Official statement
Other statements from this video 10 ▾
- □ Pourquoi Googlebot refuse-t-il de crawler les pages HTML de plus de 15 Mo ?
- □ La balise title reste-t-elle vraiment un pilier du SEO malgré l'évolution des CMS ?
- □ Pourquoi Google remplace-t-il le First Input Delay par l'Interaction to Next Paint dans les Core Web Vitals ?
- □ Faut-il vraiment arrêter d'optimiser pour les Core Web Vitals ?
- □ Pourquoi Google sépare-t-il Googlebot et Google-Other dans ses crawls ?
- □ Google-Extended est-il vraiment un token et non un crawler ?
- □ Pourquoi Google vérifie-t-il 4 milliards de robots.txt chaque jour ?
- □ Les principes d'IA de Google s'appliquent-ils vraiment aux résultats de recherche ?
- □ Peut-on vraiment faire confiance aux contenus générés par l'IA pour le SEO ?
- □ Comment Google veut-il encadrer l'usage de l'IA dans la création de contenu ?
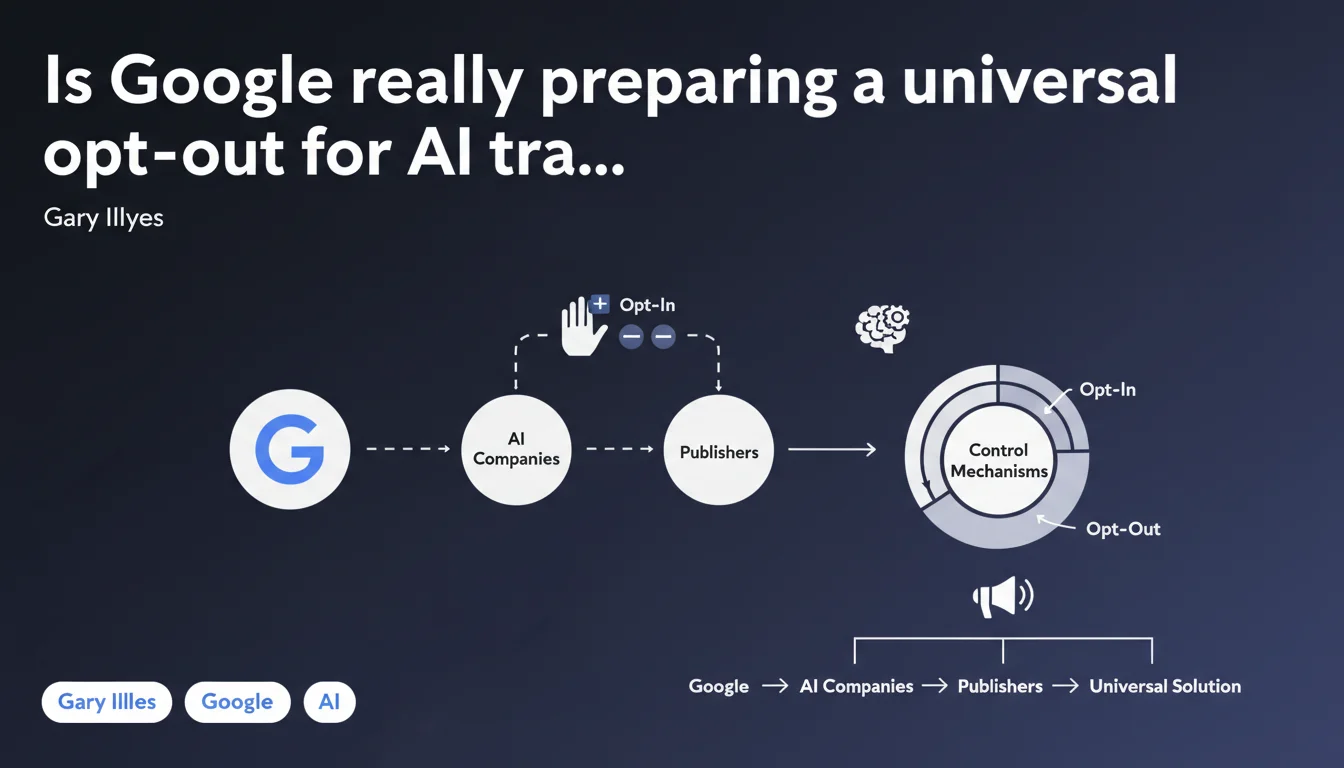
Google announces it's working on mechanisms allowing publishers to choose whether their content feeds into AI training. The goal: unified controls developed with other AI players to avoid multiplying tags and robots.txt directives. A statement that remains vague on timeline and concrete terms.
