Official statement
Other statements from this video 13 ▾
- □ Robots.txt bloque-t-il vraiment l'indexation de vos pages ?
- □ La balise meta 'none' est-elle vraiment l'équivalent de noindex + nofollow ?
- □ Robots.txt est-il vraiment inefficace pour bloquer l'indexation ?
- □ Peut-on bloquer l'indexation de répertoires entiers via des modules serveur plutôt que robots.txt ?
- □ Faut-il vraiment indexer les pages de connexion de votre site ?
- □ La balise noarchive empêche-t-elle réellement Google d'archiver vos pages ?
- □ Faut-il bloquer les snippets avec nosnippet pour protéger son contenu sensible ?
- □ Faut-il vraiment utiliser max-snippet et max-image-preview pour contrôler l'affichage dans les SERP ?
- □ Faut-il privilégier l'attribut nofollow individuel ou la balise meta robots nofollow pour contrôler le PageRank ?
- □ Pourquoi Google refuse-t-il de créer de nouvelles balises meta robots ?
- □ Comment bloquer l'indexation de PDFs et fichiers non-HTML sans accès aux headers HTTP ?
- □ Pourquoi robots.txt bloque-t-il vraiment les images et vidéos mais pas les pages web ?
- □ Comment Google transforme-t-il vraiment vos PDFs en contenu indexable ?
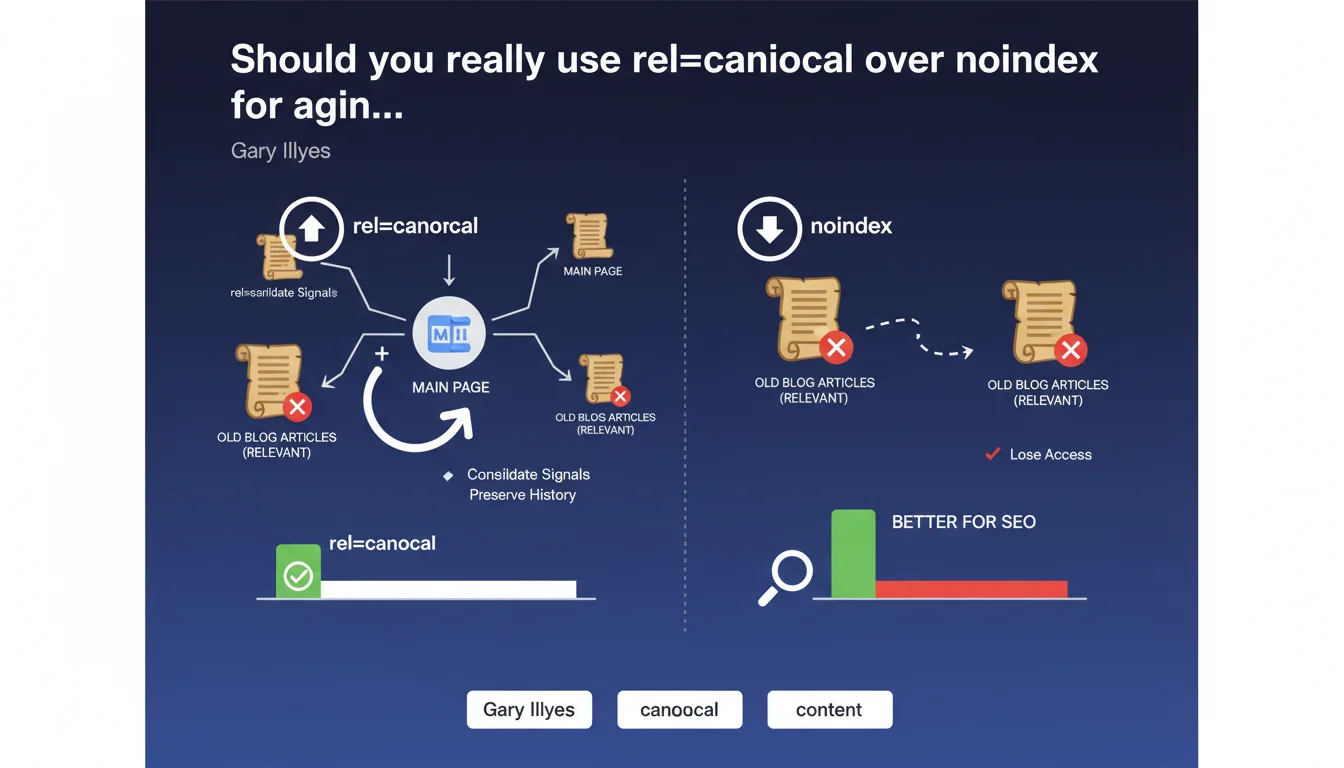
Google recommends using rel=canonical rather than noindex to manage old blog articles that remain relevant. The goal: consolidate SEO signals toward your main content while maintaining access to archives. An approach that challenges conventional wisdom about handling outdated content.
