Declaration officielle
Autres déclarations de cette vidéo 22 ▾
- □ Pourquoi la position moyenne de Search Console ne reflète-t-elle pas un classement théorique mais des affichages réels ?
- □ Peut-on encore se permettre d'attendre qu'un classement instable se stabilise tout seul ?
- □ Faut-il vraiment produire plus de contenu pour améliorer son SEO ?
- □ Où placer son sitemap XML pour optimiser son crawl ?
- □ Faut-il vraiment utiliser l'outil d'inspection d'URL pour indexer un nouveau site ?
- □ Combien de temps faut-il attendre pour voir les backlinks dans Search Console ?
- □ Pourquoi les données Search Console et Analytics ne concordent-elles jamais vraiment ?
- □ Search Console collecte-t-elle vraiment toutes les données sur les gros sites e-commerce ?
- □ Faut-il vraiment préférer noindex à disallow pour contrôler l'indexation ?
- □ Les produits en rupture de stock peuvent-ils vraiment être traités comme des soft 404 par Google ?
- □ Google utilise-t-il des algorithmes différents selon votre secteur d'activité ?
- □ Pourquoi Google ignore-t-il les sites agrégateurs de faible effort ?
- □ Google compte-t-il vraiment les clics sur les rich results comme des clics organiques ?
- □ L'ordre des liens dans le HTML influence-t-il vraiment la priorité de crawl de Google ?
- □ Faut-il vraiment éviter les URLs avec paramètres pour le SEO ?
- □ Pourquoi robots.txt bloque le crawl mais n'empêche pas l'indexation de vos pages ?
- □ Les produits en rupture de stock nuisent-ils au classement global de votre site e-commerce ?
- □ Le contenu dupliqué partiel pénalise-t-il vraiment vos pages ?
- □ Pourquoi Google refuse-t-il d'indexer plusieurs versions d'une même page malgré une canonicalisation correcte ?
- □ Comment Google choisit-il réellement quelle URL canoniser parmi vos contenus dupliqués ?
- □ Les mentions de marque sans lien ont-elles une valeur SEO ?
- □ Pourquoi un lien sans URL indexée ne sert strictement à rien ?
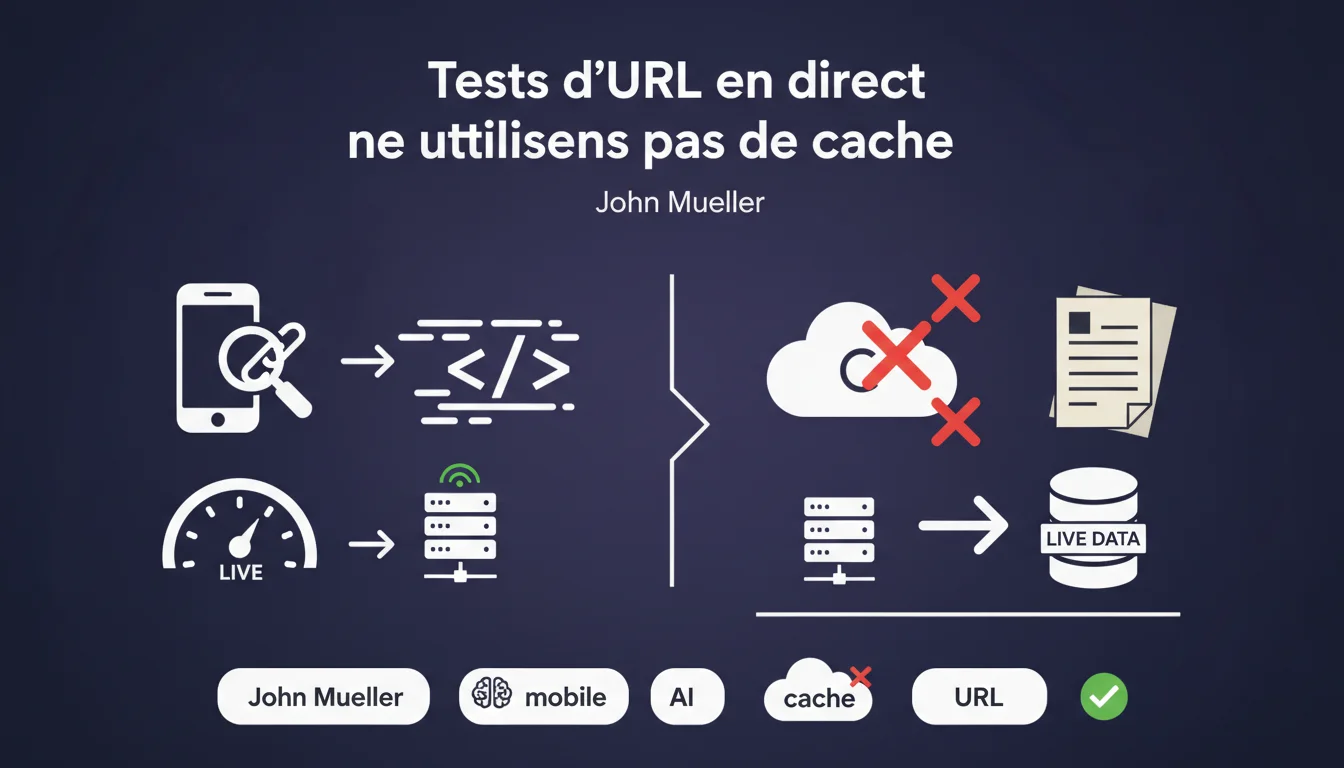
Mueller confirme que l'outil d'inspection d'URL et le test mobile-friendly récupèrent les données directement depuis votre serveur, sans cache intermédiaire. Autrement dit : ce que ces outils affichent reflète l'état exact de votre page au moment du test. Une clarification importante pour diagnostiquer les problèmes d'indexation sans faux positifs liés à des données périmées.
Ce qu'il faut comprendre
Pourquoi cette précision sur l'absence de cache ?
Beaucoup de professionnels SEO soupçonnaient que les outils de test — notamment l'outil d'inspection d'URL dans Search Console et le test mobile-friendly — utilisaient des données en cache pour gagner en rapidité. La logique semblait tenir : Google crawle déjà votre site, pourquoi refaire une requête complète à chaque test ?
