Declaration officielle
Autres déclarations de cette vidéo 10 ▾
- □ Pourquoi Googlebot refuse-t-il de crawler les pages HTML de plus de 15 Mo ?
- □ La balise title reste-t-elle vraiment un pilier du SEO malgré l'évolution des CMS ?
- □ Pourquoi Google remplace-t-il le First Input Delay par l'Interaction to Next Paint dans les Core Web Vitals ?
- □ Faut-il vraiment arrêter d'optimiser pour les Core Web Vitals ?
- □ Pourquoi Google sépare-t-il Googlebot et Google-Other dans ses crawls ?
- □ Google prépare-t-il vraiment un opt-out universel pour le training IA ?
- □ Pourquoi Google vérifie-t-il 4 milliards de robots.txt chaque jour ?
- □ Les principes d'IA de Google s'appliquent-ils vraiment aux résultats de recherche ?
- □ Peut-on vraiment faire confiance aux contenus générés par l'IA pour le SEO ?
- □ Comment Google veut-il encadrer l'usage de l'IA dans la création de contenu ?
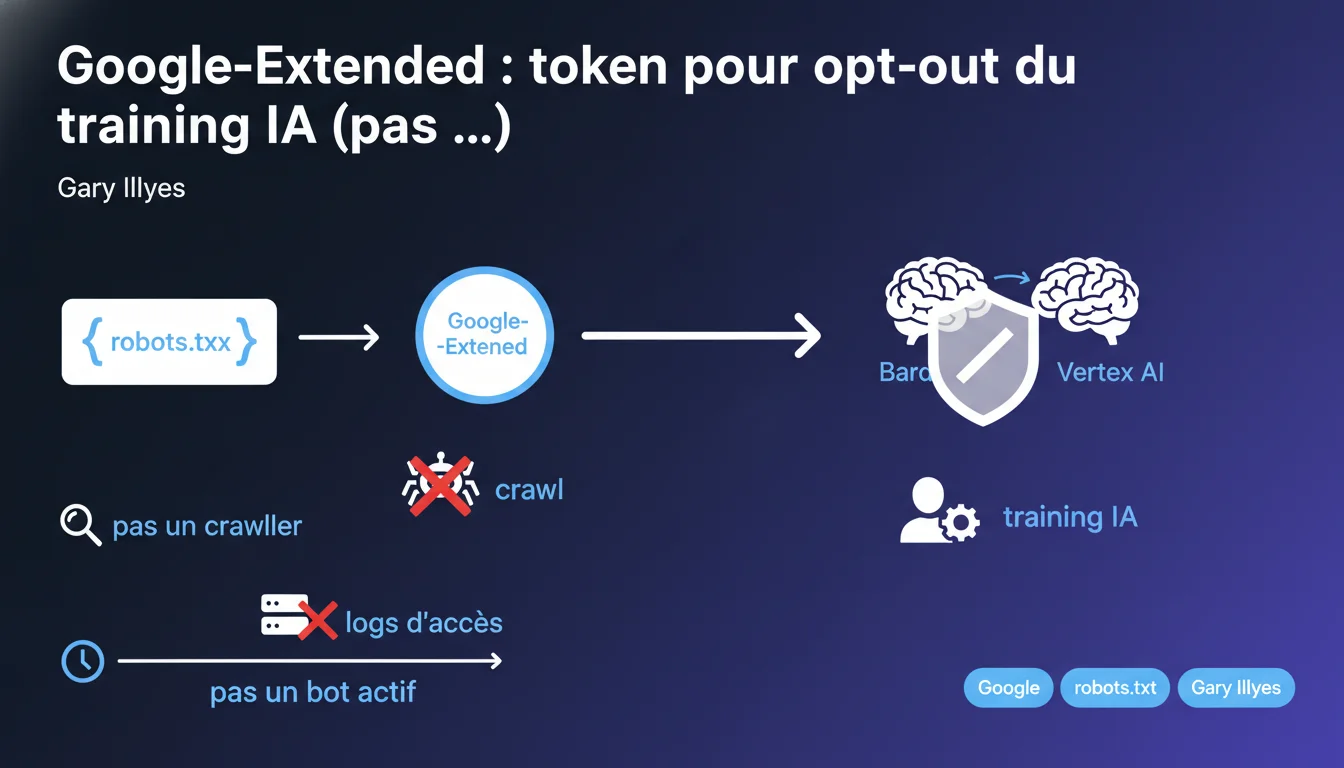
Google-Extended n'est pas un bot qui crawle activement vos pages : c'est un simple token dans robots.txt permettant d'exclure votre contenu du training des modèles IA (Bard, Vertex AI). Conséquence directe : il n'apparaîtra jamais dans vos logs serveur. Cette clarification règle le débat sur sa nature technique et son impact réel sur l'infrastructure.
Ce qu'il faut comprendre
Quelle est la différence entre un crawler et un token de produit ?
Un crawler est un agent logiciel actif qui envoie des requêtes HTTP à votre serveur, explore vos URLs et laisse des traces dans vos logs d'accès. Il consomme du crawl budget et génère de la charge serveur.
