Official statement
Other statements from this video 10 ▾
- □ Pourquoi Googlebot refuse-t-il de crawler les pages HTML de plus de 15 Mo ?
- □ La balise title reste-t-elle vraiment un pilier du SEO malgré l'évolution des CMS ?
- □ Pourquoi Google remplace-t-il le First Input Delay par l'Interaction to Next Paint dans les Core Web Vitals ?
- □ Faut-il vraiment arrêter d'optimiser pour les Core Web Vitals ?
- □ Pourquoi Google sépare-t-il Googlebot et Google-Other dans ses crawls ?
- □ Google prépare-t-il vraiment un opt-out universel pour le training IA ?
- □ Pourquoi Google vérifie-t-il 4 milliards de robots.txt chaque jour ?
- □ Les principes d'IA de Google s'appliquent-ils vraiment aux résultats de recherche ?
- □ Peut-on vraiment faire confiance aux contenus générés par l'IA pour le SEO ?
- □ Comment Google veut-il encadrer l'usage de l'IA dans la création de contenu ?
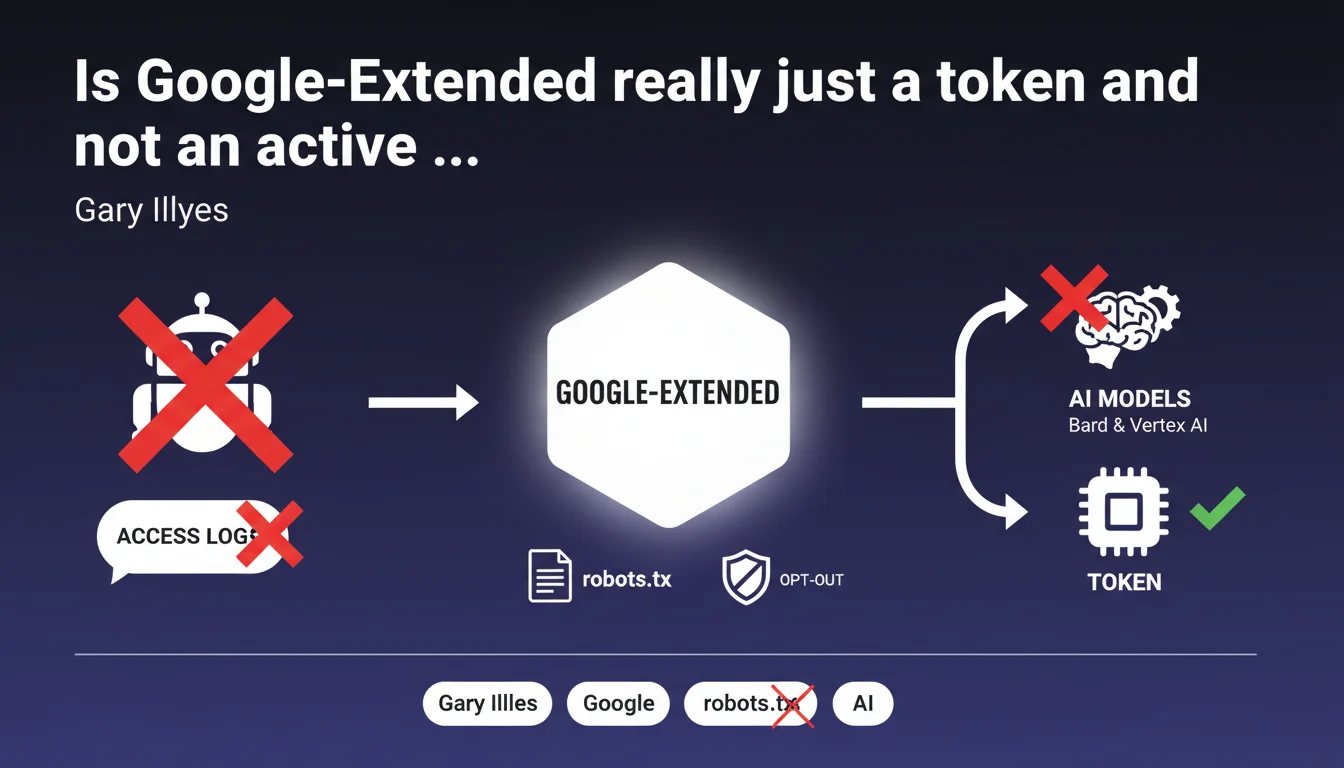
Google-Extended is not a bot that actively crawls your pages: it's simply a token in robots.txt that allows you to exclude your content from the training of AI models (Bard, Vertex AI). Direct consequence: it will never appear in your server logs. This clarification settles the debate about its technical nature and its real impact on your infrastructure.