Mueller met les points sur les i. Ces outils récupèrent les informations en direct, ce qui signifie qu'ils envoient une requête HTTP fraîche vers votre serveur chaque fois que vous lancez un test. Pas de données stockées, pas de version antérieure. Ce que vous voyez correspond à l'état actuel de la page.
Quels outils sont concernés exactement ?
La déclaration vise principalement deux outils : le test mobile-friendly (disponible publiquement) et l'outil d'inspection d'URL dans Google Search Console. Ces deux interfaces sont fréquemment utilisées pour vérifier si Google peut accéder et interpréter correctement une page.
D'autres outils Google — comme PageSpeed Insights ou Lighthouse — fonctionnent différemment et ne sont pas couverts par cette affirmation. Reste attentif au périmètre exact : on parle ici des outils de test de compatibilité et de crawl, pas des outils de performance.
Quelle différence avec le crawl classique de Googlebot ?
Le crawl standard de Googlebot suit des règles de crawl budget, de priorisation, et peut s'appuyer sur des données en cache pour certains éléments (comme les ressources statiques). Les outils de test, eux, ignorent ces contraintes : ils simulent un crawl complet pour vous donner une vue instantanée.
Cela explique pourquoi une page peut être indexée avec un rendu incomplet (Googlebot a utilisé une version en cache d'une ressource JS), alors que l'outil d'inspection affiche un rendu correct (il a tout récupéré en direct). Les deux comportements ne sont pas contradictoires — ils répondent à des logiques différentes.
- Les outils de test récupèrent toutes les données en temps réel, sans cache
- Le crawl classique peut utiliser des ressources en cache pour optimiser le budget
- Un test réussi dans l'outil d'inspection ne garantit pas un rendu identique lors de l'indexation
- Cette distinction explique certains décalages entre l'aperçu et l'index réel
Avis d'un expert SEO
Cette déclaration est-elle cohérente avec les observations terrain ?
Oui — et ça confirme des comportements que beaucoup d'entre nous avions déjà documentés. Quand vous corrigez un problème de robots.txt ou de balise meta robots, l'outil d'inspection reflète immédiatement le changement. Pas besoin d'attendre un nouveau crawl de Googlebot. C'est exactement ce qu'on attendrait d'un outil qui tape directement sur le serveur.
En revanche — et c'est là que ça coince —, cette absence de cache peut aussi masquer des problèmes réels. Si votre page met 8 secondes à répondre à cause d'une base de données surchargée, l'outil d'inspection attendra patiemment. Googlebot, lui, risque d'abandonner avant la fin. Le test vous dira "tout va bien", alors que l'indexation échoue en production.
