Declaration officielle
Autres déclarations de cette vidéo 22 ▾
- □ Pourquoi la position moyenne de Search Console ne reflète-t-elle pas un classement théorique mais des affichages réels ?
- □ Peut-on encore se permettre d'attendre qu'un classement instable se stabilise tout seul ?
- □ Faut-il vraiment produire plus de contenu pour améliorer son SEO ?
- □ Où placer son sitemap XML pour optimiser son crawl ?
- □ Faut-il vraiment utiliser l'outil d'inspection d'URL pour indexer un nouveau site ?
- □ Combien de temps faut-il attendre pour voir les backlinks dans Search Console ?
- □ Pourquoi les données Search Console et Analytics ne concordent-elles jamais vraiment ?
- □ Search Console collecte-t-elle vraiment toutes les données sur les gros sites e-commerce ?
- □ Faut-il vraiment préférer noindex à disallow pour contrôler l'indexation ?
- □ Les produits en rupture de stock peuvent-ils vraiment être traités comme des soft 404 par Google ?
- □ Les outils de test Google crawlent-ils vraiment en temps réel ou utilisent-ils un cache ?
- □ Google utilise-t-il des algorithmes différents selon votre secteur d'activité ?
- □ Pourquoi Google ignore-t-il les sites agrégateurs de faible effort ?
- □ Google compte-t-il vraiment les clics sur les rich results comme des clics organiques ?
- □ L'ordre des liens dans le HTML influence-t-il vraiment la priorité de crawl de Google ?
- □ Faut-il vraiment éviter les URLs avec paramètres pour le SEO ?
- □ Les produits en rupture de stock nuisent-ils au classement global de votre site e-commerce ?
- □ Le contenu dupliqué partiel pénalise-t-il vraiment vos pages ?
- □ Pourquoi Google refuse-t-il d'indexer plusieurs versions d'une même page malgré une canonicalisation correcte ?
- □ Comment Google choisit-il réellement quelle URL canoniser parmi vos contenus dupliqués ?
- □ Les mentions de marque sans lien ont-elles une valeur SEO ?
- □ Pourquoi un lien sans URL indexée ne sert strictement à rien ?
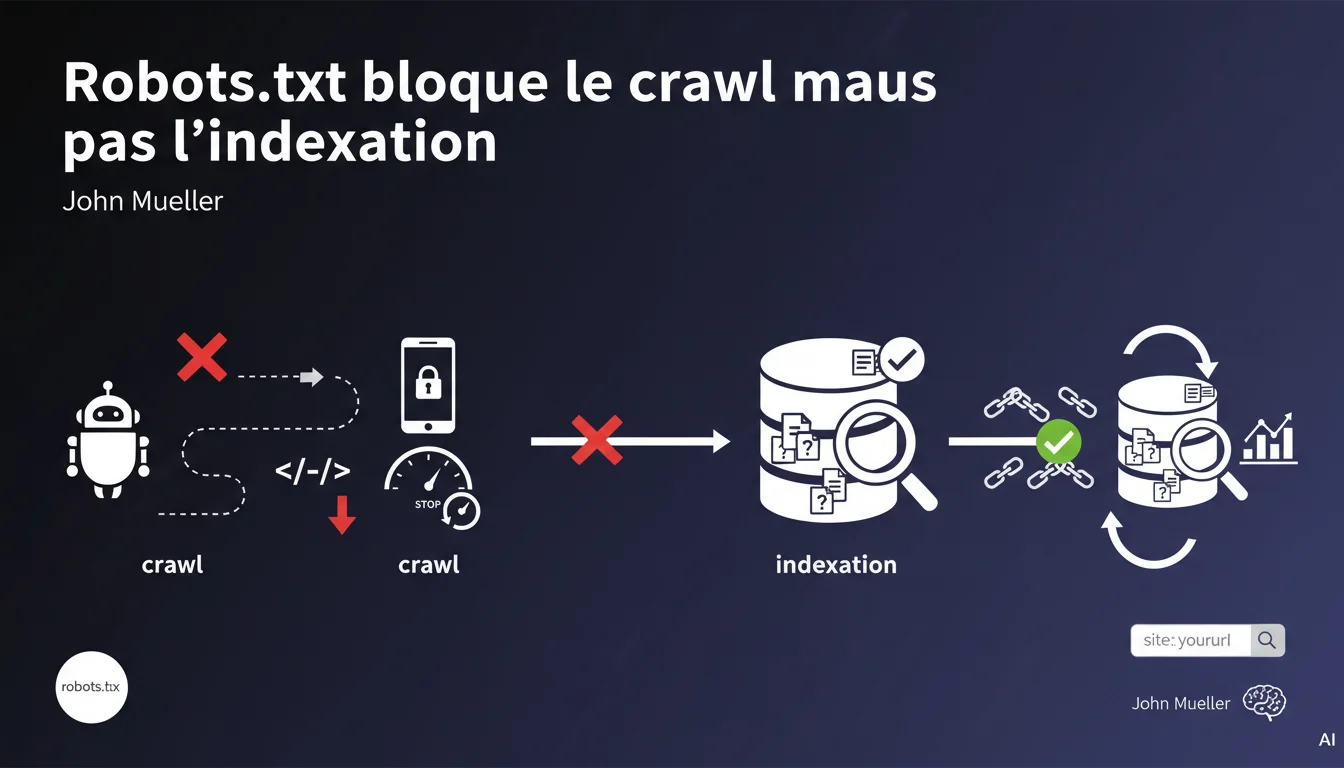
Robots.txt empêche uniquement Googlebot de crawler vos URLs, pas de les indexer. Si une page bloquée reçoit des backlinks, elle peut apparaître dans l'index sans que Google n'ait jamais accédé à son contenu — ce qui pose des problèmes de contrôle sur ce qui est effectivement indexé.
