Declaration officielle
Autres déclarations de cette vidéo 10 ▾
- □ Pourquoi Googlebot refuse-t-il de crawler les pages HTML de plus de 15 Mo ?
- □ La balise title reste-t-elle vraiment un pilier du SEO malgré l'évolution des CMS ?
- □ Pourquoi Google remplace-t-il le First Input Delay par l'Interaction to Next Paint dans les Core Web Vitals ?
- □ Faut-il vraiment arrêter d'optimiser pour les Core Web Vitals ?
- □ Pourquoi Google sépare-t-il Googlebot et Google-Other dans ses crawls ?
- □ Google-Extended est-il vraiment un token et non un crawler ?
- □ Pourquoi Google vérifie-t-il 4 milliards de robots.txt chaque jour ?
- □ Les principes d'IA de Google s'appliquent-ils vraiment aux résultats de recherche ?
- □ Peut-on vraiment faire confiance aux contenus générés par l'IA pour le SEO ?
- □ Comment Google veut-il encadrer l'usage de l'IA dans la création de contenu ?
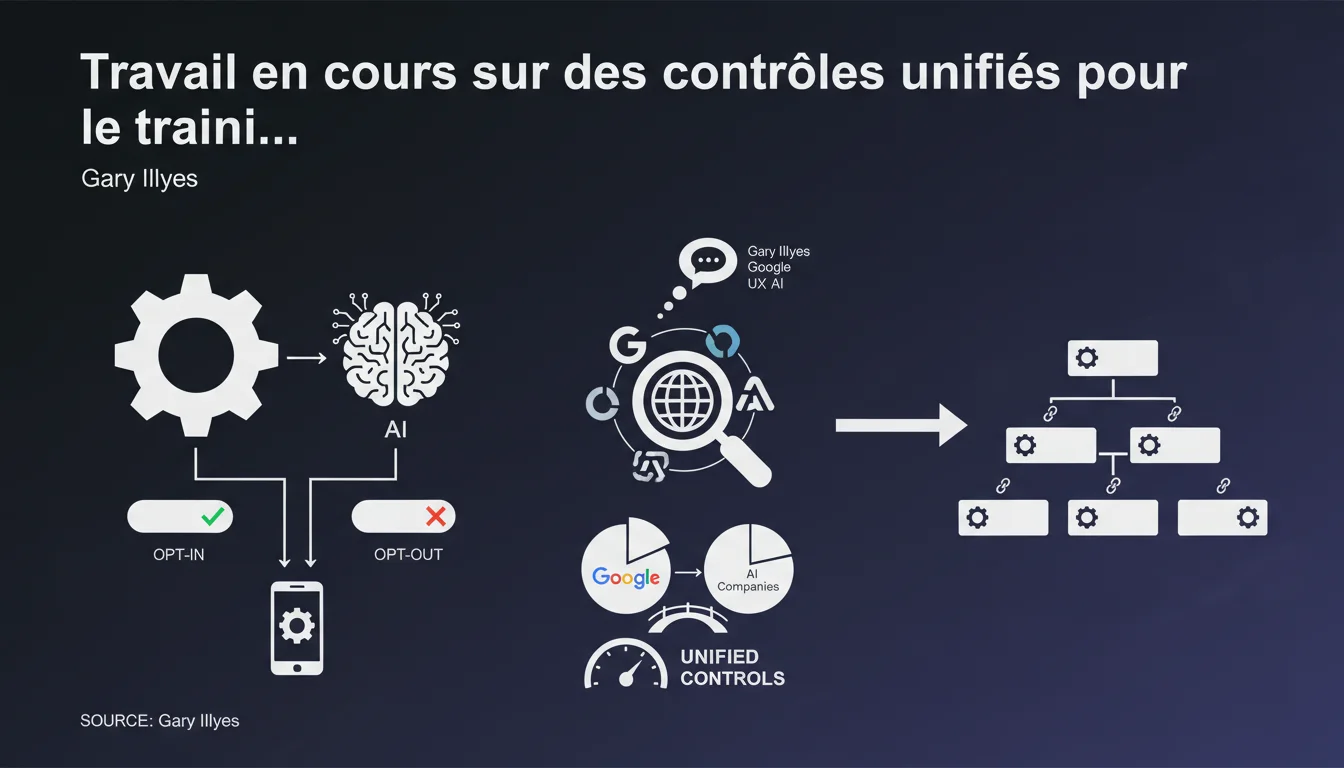
Google annonce travailler sur des mécanismes permettant aux éditeurs de choisir si leurs contenus alimentent le training IA. L'objectif : des contrôles unifiés développés avec d'autres acteurs IA pour éviter de multiplier les balises et robots.txt. Une déclaration qui reste floue sur le calendrier et les modalités concrètes.
Ce qu'il faut comprendre
Pourquoi Google parle-t-il soudainement de contrôles pour le training IA ?
Le contexte est simple : les éditeurs râlent. Depuis des mois, ils voient leurs contenus aspirés par des crawlers IA sans possibilité de contrôle granulaire. Les solutions actuelles — bloquer via robots.txt ou meta robots — sont binaires : tout ou rien.
