Declaration officielle
Autres déclarations de cette vidéo 10 ▾
- □ Pourquoi Googlebot refuse-t-il de crawler les pages HTML de plus de 15 Mo ?
- □ La balise title reste-t-elle vraiment un pilier du SEO malgré l'évolution des CMS ?
- □ Pourquoi Google remplace-t-il le First Input Delay par l'Interaction to Next Paint dans les Core Web Vitals ?
- □ Faut-il vraiment arrêter d'optimiser pour les Core Web Vitals ?
- □ Google-Extended est-il vraiment un token et non un crawler ?
- □ Google prépare-t-il vraiment un opt-out universel pour le training IA ?
- □ Pourquoi Google vérifie-t-il 4 milliards de robots.txt chaque jour ?
- □ Les principes d'IA de Google s'appliquent-ils vraiment aux résultats de recherche ?
- □ Peut-on vraiment faire confiance aux contenus générés par l'IA pour le SEO ?
- □ Comment Google veut-il encadrer l'usage de l'IA dans la création de contenu ?
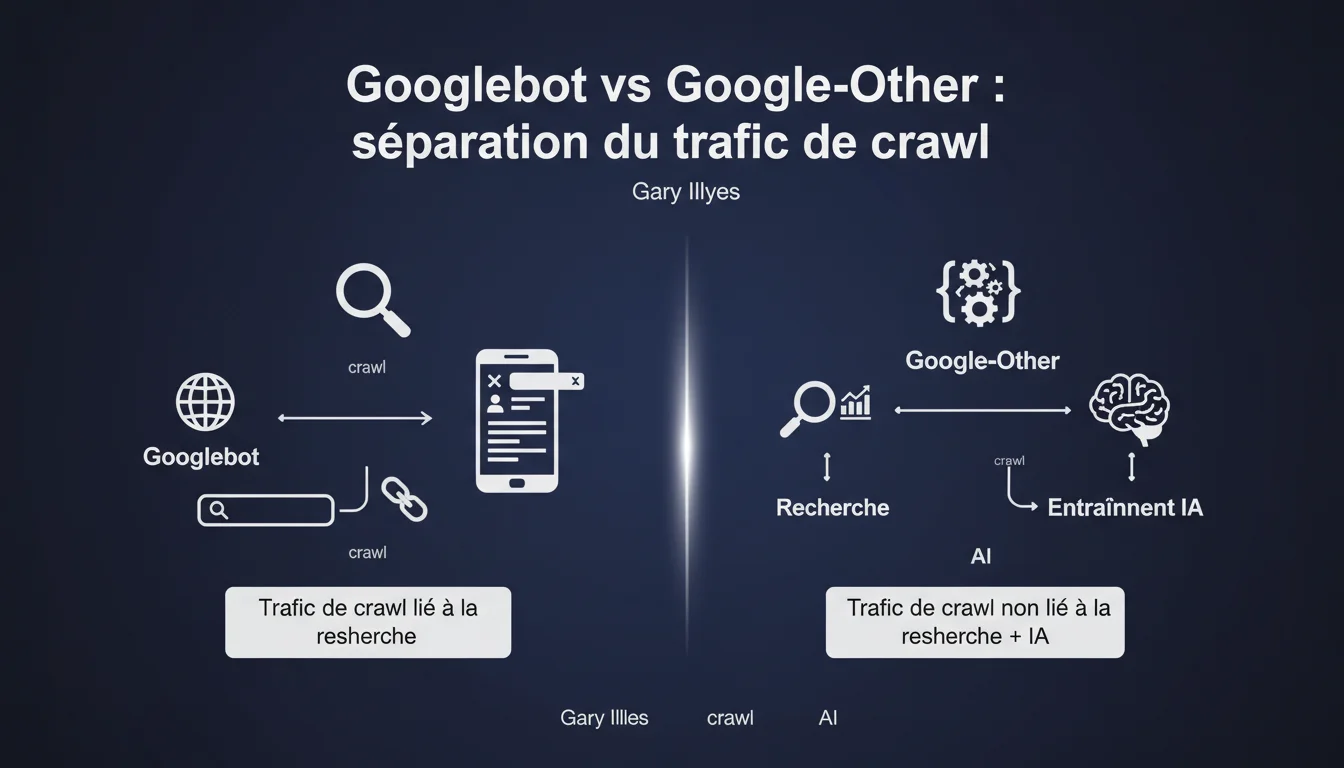
Google introduit Google-Other, un user-agent distinct de Googlebot, pour isoler le trafic de crawl non lié à la recherche. Googlebot reste désormais exclusivement dédié au crawl pour l'indexation, tandis que Google-Other gère d'autres activités incluant l'entraînement de modèles d'IA. Cette séparation permet aux webmasters de mieux contrôler et monitorer le trafic de crawl sur leurs serveurs.
