Declaration officielle
Autres déclarations de cette vidéo 13 ▾
- □ Robots.txt bloque-t-il vraiment l'indexation de vos pages ?
- □ La balise meta 'none' est-elle vraiment l'équivalent de noindex + nofollow ?
- □ Robots.txt est-il vraiment inefficace pour bloquer l'indexation ?
- □ Peut-on bloquer l'indexation de répertoires entiers via des modules serveur plutôt que robots.txt ?
- □ Faut-il vraiment indexer les pages de connexion de votre site ?
- □ La balise noarchive empêche-t-elle réellement Google d'archiver vos pages ?
- □ Faut-il bloquer les snippets avec nosnippet pour protéger son contenu sensible ?
- □ Faut-il vraiment utiliser max-snippet et max-image-preview pour contrôler l'affichage dans les SERP ?
- □ Faut-il privilégier l'attribut nofollow individuel ou la balise meta robots nofollow pour contrôler le PageRank ?
- □ Pourquoi Google refuse-t-il de créer de nouvelles balises meta robots ?
- □ Comment bloquer l'indexation de PDFs et fichiers non-HTML sans accès aux headers HTTP ?
- □ Pourquoi robots.txt bloque-t-il vraiment les images et vidéos mais pas les pages web ?
- □ Comment Google transforme-t-il vraiment vos PDFs en contenu indexable ?
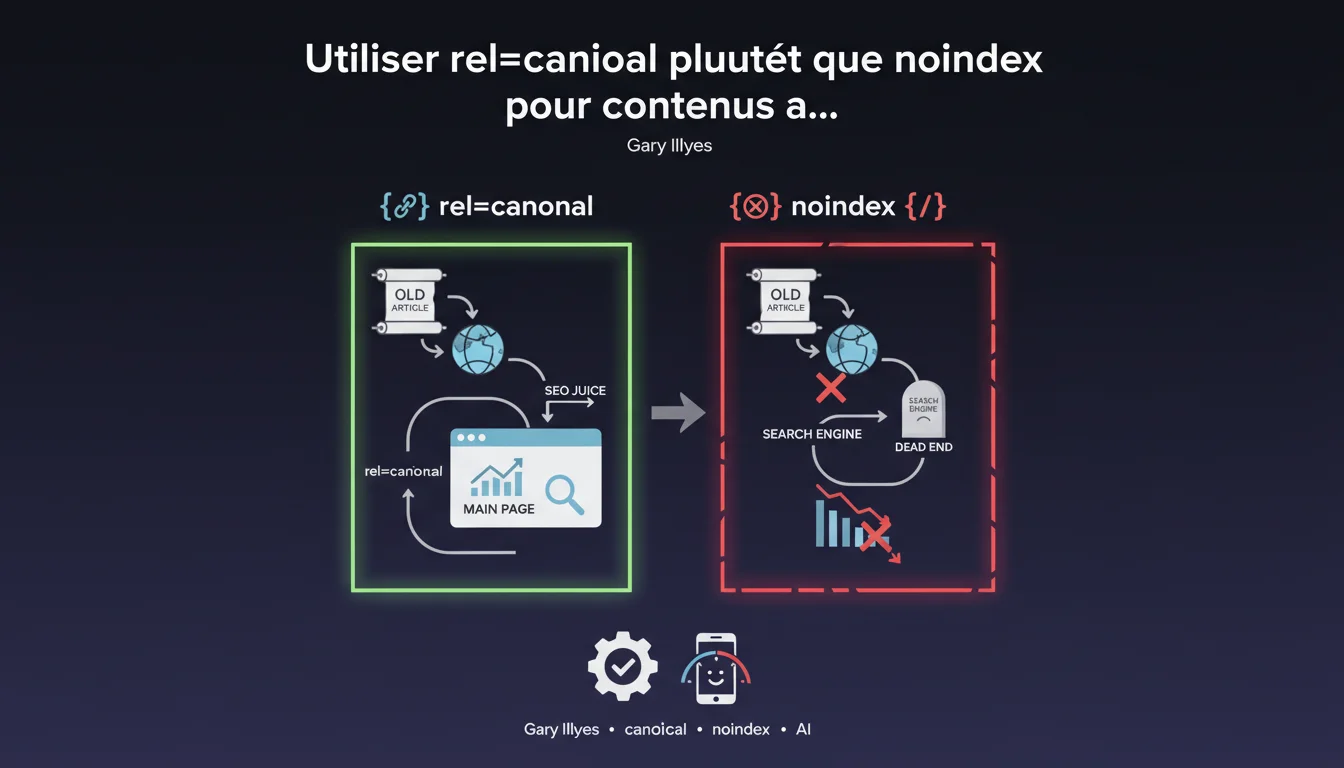
Google recommande d'utiliser rel=canonical plutôt que noindex pour gérer les vieux articles de blog encore pertinents. L'objectif : consolider les signaux SEO vers le contenu principal tout en maintenant l'accès aux archives. Une approche qui interroge la gestion classique des contenus obsolètes.
Ce qu'il faut comprendre
Pourquoi Google distingue-t-il les contenus anciens des contenus obsolètes ?
La nuance est importante. Un contenu ancien reste pertinent historiquement — il peut encore répondre à une requête, servir de référence ou générer du trafic organique sporadique. Un contenu obsolète, lui, n'apporte plus rien et mérite effectivement le noindex ou la suppression.
