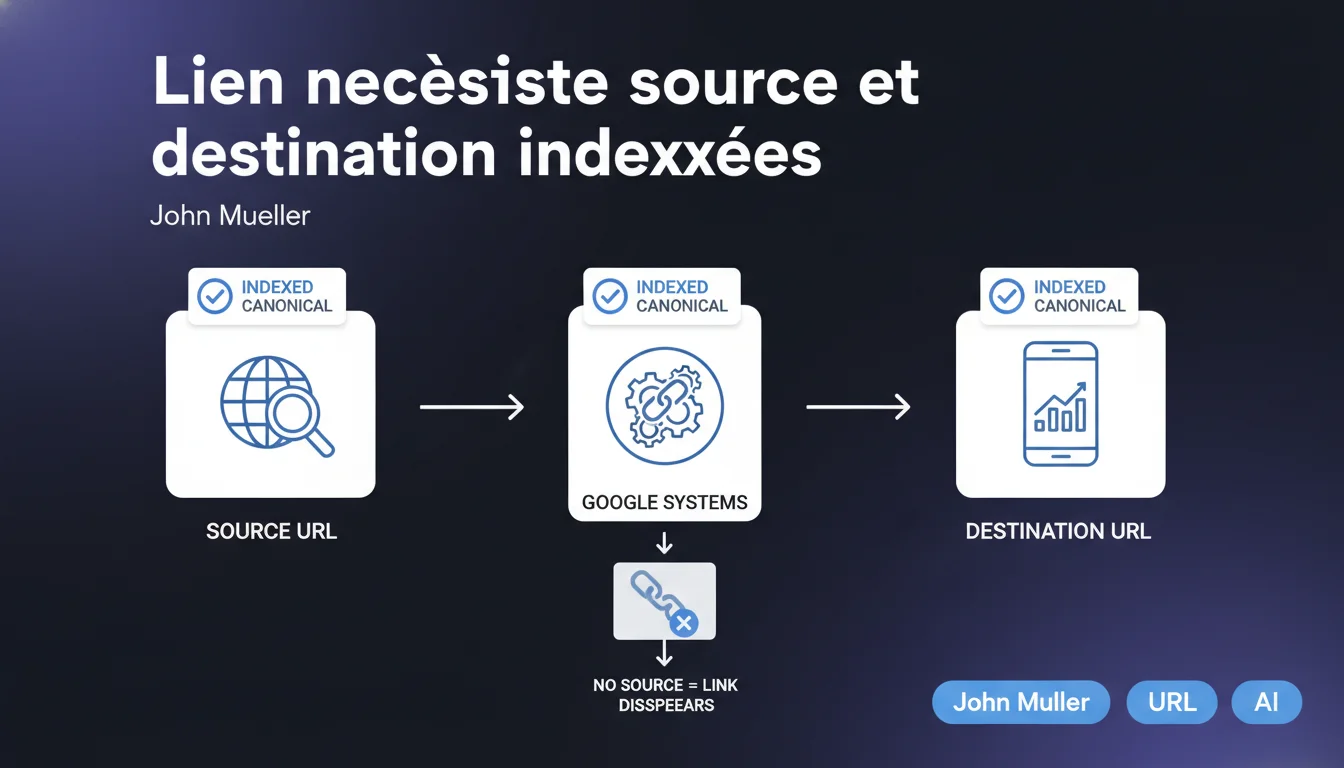
Google ne prend en compte un lien que si source ET destination sont des URLs canoniques indexées. Si l'une des deux manque dans l'index, le lien est purement et simplement ignoré — il disparaît des systèmes de Google. Concrètement : un backlink depuis une page désindexée n'a aucune valeur, et pointer vers une page bloquée ou non indexée ne transmet rien.
Ce qu'il faut comprendre
Que signifie vraiment « URL canonique indexée » ?
Google ne travaille qu'avec des URLs canoniques — c'est-à-dire la version de référence d'une page qu'il a décidé d'afficher dans ses résultats. Si vous avez plusieurs variantes d'une même page (HTTP/HTTPS, www/non-www, paramètres d'URL), Google en choisit une comme canonique.
L'indexation, c'est le fait que Google ait effectivement stocké cette URL dans sa base de données et la considère comme éligible pour apparaître dans les résultats. Sans indexation, pas de prise en compte — ni pour le contenu, ni pour les liens.
Qu'arrive-t-il exactement à un lien dont une extrémité manque ?
Mueller est catégorique : le lien disparaît. Google ne sait pas quoi en faire, donc il l'ignore complètement. Pas de transmission de PageRank, pas de signal d'autorité, pas de signal thématique. Le lien est aussi utile qu'un lien en nofollow multiplié par zéro.
Soyons honnêtes — on savait déjà qu'un backlink depuis une page désindexée n'avait aucun poids. Ce que Mueller confirme ici, c'est que c'est également vrai pour la destination : pointer vers une page non indexée ne crée aucun bénéfice SEO, même si la source est puissante.
Pourquoi Google fonctionne-t-il ainsi ?