Ce qu'il faut comprendre
Qu'est-ce que Google-Other exactement ?
Google-Other est un nouveau user-agent créé pour identifier le trafic de crawl qui n'a pas de lien direct avec l'indexation pour la recherche. Avant cette séparation, Googlebot regroupait tous les types de crawl Google, rendant difficile la distinction entre ce qui servait réellement au référencement et ce qui relevait d'autres usages internes.
Concrètement, Google-Other couvre des activités comme la recherche interne chez Google et certaines tâches d'entraînement de modèles d'IA. Cette distinction technique n'est pas anodine : elle permet de tracer une ligne claire entre ce qui impacte votre visibilité organique et ce qui n'en relève pas.
Pourquoi cette séparation a-t-elle du sens pour Google ?
La multiplication des usages de crawl chez Google — notamment avec l'essor de l'IA générative — créait une confusion croissante dans les logs serveur. Les webmasters voyaient du trafic Googlebot sans comprendre si cela contribuait à leur indexation ou servait d'autres objectifs.
En isolant Google-Other, Google clarifie son propre fonctionnement et facilite le monitoring côté webmaster. C'est aussi une manière d'éviter que des activités de crawl intensif pour l'IA soient perçues comme du gaspillage de crawl budget destiné à la recherche.
Quel impact sur le crawl budget traditionnel ?
Théoriquement, si Google-Other gère du trafic qui était auparavant attribué à Googlebot, cela devrait réduire la charge apparente sur le user-agent principal. Mais attention : ça ne change rien au volume total de requêtes HTTP que vos serveurs reçoivent de Google.
La vraie différence, c'est que vous pouvez maintenant analyser séparément le comportement de ces deux bots. Si Google-Other crawle massivement des pages peu stratégiques, vous le verrez immédiatement dans vos logs — et vous pourrez agir en conséquence via robots.txt ou la Search Console.
- Google-Other n'est pas lié à l'indexation pour la recherche organique
- Googlebot devient exclusivement dédié au crawl pour le référencement
- Cette séparation améliore la transparence et le contrôle des webmasters sur leur trafic
- Le volume total de crawl Google ne diminue pas nécessairement
- Vous pouvez gérer ces deux user-agents de manière indépendante dans robots.txt
Avis d'un expert SEO
Cette déclaration est-elle cohérente avec les pratiques observées sur le terrain ?
Sur le principe, oui. Les SEO aguerris ont remarqué depuis plusieurs mois une diversification des patterns de crawl dans leurs logs, avec des comportements atypiques ne correspondant pas aux cycles d'indexation classiques. La création de Google-Other officialise ce que certains soupçonnaient déjà.
Là où ça coince, c'est sur la transparence des critères : Gary Illyes ne précise pas exactement quelles activités relèvent de Google-Other au-delà de « la recherche et certaines activités d'entraînement d'IA ». [A vérifier] sur le terrain : quels types de pages Google-Other privilégie-t-il ? Quelle est la fréquence réelle de ce crawl comparé à Googlebot ?
