Official statement
Other statements from this video 10 ▾
- □ Pourquoi Googlebot refuse-t-il de crawler les pages HTML de plus de 15 Mo ?
- □ La balise title reste-t-elle vraiment un pilier du SEO malgré l'évolution des CMS ?
- □ Pourquoi Google remplace-t-il le First Input Delay par l'Interaction to Next Paint dans les Core Web Vitals ?
- □ Faut-il vraiment arrêter d'optimiser pour les Core Web Vitals ?
- □ Google-Extended est-il vraiment un token et non un crawler ?
- □ Google prépare-t-il vraiment un opt-out universel pour le training IA ?
- □ Pourquoi Google vérifie-t-il 4 milliards de robots.txt chaque jour ?
- □ Les principes d'IA de Google s'appliquent-ils vraiment aux résultats de recherche ?
- □ Peut-on vraiment faire confiance aux contenus générés par l'IA pour le SEO ?
- □ Comment Google veut-il encadrer l'usage de l'IA dans la création de contenu ?
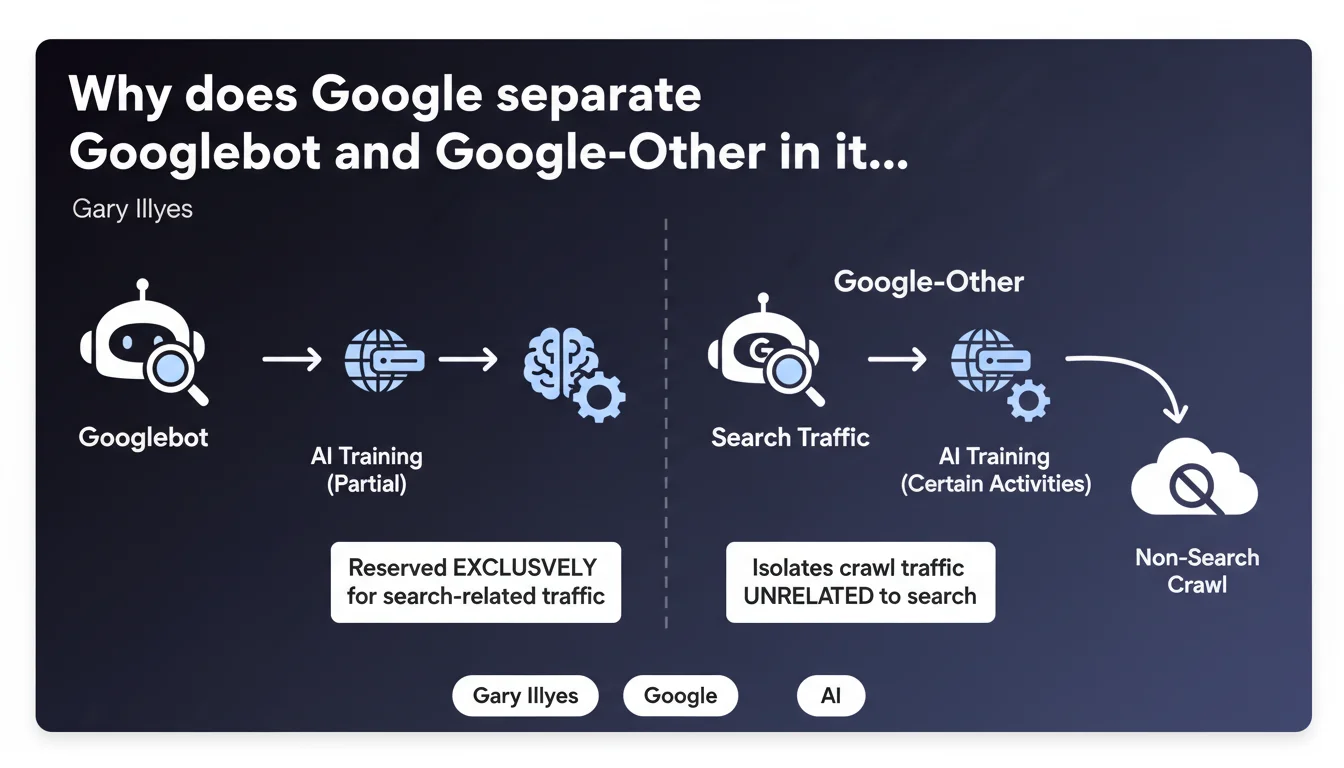
Google has introduced Google-Other, a distinct user-agent separate from Googlebot, to isolate crawl traffic unrelated to search. Googlebot is now exclusively dedicated to crawling for indexation, while Google-Other handles other activities including AI model training. This separation allows webmasters to better control and monitor crawl traffic on their servers.
What you need to understand
What exactly is Google-Other?
Google-Other is a new user-agent created to identify crawl traffic that has no direct connection to indexation for search. Before this separation, Googlebot grouped all types of Google crawl, making it difficult to distinguish between what actually served SEO purposes and what involved other internal uses.
