Declaration officielle
Autres déclarations de cette vidéo 13 ▾
- □ Robots.txt bloque-t-il vraiment l'indexation de vos pages ?
- □ La balise meta 'none' est-elle vraiment l'équivalent de noindex + nofollow ?
- □ Robots.txt est-il vraiment inefficace pour bloquer l'indexation ?
- □ Faut-il vraiment indexer les pages de connexion de votre site ?
- □ Faut-il vraiment préférer rel=canonical à noindex pour les contenus anciens ?
- □ La balise noarchive empêche-t-elle réellement Google d'archiver vos pages ?
- □ Faut-il bloquer les snippets avec nosnippet pour protéger son contenu sensible ?
- □ Faut-il vraiment utiliser max-snippet et max-image-preview pour contrôler l'affichage dans les SERP ?
- □ Faut-il privilégier l'attribut nofollow individuel ou la balise meta robots nofollow pour contrôler le PageRank ?
- □ Pourquoi Google refuse-t-il de créer de nouvelles balises meta robots ?
- □ Comment bloquer l'indexation de PDFs et fichiers non-HTML sans accès aux headers HTTP ?
- □ Pourquoi robots.txt bloque-t-il vraiment les images et vidéos mais pas les pages web ?
- □ Comment Google transforme-t-il vraiment vos PDFs en contenu indexable ?
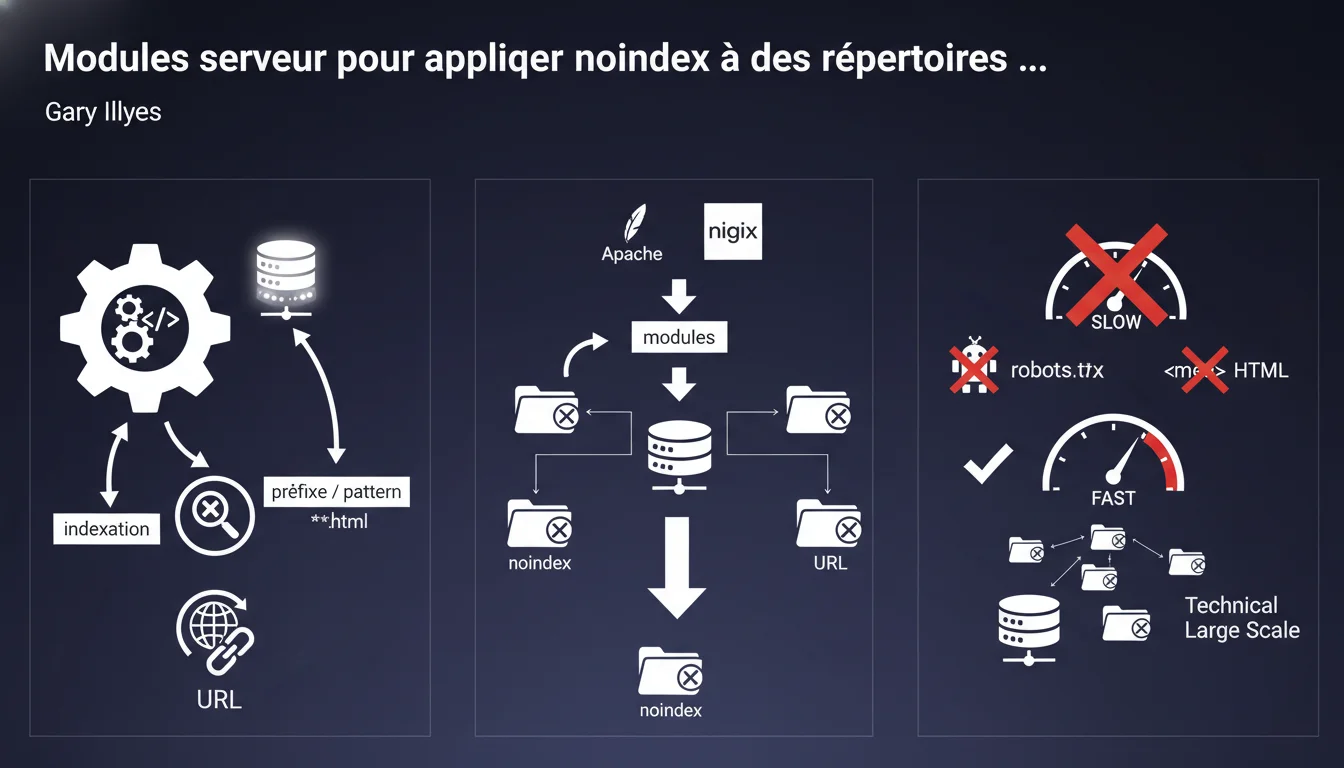
Google confirme qu'on peut utiliser des modules Apache (mod_headers) ou des configurations Nginx pour appliquer automatiquement la balise noindex à tous les URLs sous un préfixe ou pattern donné. Cette méthode est plus technique que robots.txt ou l'ajout de balises HTML manuelles, mais elle permet de bloquer l'indexation d'une grande partie d'un site de manière centralisée et scalable.
Ce qu'il faut comprendre
Pourquoi cette méthode existe-t-elle alors qu'on a déjà robots.txt ?
La directive Disallow dans robots.txt bloque le crawl, pas l'indexation. Google peut toujours indexer une URL bloquée dans robots.txt si elle reçoit des liens externes, en affichant une page sans description ni titre dans les résultats.
La balise noindex, elle, empêche réellement l'indexation. Mais l'ajouter manuellement sur des milliers de pages relève du cauchemar opérationnel. Les modules serveur résolvent ce problème en appliquant noindex automatiquement selon des règles de pattern (préfixe, regex, etc.).