What you need to understand
Why does Google distinguish between old content and obsolete content?
The distinction matters. Old content remains historically relevant — it can still answer a query, serve as a reference, or generate sporadic organic traffic. Obsolete content, by contrast, adds no value and genuinely deserves noindex or removal.
Google is essentially saying: don't throw the baby out with the bathwater. Dated blog articles that still get visited retain real value: accumulated backlinks, historical context, cumulative topical authority. Brutally deindexing them cuts off these signal flows.
How does rel=canonical consolidate SEO signals?
The canonical tag tells Google which version to treat as primary. By pointing an old article to an updated page or pillar page, you transfer link equity and relevance signals to that canonical content.
In practice: the old URL remains accessible (no 404, no user experience loss), but its SEO weight gets redirected. Google understands that the main page deserves to rank higher in search results.
What are the risks of systematically using noindex on old content?
Using noindex across hundreds of old articles weakens your indexation footprint. You lose pages that, even with minimal traffic, contribute to your overall semantic coverage and thematic history.
Backlinks pointing to those pages lose their value — Google doesn't pass PageRank from a noindexed page. You also break internal navigation paths, fragmenting your internal linking structure and complicating crawlability.
- rel=canonical: maintains access, consolidates signals toward the main page, preserves backlink equity
- noindex: cuts off signals, loses link equity, reduces your indexable surface with no clear benefit
- Old content ≠ dead content — as long as it remains relevant, it deserves a place in your index
- Deindexing should be reserved for truly obsolete or duplicate content without real value
SEO Expert opinion
Is this recommendation consistent with observed practices?
Yes and no. In the real world, we do see that Google effectively transfers some authority via canonical — it's documented, tested, and verified. But effectiveness varies depending on context: news sites vs. technical blogs, volume of affected pages, internal linking quality.
The catch: Google doesn't specify at what obsolescence threshold content shifts from "old but relevant" to "truly dead." [Needs verification]: no metrics provided, no concrete examples here. We're navigating in the dark.
In what cases doesn't this rule apply?
If your old article is technically incorrect (e.g., a tutorial on a deprecated feature), leaving it indexed even via canonical creates a credibility problem. Better to 301 redirect or delete outright.
Another edge case: sites with thousands of weakly differentiated pages (aggregators, directories). Consolidating via canonical can create massive clusters that Google struggles to interpret. There, a pruning strategy (pure deletion) or 301 redirects may be cleaner.
What's the real intent behind this recommendation?
Google wants to prevent sites from gutting their indexation by reflex. Too many SEO professionals noindex everything over 12 months old without analysis. Result: sites with only 30% of pages indexed, lost semantic coverage, and crawl budget wasted re-evaluating noindex directives.
The recommendation pushes consolidation thinking rather than deletion thinking. It's a more architectural, less brutal approach — but it requires more nuance and execution time.
Practical impact and recommendations
What should you concretely do with your old content?
Start by auditing. Export your articles older than 2 years with their organic traffic from the last 12 months, their backlinks, and average ranking position. Segment into three categories: still-performing content, low-traffic content with backlinks, completely dead content.
For the first category: do nothing, or update if relevant. For the second: implement rel=canonical pointing to an updated pillar page covering the same topic. For the third: 301 or complete removal if truly obsolete.
What errors should you avoid when implementing canonical?
Don't canonicalize to a generic page or off-topic page — Google will ignore the signal and you'll lose clarity. The canonical page must genuinely evolve from or synthesize the old content, not just be the homepage or a vague category.
Also avoid canonical chains (page A → B → C). Google can follow them, but it's inefficient and error-prone. Always point to the final destination.
- Audit your old content (traffic, backlinks, current relevance)
- Segment: performing / to consolidate / obsolete
- Implement canonical only toward thematically coherent pages
- Check for absent canonical chains or loops in your code
- Monitor via Search Console that Google respects your canonicals (Coverage report)
- Don't overuse noindex — reserve it for true duplicates or worthless content
❓ Frequently Asked Questions
Peut-on utiliser canonical ET noindex sur la même page ?
Le canonical transfère-t-il 100 % du PageRank comme une 301 ?
Combien de temps faut-il à Google pour prendre en compte un canonical ajouté ?
Faut-il canonicaliser tous les vieux articles vers la homepage ?
Que faire si Google n'applique pas mon canonical ?
🎥 From the same video 13
Other SEO insights extracted from this same Google Search Central video · published on 30/06/2022
🎥 Watch the full video on YouTube →
💬 Comments (0)
Be the first to comment.