Official statement
Other statements from this video 10 ▾
- □ Pourquoi Googlebot refuse-t-il de crawler les pages HTML de plus de 15 Mo ?
- □ La balise title reste-t-elle vraiment un pilier du SEO malgré l'évolution des CMS ?
- □ Pourquoi Google remplace-t-il le First Input Delay par l'Interaction to Next Paint dans les Core Web Vitals ?
- □ Faut-il vraiment arrêter d'optimiser pour les Core Web Vitals ?
- □ Pourquoi Google sépare-t-il Googlebot et Google-Other dans ses crawls ?
- □ Google-Extended est-il vraiment un token et non un crawler ?
- □ Google prépare-t-il vraiment un opt-out universel pour le training IA ?
- □ Les principes d'IA de Google s'appliquent-ils vraiment aux résultats de recherche ?
- □ Peut-on vraiment faire confiance aux contenus générés par l'IA pour le SEO ?
- □ Comment Google veut-il encadrer l'usage de l'IA dans la création de contenu ?
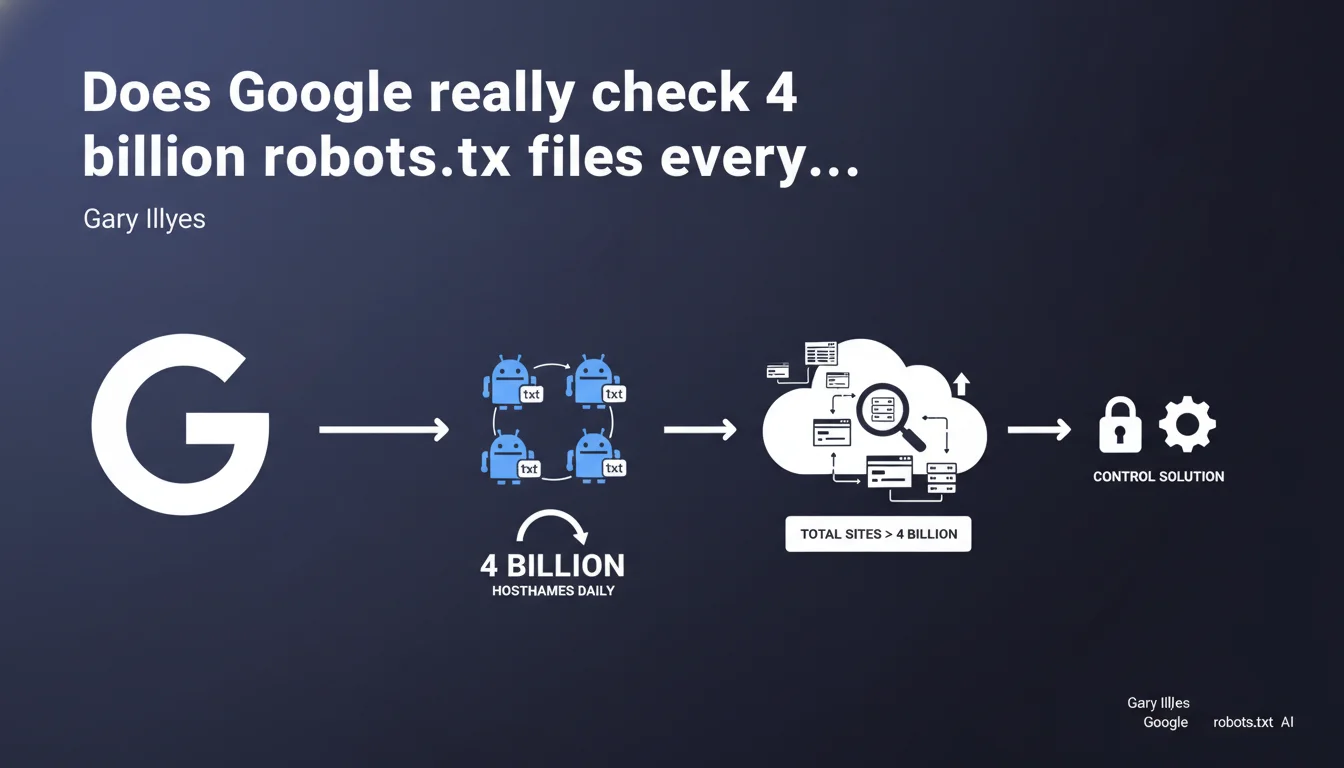
Google crawls the robots.txt files of approximately 4 billion hostnames daily — and the actual number of sites (including subdirectories) exceeds this figure. This massive scale creates significant technical constraints: any control or monitoring solution must account for this colossal volume.