Quelles nuances faut-il apporter ?
Premier point : l'outil d'inspection récupère les données en direct, mais il n'utilise pas forcément le même user-agent ni les mêmes priorités de ressources que Googlebot en production. Le résultat est fiable pour vérifier l'accessibilité, moins pour reproduire exactement le comportement d'indexation.
Deuxième point : Mueller parle de "récupérer les informations en direct", mais ça ne dit rien sur la durée de validité de ce test. Si vous lancez l'outil deux fois en 10 secondes, Google envoie-t-il deux requêtes distinctes ou conserve-t-il un résultat temporaire ? [A vérifier] — la déclaration reste floue sur ce détail opérationnel.
Dans quels cas cette règle pourrait-elle ne pas s'appliquer complètement ?
Si votre serveur applique des règles de rate limiting ou de blocage géographique, l'outil d'inspection peut obtenir un résultat différent de celui d'un utilisateur lambda — ou même de Googlebot en production. Les IP de Google pour les tests ne sont pas forcément les mêmes que celles du crawl standard.
Autre cas limite : les pages avec du contenu dynamique côté serveur (A/B testing, personnalisation par session). L'outil récupère "en direct", certes, mais quelle variante ? Si votre logique serveur change selon le contexte (heure, géolocalisation, cookies), le test peut afficher une version qui n'est jamais servie à Googlebot.
Impact pratique et recommandations
Que faut-il faire concrètement avec cette information ?
Utilise l'outil d'inspection d'URL comme un diagnostic en temps réel, pas comme une garantie d'indexation. C'est parfait pour vérifier qu'une correction technique (robots.txt, balise canonical, redirection) est bien appliquée. C'est insuffisant pour prévoir comment Googlebot se comportera à grande échelle.
Complète systématiquement un test d'inspection par une analyse des logs serveur. Tu veux savoir si Googlebot accède réellement à tes ressources critiques (CSS, JS) et dans quel ordre. Les logs te montrent la réalité du crawl, pas une simulation idéalisée.
Quelles erreurs éviter ?
Ne te fie pas aveuglément à un test positif si tu observes des problèmes d'indexation persistants. Le fait que l'outil affiche un rendu correct ne signifie pas que Googlebot obtient le même résultat en conditions réelles — surtout si ton serveur est lent ou instable.
Évite aussi de spammer l'outil avec des tests répétés toutes les 30 secondes. Même si Google récupère les données en direct, solliciter ton serveur en boucle peut déclencher des mécanismes de protection (rate limiting, WAF) qui fausseront les résultats. Laisse quelques minutes entre deux tests sur la même URL.
Comment vérifier que mon serveur répond correctement aux outils de test ?
Configure ton serveur pour logger spécifiquement les user-agents Google liés aux outils de test (Google-InspectionTool, Googlebot-Mobile pour le test mobile-friendly). Compare les temps de réponse et les codes HTTP retournés à ces bots par rapport à Googlebot standard.
Si tu constates des écarts — par exemple, des timeouts pour Googlebot mais pas pour l'outil d'inspection —, c'est le signe que ton infrastructure ne gère pas uniformément la charge. Creuse du côté du cache serveur, des workers PHP/Node, ou des limites de connexions simultanées.
- Utilise l'outil d'inspection pour valider les corrections techniques immédiates
- Complète par une analyse des logs serveur réels de Googlebot
- Ne lance pas de tests en rafale — espace-les de quelques minutes
- Surveille les temps de réponse pour les user-agents de test vs. Googlebot production
- Vérifie que ton infrastructure ne bloque pas ou ne ralentit pas les IP de Google de façon différenciée
- En cas de décalage entre test et indexation, cherche du côté des ressources externes (CDN, APIs)
❓ Questions frequentes
L'outil d'inspection d'URL envoie-t-il une requête serveur à chaque test ?
Un test réussi dans l'outil d'inspection garantit-il une indexation correcte ?
Le test mobile-friendly utilise-t-il aussi des données en temps réel ?
Pourquoi mes pages passent le test d'inspection mais ne s'indexent pas correctement ?
Puis-je utiliser ces outils pour forcer un recrawl immédiat ?
🎥 De la même vidéo 22
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 28/03/2022
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.