What you need to understand
Why is Google suddenly talking about AI training controls?
The context is straightforward: publishers are complaining. For months, they've watched their content being scraped by AI crawlers without the ability to exercise granular control. Current solutions — blocking via robots.txt or meta robots — are binary: all or nothing.
Google is trying to calm things down by promising more flexible mechanisms. But the wording remains vague: no timeline, no technical specifications, just a stated intention. For now, we're still at the communication stage.
What does a "unified control" actually mean in concrete terms?
The idea would be to prevent each AI company from imposing its own system. Imagine having to manage a different robots.txt for GPT, Gemini, Claude, LLaMA… The complexity would explode.
A unified standard would allow you to declare once and for all: "My content can be crawled for search but not for training". Or vice versa. But be careful: this assumes all players follow the rules. And nothing guarantees that an actor outside the system will respect these guidelines.
What are the key takeaways?
- Google is working on opt-in/opt-out mechanisms for AI training
- These solutions must be developed in collaboration with other AI companies and publishers
- Goal: avoid the chaotic multiplication of tags and technical directives
- No timeline or technical details have been communicated
- Current solutions (robots.txt, meta robots) remain the only available tools to date
SEO Expert opinion
Is this statement credible or just spin?
Let's be honest: this is a pretty thin announcement. No roadmap, no RFC, not even a sketch of technical specifications. Just a vaguely worded intention.
On one hand, Google has an incentive to standardize to avoid chaos. On the other hand, OpenAI, Anthropic, or Meta have no obligation to follow what Google proposes. [To verify]: are these actors actually participating in discussions or is this just wishful thinking on Google's part?
What nuances need to be added?
First nuance: Google Search and Google AI are two distinct entities. A control allowing you to block training could theoretically have no impact on traditional search ranking. But in practice, who knows how Google will actually handle this distinction?
Second nuance: an opt-out doesn't erase what's already been crawled. If your content fed into GPT-4 or Gemini v1, it will remain there. We're talking about controlling the future, not repairing the past.
Third point — and it sticks: no technical mechanism will ever prevent a malicious actor from crawling without respecting the rules. These controls only work if everyone plays fair. Naive?
In what cases does this approach pose problems?
The major risk is fragmentation. If each AI player implements its own system despite everything, publishers will end up with unmanageable complexity. And guess who suffers? Small sites that lack both tech teams and resources to keep up.
Practical impact and recommendations
What should you do concretely today?
For now: nothing new. The only tools at your disposal remain robots.txt and meta robots. If you want to block known AI crawlers, add specific user-agents (GPTBot, Google-Extended, Anthropic-AI, etc.).
But be careful: blocking Google-Extended could impact certain AI features in Google Search. The exact consequences aren't officially documented. [To verify] through field testing.
What mistakes should you avoid while waiting for official controls?
First mistake: believing this announcement changes something right now. It doesn't. It's an intention, not a deployed feature.
Second mistake: blindly blocking all AI bots without understanding the impact. Some crawlers are linked to enriched search features. Block the wrong one, and you could potentially lose search visibility.
Third mistake: not monitoring your crawl budget. AI bots can be resource-hungry. If you notice a spike in crawling without added value, act via robots.txt or server-side rate-limiting.
How should you prepare for future control mechanisms?
- Audit your current robots.txt and clearly document your blocking/authorization strategy
- Monitor official announcements on Google Search Central and standards working groups (W3C, IETF)
- Test the impact of blocking Google-Extended on a subset of pages before global deployment
- Set up monitoring of user-agents crawling your site to identify new AI bots
- Create clear internal documentation of your policy regarding AI training
- Stay informed about concrete implementations from other players (OpenAI, Anthropic, Meta)
❓ Frequently Asked Questions
Bloquer Google-Extended impacte-t-il le référencement classique ?
Quels user-agents dois-je bloquer pour éviter le training IA ?
Un opt-out supprime-t-il mes contenus déjà utilisés pour le training ?
Cette annonce a-t-elle une date de mise en œuvre ?
Les autres acteurs IA vont-ils vraiment collaborer avec Google ?
🎥 From the same video 10
Other SEO insights extracted from this same Google Search Central video · published on 21/12/2023
🎥 Watch the full video on YouTube →
💬 Comments (0)
Be the first to comment.