What you need to understand
What is a hostname in the context of Google crawling?
A hostname corresponds to a unique host name: domain.com, subdomain.domain.com, another.domain.com are three distinct hostnames. Google checks the robots.txt of each one before any crawling begins.
The figure of 4 billion therefore does not represent 4 billion sites in the classical sense — but 4 billion distinct entry points where Google must verify crawling directives. The actual number of 'sites' (including subdirectories) far exceeds this count.
Why does Google emphasize this massive scale?
The statement comes to justify the technical constraints imposed by Google: robots.txt update delays, file size limit (500 KB max), inability to offer a real-time validation service for each webmaster.
Concretely? If your robots.txt takes 24 hours to be recognized after modification, it's because Google must manage this volume. Any control or alert system must integrate this reality: you're not managing infrastructure at your own scale, but Google's scale.
What does 'any control solution must account for this scale' mean?
Gary Illyes is warning: don't expect Google to provide individualized monitoring tools or instant notifications. Webmasters hoping for immediate feedback on every robots.txt modification need to reset their expectations.
Third-party solutions (SEO crawlers, log monitoring) remain essential to anticipate Googlebot behavior — Google Search Console cannot offer real-time tracking at this scale.
- 4 billion hostnames verified daily — each subdomain counts
- The actual number of sites (with subdirectories) far exceeds this figure
- Robots.txt update delays are explained by this volume
- Google cannot provide individualized real-time monitoring
- Third-party tools remain essential to anticipate crawl behavior
SEO Expert opinion
Is this statement consistent with real-world observations?
Yes, completely. SEOs who modify their robots.txt systematically observe variable delays before Googlebot takes it into account — sometimes a few hours, sometimes several days. This variance is explained by managing a colossal queue.
The crucial point: Google does not crawl 4 billion sites per day. It verifies 4 billion robots.txt files. The difference is major — some hostnames only receive a robots.txt verification without actual content exploration.
What nuances should be added to this claim?
Gary Illyes remains vague about the verification frequency per hostname. [To be verified]: a popular hostname likely sees its robots.txt queried multiple times daily, while a dormant site might wait weeks.
Another point: the figure of 4 billion likely includes inactive hostnames, expired domains still in cache, abandoned subdomains. Google doesn't filter beforehand — it verifies everything, even what's no longer useful.
In what cases does this rule not apply?
Priority sites (news, large-scale platforms) benefit from accelerated verification cycles. Google adjusts frequency based on update history and site criticality.
If you modify your robots.txt and request reindexing via Search Console, Google may force an early verification — but nothing is guaranteed. The massive scale imposes compromises: you're just one hostname among 4 billion.
Practical impact and recommendations
What should you do concretely after this revelation?
First, anticipate delays. Any critical robots.txt modification must be planned with a safety margin — never block a strategic directory the day before a launch without testing beforehand.
Next, invest in server log monitoring tools. You need to know when Googlebot checks your robots.txt, how frequently, and whether new directives are being respected. GSC isn't enough.
What mistakes should you absolutely avoid?
Don't rely on Google to alert you to a robots.txt error. An accidental block could go unnoticed for weeks if you don't actively monitor your logs or a third-party crawler.
Another trap: modifying a subdomain's robots.txt thinking the effect will be immediate. Each hostname has its own verification cycle — a lightly crawled subdomain might take days to reflect the change.
How do you verify your site is properly accounted for?
- Test each modification using the robots.txt testing tool in Search Console before publishing
- Analyze your server logs to identify Googlebot's robots.txt verification frequency
- Use an external SEO crawler (Screaming Frog, Oncrawl, Botify) to simulate Google's behavior
- Document each change with timestamp and verify actual implementation within 48-72 hours
- If a critical block persists, submit a manual indexing request via GSC
❓ Frequently Asked Questions
Google crawle-t-il 4 milliards de sites par jour ?
Pourquoi mon robots.txt modifié met-il du temps à être pris en compte ?
Chaque sous-domaine a-t-il son propre robots.txt vérifié séparément ?
Comment accélérer la prise en compte d'une modification du robots.txt ?
Le chiffre de 4 milliards inclut-il les sites inactifs ou abandonnés ?
🎥 From the same video 10
Other SEO insights extracted from this same Google Search Central video · published on 21/12/2023
🎥 Watch the full video on YouTube →
💬 Comments (0)
Be the first to comment.