Ce qu'il faut comprendre
Quelle est la différence entre crawl et indexation dans ce contexte ?
Le crawl désigne l'accès de Googlebot au contenu d'une page : lecture du HTML, des ressources, analyse du texte. L'indexation, c'est la décision d'inclure cette URL dans les résultats de recherche.
Mueller précise qu'un blocage robots.txt empêche le premier mais pas le second. Concrètement — une URL jamais crawlée peut quand même figurer dans l'index si Google détecte son existence via des liens externes.
Comment une page peut-elle être indexée sans être crawlée ?
Google découvre des URLs via plusieurs sources : sitemaps, backlinks, redirections, liens internes sur des pages accessibles. Si votre robots.txt bloque l'accès à une URL mais que celle-ci reçoit des liens, Google l'enregistre dans son index.
L'URL apparaît alors dans les résultats avec une description générique du type « Aucune information disponible sur cette page » — parce que le moteur n'a jamais pu lire le contenu.
Pourquoi est-ce un problème pour le référencement ?
Vous perdez le contrôle éditorial. Google affiche votre URL avec un snippet vide ou basé uniquement sur l'anchor text des backlinks. Impossible d'optimiser title, meta description ou contenu.
- Les pages bloquées par robots.txt mais indexées nuisent à la qualité perçue de votre site dans les SERP
- Vous ne pouvez pas gérer les signaux on-page (H1, sémantique, maillage interne)
- Ces URLs consomment du crawl budget sans apporter de valeur
- La commande
site:révèle souvent des centaines de ces pages « zombies »
Avis d'un expert SEO
Cette déclaration est-elle cohérente avec les observations terrain ?
Totalement. Les audits SEO révèlent régulièrement des dizaines voire centaines d'URLs bloquées par robots.txt mais présentes dans l'index. C'est particulièrement fréquent sur les anciens sites qui ont accumulé des backlinks vers des sections devenues interdites au crawl.
Le reflexe de bloquer des URLs « inutiles » via robots.txt est une erreur classique. Les praticiens pensent éliminer ces pages de Google alors qu'ils ne font que les rendre incontrôlables.
Quelles nuances faut-il apporter à cette règle ?
Mueller ne précise pas le délai entre blocage robots.txt et désinscription effective de l'index. Dans la pratique, une URL bloquée qui ne reçoit plus de signaux externes finit par disparaître — mais ça prend des mois, parfois plus d'un an [A vérifier].
Autre point : si vous bloquez une URL avant qu'elle ne reçoive le moindre lien externe, elle ne sera jamais indexée. Le problème surgit quand vous bloquez des pages déjà crawlées et linkées.
noindex après un blocage robots.txt résout le problème. C'est faux — Googlebot ne peut pas lire cette balise puisqu'il n'accède plus à la page. Vous vous enfermez dans une impasse technique.Dans quels cas cette mécanique devient-elle vraiment problématique ?
Les sites avec facettes de filtrage, pages de recherche interne ou anciennes sections migrées sont les plus exposés. Vous bloquez ces URLs pour économiser du crawl budget, mais elles restent indexées grâce à des liens historiques.
Résultat : des centaines de pages apparaissent dans site:votredomaine.com avec des snippets vides, ce qui dégrade la perception qualité du site. Google indexe du vide — et vous n'avez aucun levier pour corriger.
Impact pratique et recommandations
Que faut-il faire concrètement pour nettoyer ces URLs orphelines ?
Première étape : identifier les pages bloquées par robots.txt mais présentes dans l'index. Utilisez la commande site: combinée à une vérification de votre fichier robots.txt actuel.
Pour chaque URL détectée, supprimez temporairement la directive Disallow correspondante. Ajoutez ensuite une balise <meta name="robots" content="noindex"> dans le <head> de ces pages. Googlebot pourra alors crawler, lire la directive noindex, et retirer l'URL de l'index.
Quelles erreurs éviter absolument dans cette démarche ?
Ne jamais bloquer robots.txt ET ajouter noindex simultanément — c'est une contradiction technique. Google ne peut pas lire votre balise si vous lui interdisez l'accès au HTML.
Autre piège : utiliser l'outil de suppression d'URL dans Search Console. C'est une solution temporaire (90 jours) qui ne règle rien structurellement. L'URL réapparaît si les backlinks persistent.
- Auditer les URLs bloquées via
site:et robots.txt - Retirer temporairement le blocage robots.txt des pages à désinscire
- Ajouter
noindexdans le HTML de ces pages - Attendre que Google retraite les URLs (suivre dans Search Console)
- Une fois désindexées, réappliquer robots.txt si nécessaire — mais privilégier noindex pour un contrôle durable
- Vérifier régulièrement avec
site:pour détecter de nouvelles apparitions
Comment prévenir ce problème à l'avenir ?
Adoptez une stratégie noindex par défaut pour tout contenu que vous ne souhaitez pas indexer. Robots.txt doit servir uniquement à gérer le crawl budget sur des sections techniques (admin, filtres infinis, fichiers médias).
Documentez clairement dans votre governance SEO : robots.txt = gestion du crawl, balises meta robots = gestion de l'indexation. Ne mélangez jamais les deux logiques.
❓ Questions frequentes
Peut-on utiliser robots.txt pour empêcher définitivement l'indexation d'une page ?
Combien de temps faut-il pour qu'une URL bloquée disparaisse de l'index Google ?
Si j'ajoute noindex après avoir bloqué robots.txt, est-ce que ça fonctionne ?
Comment détecter rapidement les URLs bloquées mais indexées sur mon site ?
Robots.txt est-il encore utile si noindex gère l'indexation ?
🎥 De la même vidéo 22
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 28/03/2022
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.