Le moteur de recherche travaille avec un graphe de liens entre URLs indexées. Chaque lien est une arête entre deux nœuds de ce graphe. Si un nœud n'existe pas (page non indexée), l'arête ne peut pas exister non plus — elle ne mène nulle part ou ne vient de nulle part.
C'est une contrainte architecturale fondamentale : Google ne peut pas attribuer de valeur à un lien sans connaître les deux extrémités. Il ne stocke pas de « liens en attente » dans l'espoir qu'une page soit indexée plus tard.
- Un lien n'existe dans les systèmes Google que si source ET destination sont indexées
- L'URL doit être la version canonique reconnue par Google, pas une variante
- Un backlink depuis une page désindexée = zéro valeur SEO
- Un lien interne vers une page bloquée (robots.txt, noindex) = inutile pour le PageRank
- Google ne « met pas de côté » les liens en attente d'indexation — ils disparaissent
Avis d'un expert SEO
Cette règle est-elle cohérente avec ce qu'on observe sur le terrain ?
Totalement. Les tests menés par la communauté SEO confirment depuis des années qu'un backlink depuis une page désindexée n'apporte strictement rien. On le voit régulièrement avec des sites qui obtiennent des liens depuis des annuaires ou agrégateurs dont les pages ne sont jamais indexées — impact nul.
Ce qui est intéressant, c'est que Mueller insiste aussi sur la destination. Certains praticiens pensent encore qu'un lien interne vers une page en noindex « compte quand même » pour la structure du site. Non. Si la page cible n'est pas indexée, le lien ne transmet rien et ne structure rien dans les systèmes Google.
Quelles sont les zones grises de cette déclaration ?
Mueller parle d'« URLs canoniques indexées », mais il ne précise pas combien de temps une page doit rester indexée pour que les liens comptent. Une page indexée puis rapidement désindexée perd-elle rétroactivement la valeur de ses liens sortants ? [À vérifier] — aucune donnée officielle là-dessus.
Autre point : qu'en est-il des pages en crawl mais pas en indexation (état « Discovered - currently not indexed ») ? Techniquement, elles ne sont pas indexées, donc les liens ne devraient pas compter. Mais si Google les crawle régulièrement, stocke-t-il quand même une trace de leurs liens dans l'attente d'une indexation future ? Mueller dit non, mais des observations terrain suggèrent que certains signaux peuvent être « pré-calculés » — c'est flou.
Dans quels cas cette règle pose-t-elle problème ?
Le cas classique : vous avez un nouveau site avec peu d'autorité. Google indexe lentement vos pages. Pendant des semaines, certaines sont en « Discovered - currently not indexed ». Durant cette période, tous les liens internes pointant vers ces pages sont inutiles — ils ne transmettent rien.
Résultat : votre maillage interne ne fonctionne qu'à moitié, ce qui ralentit encore plus l'indexation des pages en attente. C'est un cercle vicieux que beaucoup de sites e-commerce ou éditoriaux subissent sans le réaliser.
Impact pratique et recommandations
Comment vérifier que vos liens comptent vraiment ?
D'abord, assurez-vous que toutes vos pages stratégiques sont indexées. Utilisez la Search Console : section « Couverture » ou « Pages ». Toute page en « Découverte, actuellement non indexée » ou « Exclue » est inutile pour le maillage interne et ne bénéficie d'aucun backlink.
Ensuite, vérifiez vos sources de backlinks. Un lien depuis un site dont les pages ne sont jamais indexées ne vous apportera rien — même si le domaine semble puissant. Croisez vos backlinks (Ahrefs, Majestic) avec l'état d'indexation réel des pages sources via un « site:URL » sur Google.
Quelles erreurs éviter absolument ?
Ne gaspillez pas votre crawl budget sur des pages que vous ne voulez pas indexer. Si vous bloquez une section en noindex ou robots.txt, évitez de la mailler massivement depuis vos pages indexées — ces liens sont perdus.
Autre piège : les canonicales mal configurées. Si Google choisit une URL canonique différente de celle que vous visez, tous vos liens internes pointant vers votre version préférée sont ignorés — Google les redirige mentalement vers la canonique, mais ça ne fonctionne pas toujours comme prévu.
Que faire concrètement pour maximiser la valeur de vos liens ?
- Auditez l'état d'indexation de toutes vos pages dans la Search Console — éliminez le « Discovered, currently not indexed »
- Concentrez votre maillage interne sur les pages effectivement indexées
- Vérifiez que vos backlinks proviennent de pages indexées (test « site:URL » sur Google)
- Corrigez les canonicales pour que Google reconnaisse bien vos URLs cibles
- Évitez de pointer massivement vers des pages en noindex ou bloquées — ça ne sert à rien
- Relancez l'indexation des pages stratégiques bloquées via « Demander une indexation » dans la Search Console
❓ Questions frequentes
Un lien depuis une page en noindex compte-t-il ?
Que se passe-t-il si la page cible est indexée puis désindexée ?
Un lien interne vers une page « Discovered - currently not indexed » sert-il à quelque chose ?
Comment savoir si mes backlinks proviennent de pages indexées ?
Une canonical mal configurée peut-elle faire perdre des liens ?
🎥 De la même vidéo 22
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 28/03/2022
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.