Google suggère ici de ne pas jeter le bébé avec l'eau du bain. Les articles de blog datés mais toujours consultés gardent une valeur : backlinks accumulés, contexte historique, autorité thématique cumulée. Les désindexer brutalement coupe ces flux de signaux.
Comment rel=canonical consolide-t-il les signaux SEO ?
La balise canonical indique à Google quelle version considérer comme principale. En pointant un vieil article vers une page actualisée ou une page pilier, vous transférez l'équité de lien et les signaux de pertinence vers ce contenu canonique.
Concrètement : l'ancienne URL reste accessible (pas de 404, pas de perte d'expérience utilisateur), mais son poids SEO est redirigé. Google comprend que la page principale mérite d'être favorisée dans les résultats de recherche.
Quels sont les risques du noindex systématique sur contenus anciens ?
Utiliser noindex sur des centaines d'articles anciens dilue votre empreinte d'indexation. Vous perdez des pages qui, même avec peu de trafic, contribuent à votre couverture sémantique globale et à votre historique thématique.
Les backlinks pointant vers ces pages perdent leur valeur — Google ne transmet pas le PageRank depuis une page noindexée. Vous cassez aussi des chemins de navigation internes, ce qui fragmente votre maillage interne et complique le crawl.
- rel=canonical : maintient l'accès, consolide les signaux vers la page principale, préserve les backlinks
- noindex : coupe les signaux, perd l'équité de lien, réduit la surface d'indexation sans bénéfice clair
- Un contenu ancien ≠ un contenu mort — tant qu'il reste pertinent, il a sa place dans l'index
- La désindexation doit être réservée aux contenus vraiment obsolètes ou dupliqués sans valeur
Avis d'un expert SEO
Cette recommandation est-elle cohérente avec les pratiques observées ?
Oui et non. Sur le terrain, on constate que Google transfère effectivement une partie de l'autorité via canonical — c'est documenté, testé, vérifié. Mais l'efficacité varie selon le contexte : site d'actualité vs. blog technique, volume de pages concernées, qualité du maillage interne.
Le hic : Google ne dit pas à partir de quel seuil d'obsolescence un contenu bascule de « ancien mais pertinent » à « vraiment mort ». [A vérifier] : aucune métrique chiffrée, aucun exemple concret fourni ici. On navigue à vue.
Dans quels cas cette règle ne s'applique-t-elle pas ?
Si votre article ancien est techniquement faux (ex : tuto sur une fonctionnalité dépréciée), le laisser indexé même via canonical pose un problème de crédibilité. Mieux vaut rediriger en 301 ou carrément supprimer.
Autre cas limite : les sites avec des milliers de pages faiblement différenciées (agrégateurs, annuaires). Consolider via canonical peut créer des clusters massifs que Google peine à interpréter. Là, une stratégie de pruning (suppression pure) ou de redirection 301 peut être plus nette.
Quelle est la vraie intention derrière cette recommandation ?
Google veut éviter que les sites massacrent leur indexation par réflexe. Trop de SEO noindexent par défaut tout ce qui dépasse 12 mois, sans analyse. Résultat : des sites avec 30 % de pages indexées, une perte de couverture sémantique, et un crawl budget gaspillé à réévaluer des noindex.
La recommandation de Gary Illyes pousse à raisonner en termes de consolidation plutôt qu'en termes de suppression. C'est une approche plus architecturale, moins brutale — mais qui demande plus de finesse et de temps d'exécution.
Impact pratique et recommandations
Que faut-il faire concrètement avec vos contenus anciens ?
D'abord, auditer. Exportez vos articles datés de plus de 2 ans avec leur trafic organique des 12 derniers mois, leurs backlinks, et leur position moyenne. Segmentez en trois catégories : contenus encore performants, contenus à faible trafic mais avec backlinks, contenus totalement morts.
Pour la première catégorie : rien à faire, ou actualiser si pertinent. Pour la deuxième : implémentez rel=canonical vers une page pilier actualisée traitant du même sujet. Pour la troisième : 301 ou suppression pure si vraiment obsolète.
Quelles erreurs éviter lors de la mise en place de canonical ?
Ne canonicalisez pas vers une page trop générique ou hors sujet — Google ignorera le signal et vous perdrez en clarté. La page canonique doit être une vraie évolution ou synthèse du contenu ancien, pas juste la homepage ou une catégorie vague.
Évitez aussi les chaînes de canonical (page A → B → C). Google peut les suivre, mais c'est inefficace et source d'erreurs. Pointez toujours vers la destination finale.
- Auditez vos contenus anciens (trafic, backlinks, pertinence actuelle)
- Segmentez : performants / à consolider / obsolètes
- Implémentez canonical uniquement vers des pages thématiquement cohérentes
- Vérifiez l'absence de chaînes ou de boucles canonical dans votre code
- Contrôlez via Search Console que Google respecte vos canonical (rapport Couverture)
- N'abusez pas du noindex — réservez-le aux vrais doublons ou contenus sans valeur
❓ Questions frequentes
Peut-on utiliser canonical ET noindex sur la même page ?
Le canonical transfère-t-il 100 % du PageRank comme une 301 ?
Combien de temps faut-il à Google pour prendre en compte un canonical ajouté ?
Faut-il canonicaliser tous les vieux articles vers la homepage ?
Que faire si Google n'applique pas mon canonical ?
🎥 De la même vidéo 13
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 30/06/2022
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.