Why is your Search Console crawl budget skyrocketing for no apparent reason?
John Mueller
🎥 YouTube
Aug 2020
★★★
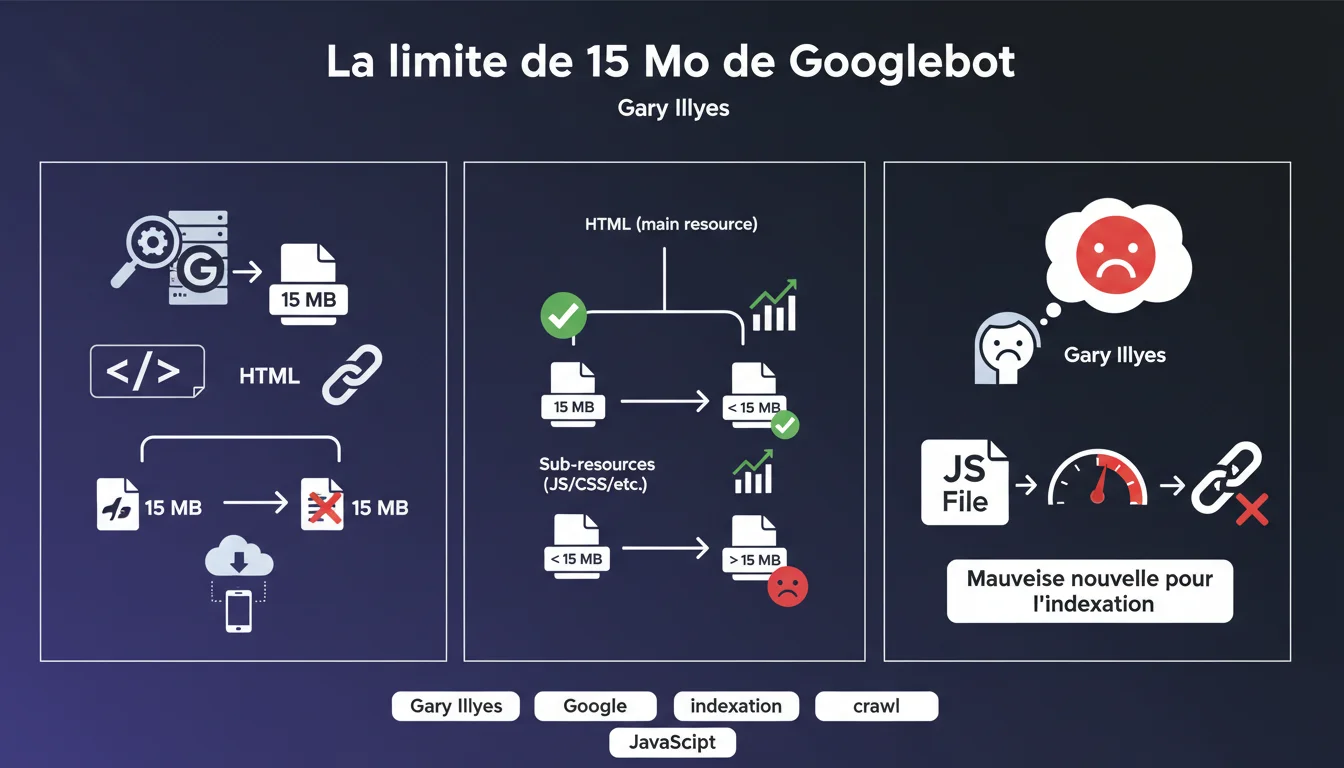
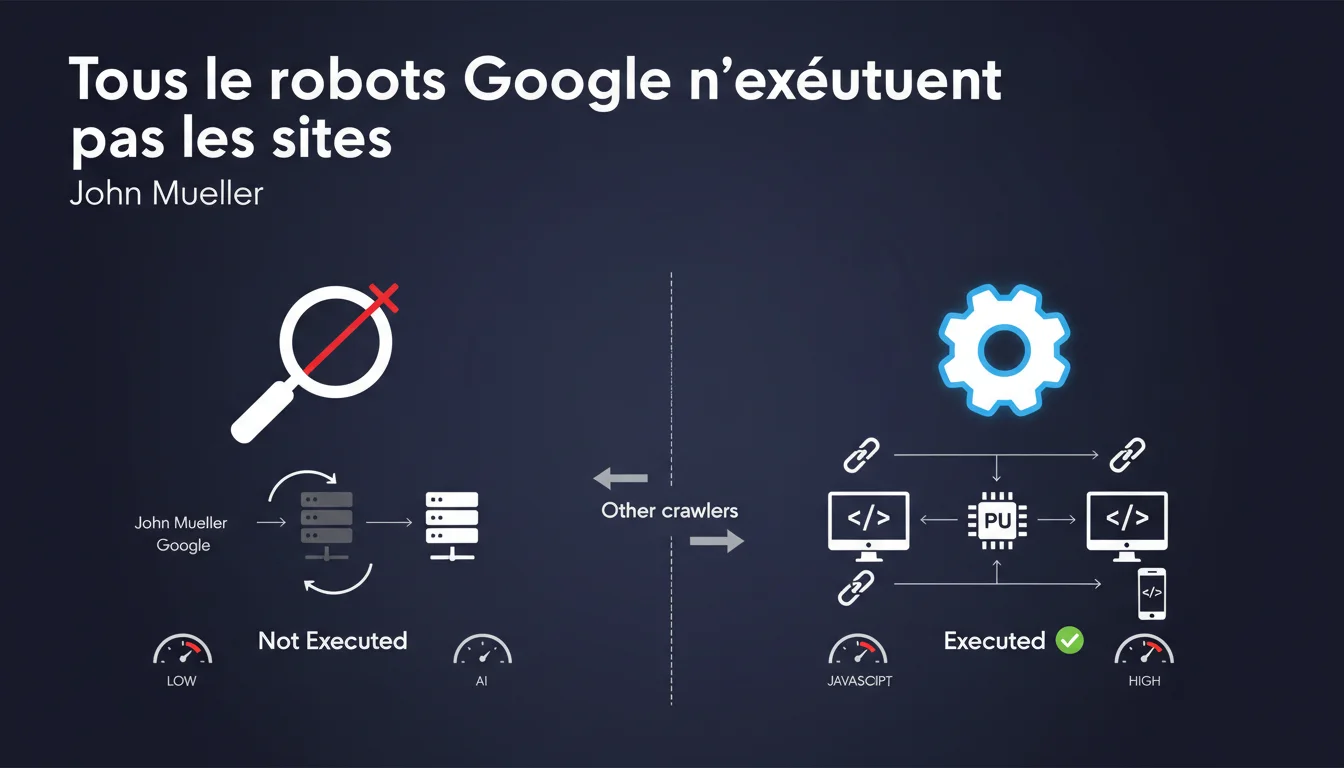
Le nombre d'URLs crawlées par jour dans Search Console inclut toutes les requêtes Googlebot : HTML, images, CSS, JavaScript, réponses serveu...