What you need to understand
What's the difference between a crawler and a product token?
A crawler is an active software agent that sends HTTP requests to your server, explores your URLs, and leaves traces in your access logs. It consumes crawl budget and generates server load.
A product token like Google-Extended performs no direct action. It's a declarative identifier in your robots.txt file that Google reads to determine whether your content can be used to train its AI models. No autonomous requests, no trace in the logs.
How does Google use this token in practice?
When Googlebot (the actual crawler) visits your site, it consults your robots.txt. If it contains a directive blocking Google-Extended, Google will mark the collected content as unusable for AI training.
The crawl itself remains performed by regular Googlebot. Google-Extended acts as a permission flag post-crawl, not as a separate collection agent.
What are the key takeaways?
- Google-Extended does not crawl: it's a consent directive, not a bot
- It consumes no crawl budget or server resources directly
- Blocking Google-Extended does not prevent Googlebot from crawling — it only prevents the use of data for AI
- This distinction is crucial for correctly diagnosing crawl patterns in your logs
- The token applies specifically to Bard and Vertex AI, not to classic search
SEO Expert opinion
Is this declaration consistent with real-world observations?
Yes, and it actually resolves several misconceptions. Some webmasters were scrutinizing their logs looking for a "Google-Extended" user-agent and were concerned when they found nothing. Gary Illyes' clarification confirms what could already be deduced from the architecture: no trace can exist because there is no direct network activity.
This logic aligns with how other control tokens work (NOODP, NOYDIR in the past): they are metadata interpreted by Google systems, not crawlers.
What nuances should be added to this announcement?
The token/crawler distinction says nothing about when and how Google actually collects data for AI. The crawl mechanism remains opaque: is it regular Googlebot that extracts everything? Is there differentiated processing based on the token? [To be verified] on the exact pipeline between crawl and ingestion into training datasets.
Another blind spot: this declaration does not specify whether blocking Google-Extended has an indirect impact on ranking. Some fear that opting out of AI training signals a lack of cooperation with the Google ecosystem. Nothing proves this, but nothing disproves it either.
In what cases could this rule be misunderstood?
A site blocking Google-Extended might believe it thereby reduces server load or protects its crawl budget. Error: Googlebot will continue to crawl normally. The token only affects post-collection usage of the data.
Another pitfall: confusing Google-Extended with a mechanism to protect against scraping or republication. It's not a DRM. A competitor can still scrape your content — the token only concerns Google and its internal AI models.
Practical impact and recommendations
What should you do concretely with Google-Extended?
First, decide whether you want to allow your content to be used for training Google's AI models. This is a strategic and editorial question before it is a technical one.
If you refuse, add to your robots.txt:
User-agent: Google-Extended Disallow: /
If you agree, no action is necessary — opt-in is the default position. You can also partially authorize certain sections of your site.
What errors should you avoid in configuration?
Do not confuse Google-Extended with Googlebot. Blocking User-agent: Googlebot deindexes your site — blocking Google-Extended only excludes from AI training.
Also avoid monitoring your logs for a Google-Extended user-agent. As Gary Illyes clarified, it will never appear. If you see suspicious traffic, it's something else.
How can you verify that the directive is properly applied?
Google provides no specific validation tool for Google-Extended (unlike the robots.txt test tool for Googlebot). However, you can:
- Verify the syntax of your robots.txt with a standard validator
- Test the accessibility of the file via
yoursite.com/robots.txt - Document your choice in a data policy if relevant to your audience
- Monitor Google's official communications for any future reporting tools [To be verified]
❓ Frequently Asked Questions
Bloquer Google-Extended empêche-t-il Googlebot de crawler mon site ?
Puis-je voir Google-Extended dans mes logs serveur ?
Bloquer Google-Extended a-t-il un impact sur mon ranking dans la recherche ?
Google-Extended s'applique-t-il uniquement à Bard et Vertex AI ?
Puis-je autoriser partiellement certaines sections de mon site pour le training IA ?
🎥 From the same video 10
Other SEO insights extracted from this same Google Search Central video · published on 21/12/2023
🎥 Watch the full video on YouTube →
💬 Comments (0)
Be the first to comment.