Quelles nuances faut-il apporter à cette annonce ?
Premier point : cette séparation ne signifie pas que Google-Other est négligeable. Si votre site sert à entraîner des modèles d'IA, c'est potentiellement stratégique pour votre visibilité future dans les résultats enrichis par IA (SGE, Bard, etc.). Bloquer aveuglément Google-Other pourrait avoir des effets de bord.
Deuxième nuance : la distinction Googlebot/Google-Other reste floue dans certains cas limites. Par exemple, le crawl pour les featured snippets ou les rich results est-il toujours du Googlebot pur, ou certains aspects peuvent-ils basculer vers Google-Other ? Google ne le dit pas. [A vérifier] dans vos propres logs.
Dans quels cas cette règle pourrait-elle ne pas s'appliquer comme prévu ?
Si vous gérez un site à faible crawl budget, la séparation Googlebot/Google-Other ne changera probablement rien à votre quotidien — vous verrez simplement deux user-agents au lieu d'un, sans réel impact sur la fréquence totale de crawl.
En revanche, sur les gros sites avec des millions de pages, cette distinction peut révéler des patterns cachés : par exemple, Google-Other pourrait crawler massivement des archives ou du contenu dupliqué que Googlebot ignore déjà. Ça devient un signal actionnable pour optimiser votre architecture.
Impact pratique et recommandations
Que faut-il faire concrètement avec ces deux user-agents ?
Première étape : segmentez vos logs serveur pour identifier distinctement le trafic Googlebot et Google-Other. Comparez les volumes, les pages crawlées, les fréquences. C'est le seul moyen de savoir si Google-Other impacte réellement votre infrastructure.
Si Google-Other consomme des ressources significatives sur des sections non stratégiques, vous pouvez le bloquer sélectivement via robots.txt. Mais ne le bloquez pas par défaut : analysez d'abord son comportement pendant au moins un mois.
Quelles erreurs éviter dans la gestion de Google-Other ?
Erreur classique : traiter Google-Other comme un bot parasite et le bloquer immédiatement. Vous risquez de vous couper de futures opportunités dans l'écosystème IA de Google, notamment pour les réponses enrichies ou les citations dans SGE.
Autre piège : ignorer complètement Google-Other sous prétexte qu'il n'impacte pas l'indexation. Si ce bot crawle intensément votre site, il consomme de la bande passante et des ressources serveur — c'est un coût réel qu'il faut monitorer.
Comment vérifier que votre site gère correctement ces deux bots ?
Installez un monitoring des user-agents dans vos logs (Apache, Nginx, ou via un outil comme Screaming Frog Log Analyzer). Identifiez les patterns de crawl pour Googlebot et Google-Other séparément.
Vérifiez également dans la Search Console si Google signale des erreurs de crawl spécifiques à l'un ou l'autre user-agent. Certains paramètres de serveur (rate limiting, cache) peuvent traiter différemment ces deux bots.
- Segmentez vos logs pour isoler Googlebot et Google-Other
- Analysez les pages crawlées par chaque bot sur une période de 30 jours minimum
- Ne bloquez pas Google-Other par défaut — évaluez d'abord son impact
- Surveillez la consommation de bande passante et de ressources serveur
- Adaptez votre robots.txt uniquement si Google-Other crawle des sections non stratégiques de manière excessive
- Documentez les patterns observés pour ajuster votre stratégie au fil du temps
❓ Questions frequentes
Google-Other compte-t-il dans le crawl budget de mon site ?
Puis-je bloquer Google-Other sans risque pour mon référencement ?
Comment différencier Googlebot et Google-Other dans mes logs serveur ?
Google-Other peut-il crawler mon site plus fréquemment que Googlebot ?
Cette séparation change-t-elle quelque chose pour les petits sites ?
🎥 De la même vidéo 10
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 21/12/2023
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.