Google tente de calmer le jeu en promettant des mécanismes plus souples. Mais la formulation reste vague : aucune date, aucune spécification technique, juste une intention affichée. Pour l'instant, on reste au stade de la communication.
Que signifie concrètement un « contrôle unifié » ?
L'idée serait d'éviter que chaque entreprise IA impose son propre système. Imagine devoir gérer un robots.txt différent pour GPT, Gemini, Claude, LLaMA… La complexité exploserait.
Un standard unifié permettrait de déclarer une fois pour toutes : « Mon contenu peut être crawlé pour la recherche mais pas pour le training ». Ou inversement. Mais attention : cela suppose que tous les acteurs jouent le jeu. Et rien ne garantit qu'un acteur hors système respectera ces règles.
Quels sont les points essentiels à retenir ?
- Google travaille sur des mécanismes opt-in/opt-out pour le training IA
- Ces solutions doivent être développées en collaboration avec d'autres entreprises IA et éditeurs
- Objectif : éviter la multiplication anarchique de balises et directives techniques
- Aucun calendrier ni détail technique n'a été communiqué
- Les solutions actuelles (robots.txt, meta robots) restent les seuls outils disponibles à ce jour
Avis d'un expert SEO
Cette déclaration est-elle crédible ou simplement de la communication ?
Soyons honnêtes : c'est très léger comme annonce. Pas de roadmap, pas de RFC, pas même une ébauche de spécification technique. Juste une intention vaguement formulée.
D'un côté, Google a intérêt à standardiser pour éviter le chaos. De l'autre, OpenAI, Anthropic ou Meta n'ont aucune obligation de suivre ce que Google propose. [À vérifier] : est-ce que ces acteurs participent réellement aux discussions ou est-ce juste du wishful thinking de la part de Google ?
Quelles nuances faut-il apporter ?
Première nuance : Google Search et Google AI sont deux entités distinctes. Un contrôle permettant de bloquer le training pourrait théoriquement n'avoir aucun impact sur le référencement classique. Mais dans les faits, qui sait comment Google gérera réellement cette distinction ?
Deuxième nuance : un opt-out n'efface pas ce qui a déjà été crawlé. Si ton contenu a alimenté GPT-4 ou Gemini v1, il y restera. On parle ici de contrôler l'avenir, pas de réparer le passé.
Troisième point — et il coince : aucun mécanisme technique n'empêchera jamais un acteur malveillant de crawler sans respecter les règles. Ces contrôles ne fonctionnent que si tout le monde joue fair-play. Naïf ?
Dans quels cas cette approche pose-t-elle problème ?
Le risque majeur, c'est la fragmentation. Si chaque acteur IA implémente son propre système malgré tout, on se retrouvera avec une complexité ingérable côté éditeur. Et devine qui trinque ? Les petits sites qui n'ont ni équipe tech ni ressources pour suivre.
Impact pratique et recommandations
Que faut-il faire concrètement aujourd'hui ?
Pour l'instant : rien de nouveau. Les seuls outils à ta disposition restent robots.txt et les meta robots. Si tu veux bloquer les crawlers IA connus, ajoute les user-agents spécifiques (GPTBot, Google-Extended, Anthropic-AI, etc.).
Mais attention : bloquer Google-Extended pourrait impacter certaines fonctionnalités IA de Google Search. Les conséquences exactes ne sont pas documentées officiellement. [À vérifier] sur des tests terrain.
Quelles erreurs éviter en attendant des contrôles officiels ?
Première erreur : croire que cette annonce change quelque chose dès maintenant. Elle ne change rien. C'est une intention, pas une fonctionnalité déployée.
Deuxième erreur : bloquer aveuglément tous les bots IA sans comprendre l'impact. Certains crawlers sont liés à des fonctionnalités de recherche enrichie. Bloque le mauvais, et tu perds potentiellement de la visibilité.
Troisième erreur : ne pas monitorer ton crawl budget. Les bots IA peuvent être gourmands. Si tu constates une explosion du crawl sans valeur ajoutée, agis via robots.txt ou rate-limiting serveur.
Comment se préparer aux futurs mécanismes de contrôle ?
- Audite ton robots.txt actuel et documente clairement ta stratégie de blocage/autorisation
- Surveille les annonces officielles sur Google Search Central et les groupes de travail standards (W3C, IETF)
- Teste l'impact du blocage de Google-Extended sur un sous-ensemble de pages avant déploiement global
- Mets en place un monitoring des user-agents crawlant ton site pour identifier de nouveaux bots IA
- Prépare une documentation interne claire sur ta politique vis-à-vis du training IA
- Reste en veille sur les implémentations concrètes des autres acteurs (OpenAI, Anthropic, Meta)
❓ Questions frequentes
Bloquer Google-Extended impacte-t-il le référencement classique ?
Quels user-agents dois-je bloquer pour éviter le training IA ?
Un opt-out supprime-t-il mes contenus déjà utilisés pour le training ?
Cette annonce a-t-elle une date de mise en œuvre ?
Les autres acteurs IA vont-ils vraiment collaborer avec Google ?
🎥 De la même vidéo 10
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 21/12/2023
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.