Concretely, Google-Other covers activities like internal Google search and certain AI model training tasks. This technical distinction is not trivial: it allows drawing a clear line between what impacts your organic visibility and what doesn't.
Why does this separation make sense for Google?
The multiplication of crawl uses at Google — particularly with the rise of generative AI — created growing confusion in server logs. Webmasters saw Googlebot traffic without understanding whether it contributed to their indexation or served other objectives.
By isolating Google-Other, Google clarifies its own operations and facilitates monitoring on the webmaster side. It's also a way to prevent intensive crawl activities for AI from being perceived as a waste of crawl budget intended for search.
What impact on traditional crawl budget?
Theoretically, if Google-Other handles traffic that was previously attributed to Googlebot, this should reduce the apparent load on the main user-agent. But be careful: it doesn't change anything about the total volume of HTTP requests your servers receive from Google.
The real difference is that you can now analyze separately the behavior of these two bots. If Google-Other crawls massively pages that aren't strategically important, you'll see it immediately in your logs — and you can act accordingly via robots.txt or Search Console.
- Google-Other is not related to indexation for organic search
- Googlebot becomes exclusively dedicated to crawling for SEO purposes
- This separation improves transparency and webmaster control over their traffic
- The total volume of Google crawl doesn't necessarily decrease
- You can manage these two user-agents independently in robots.txt
SEO Expert opinion
Is this statement consistent with patterns observed in the field?
In principle, yes. Seasoned SEO professionals have noticed for several months a diversification of crawl patterns in their logs, with atypical behaviors not matching classic indexation cycles. The creation of Google-Other officially confirms what some already suspected.
Where it gets tricky is on transparency of criteria: Gary Illyes doesn't specify exactly which activities fall under Google-Other beyond "search and certain AI training activities". [To verify] in the field: which types of pages does Google-Other prioritize? What is the actual frequency of this crawl compared to Googlebot?
What nuances should be added to this announcement?
First point: this separation does not mean Google-Other is negligible. If your site is used to train AI models, it's potentially strategic for your future visibility in AI-enhanced results (SGE, Bard, etc.). Blindly blocking Google-Other could have side effects.
Second nuance: the Googlebot/Google-Other distinction remains unclear in certain edge cases. For example, is crawling for featured snippets or rich results still pure Googlebot, or could certain aspects shift to Google-Other? Google doesn't say. [To verify] in your own logs.
In which cases might this rule not apply as expected?
If you manage a site with low crawl budget, the Googlebot/Google-Other separation probably won't change your daily routine — you'll simply see two user-agents instead of one, with no real impact on total crawl frequency.
Conversely, on large sites with millions of pages, this distinction can reveal hidden patterns: for example, Google-Other could be massively crawling archives or duplicate content that Googlebot already ignores. It becomes an actionable signal to optimize your architecture.
Practical impact and recommendations
What should you concretely do with these two user-agents?
First step: segment your server logs to distinctly identify Googlebot and Google-Other traffic. Compare volumes, crawled pages, frequencies. This is the only way to know if Google-Other really impacts your infrastructure.
If Google-Other consumes significant resources on non-strategic sections, you can block it selectively via robots.txt. But don't block it by default: analyze its behavior first for at least one month.
What mistakes should you avoid in managing Google-Other?
Classic mistake: treat Google-Other as a parasitic bot and block it immediately. You risk cutting yourself off from future opportunities in Google's AI ecosystem, particularly for enriched answers or citations in SGE.
Another pitfall: completely ignore Google-Other on the grounds that it doesn't impact indexation. If this bot crawls your site intensively, it consumes bandwidth and server resources — that's a real cost you need to monitor.
How do you verify your site is handling these two bots correctly?
Install user-agent monitoring in your logs (Apache, Nginx, or via a tool like Screaming Frog Log Analyzer). Identify crawl patterns for Googlebot and Google-Other separately.
Also check in Search Console if Google reports crawl errors specific to either user-agent. Certain server parameters (rate limiting, caching) may treat these two bots differently.
- Segment your logs to isolate Googlebot and Google-Other
- Analyze pages crawled by each bot over a minimum 30-day period
- Don't block Google-Other by default — assess its impact first
- Monitor bandwidth consumption and server resource usage
- Adjust your robots.txt only if Google-Other crawls non-strategic sections excessively
- Document observed patterns to adjust your strategy over time
❓ Frequently Asked Questions
Google-Other compte-t-il dans le crawl budget de mon site ?
Puis-je bloquer Google-Other sans risque pour mon référencement ?
Comment différencier Googlebot et Google-Other dans mes logs serveur ?
Google-Other peut-il crawler mon site plus fréquemment que Googlebot ?
Cette séparation change-t-elle quelque chose pour les petits sites ?
🎥 From the same video 10
Other SEO insights extracted from this same Google Search Central video · published on 21/12/2023
🎥 Watch the full video on YouTube →
💬 Comments (0)
Be the first to comment.