Un token de produit comme Google-Extended n'exécute aucune action directe. Il s'agit d'un identifiant déclaratif dans votre fichier robots.txt que Google lit pour déterminer si votre contenu peut être utilisé pour entraîner ses modèles IA. Pas de requête autonome, pas de trace dans les logs.
Comment Google utilise-t-il ce token concrètement ?
Lorsque Googlebot (le vrai crawler) visite votre site, il consulte votre robots.txt. Si celui-ci contient une directive bloquant Google-Extended, Google marquera le contenu collecté comme non exploitable pour le training IA.
Le crawl lui-même reste effectué par Googlebot classique. Google-Extended agit comme un flag de permission post-crawl, pas comme un agent de collecte distinct.
Quels sont les points essentiels à retenir ?
- Google-Extended ne crawle pas : c'est une directive de consentement, pas un bot
- Il ne consomme aucun crawl budget ni ressource serveur directement
- Bloquer Google-Extended n'empêche pas le crawl de Googlebot — il empêche uniquement l'usage des données pour l'IA
- Cette distinction est cruciale pour diagnostiquer correctement les patterns de crawl dans vos logs
- Le token s'applique spécifiquement à Bard et Vertex AI, pas au search classique
Avis d'un expert SEO
Cette déclaration est-elle cohérente avec les observations terrain ?
Oui, et elle résout d'ailleurs plusieurs confusions. Certains webmasters scrutaient leurs logs en cherchant un user-agent "Google-Extended" et s'inquiétaient de ne rien trouver. La clarification de Gary Illyes confirme ce qui se déduisait déjà de l'architecture : aucune trace ne peut exister puisqu'il n'y a pas d'activité réseau propre.
Cette logique s'aligne avec le fonctionnement des autres tokens de contrôle (NOODP, NOYDIR à l'époque) : ce sont des métadonnées interprétées par les systèmes Google, pas des crawlers.
Quelles nuances faut-il apporter à cette annonce ?
La distinction token/crawler ne dit rien sur quand et comment Google collecte réellement les données pour l'IA. Le mécanisme de crawl reste opaque : est-ce Googlebot classique qui extrait tout ? Y a-t-il un traitement différencié des contenus selon le token ? [A vérifier] sur le pipeline exact entre crawl et ingestion dans les datasets de training.
Autre angle mort : cette déclaration ne précise pas si bloquer Google-Extended a un impact indirect sur le ranking. Certains craignent qu'opt-outer du training IA signale un manque de coopération avec l'écosystème Google. Rien ne l'atteste, mais rien ne l'infirme non plus.
Dans quels cas cette règle pourrait-elle être mal comprise ?
Un site bloquant Google-Extended pourrait croire qu'il réduit ainsi sa charge serveur ou protège son crawl budget. Erreur : Googlebot continuera de crawler normalement. Le token n'a d'effet que sur l'usage post-collecte des données.
Autre piège : confondre Google-Extended avec un mécanisme de protection contre le scraping ou la republication. Ce n'est pas un DRM. Un concurrent peut toujours aspirer votre contenu — le token ne concerne que Google et ses modèles IA internes.
Impact pratique et recommandations
Que faut-il faire concrètement avec Google-Extended ?
D'abord, décider si vous voulez autoriser l'usage de votre contenu pour entraîner les modèles IA de Google. C'est une question stratégique et éditoriale avant d'être technique.
Si vous refusez, ajoutez à votre robots.txt :
User-agent: Google-Extended Disallow: /
Si vous acceptez, aucune action n'est nécessaire — l'opt-in est la position par défaut. Vous pouvez aussi autoriser partiellement certaines sections du site.
Quelles erreurs éviter dans la configuration ?
Ne confondez pas Google-Extended avec Googlebot. Bloquer User-agent: Googlebot désindexe votre site — bloquer Google-Extended ne fait qu'exclure du training IA.
Évitez aussi de surveiller vos logs en cherchant un user-agent Google-Extended. Comme précisé par Gary Illyes, il n'apparaîtra jamais. Si vous voyez du trafic suspect, c'est autre chose.
Comment vérifier que la directive est bien appliquée ?
Google ne fournit aucun outil de validation spécifique pour Google-Extended (contrairement à l'outil de test robots.txt pour Googlebot). Vous pouvez néanmoins :
- Vérifier la syntaxe de votre robots.txt avec un validateur standard
- Tester l'accessibilité du fichier via
votresite.com/robots.txt - Documenter votre choix dans une politique de données si pertinent pour votre audience
- Surveiller les communications officielles de Google pour d'éventuels outils de reporting futurs [A vérifier]
❓ Questions frequentes
Bloquer Google-Extended empêche-t-il Googlebot de crawler mon site ?
Puis-je voir Google-Extended dans mes logs serveur ?
Bloquer Google-Extended a-t-il un impact sur mon ranking dans la recherche ?
Google-Extended s'applique-t-il uniquement à Bard et Vertex AI ?
Puis-je autoriser partiellement certaines sections de mon site pour le training IA ?
🎥 De la même vidéo 10
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 21/12/2023
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.