Comment ça fonctionne techniquement côté serveur ?
Sur Apache, on utilise mod_headers avec des directives dans le fichier .htaccess ou la config principale. Par exemple : Header set X-Robots-Tag "noindex" dans une section LocationMatch. Sur Nginx, on ajoute add_header X-Robots-Tag "noindex" dans un bloc location correspondant au pattern.
Ces headers sont envoyés dans la réponse HTTP. Googlebot les lit comme il lirait une balise meta robots dans le HTML. Avantage majeur : aucune modification du code applicatif ou des templates nécessaire.
Quels sont les cas d'usage réels de cette technique ?
Typiquement, on l'utilise pour bloquer l'indexation de répertoires système (/admin, /test, /staging), des URLs avec paramètres (filtres, tri, pagination infinie), ou des environnements de développement accessibles publiquement par erreur.
C'est aussi pertinent pour les plateformes avec génération d'URLs automatiques où ajouter des balises dans le code serait trop lourd. Mais attention : si le répertoire est déjà massivement indexé, la désindexation prendra du temps — Google doit recrawler chaque URL pour voir le header.
- robots.txt bloque le crawl, pas l'indexation réelle
- X-Robots-Tag noindex via modules serveur = indexation bloquée de manière scalable
- Méthode idéale pour patterns d'URLs larges (répertoires entiers, paramètres)
- Requiert accès à la configuration serveur (pas possible sur tous les hébergements mutualisés)
- La désindexation n'est pas instantanée — Google doit recrawler les URLs
Avis d'un expert SEO
Cette approche est-elle vraiment préférable aux alternatives classiques ?
Ça dépend. Pour un site de 50 pages, ajouter des balises meta robots manuellement reste faisable. Mais sur un site avec des milliers d'URLs générées dynamiquement — pensez e-commerce avec filtres, portails d'annonces, forums — c'est un gain de temps et de maintenabilité spectaculaire.
Le piège : beaucoup confondent encore robots.txt et noindex. Bloquer /admin/ dans robots.txt n'empêche pas Google d'indexer ces URLs si elles ont des backlinks. Le X-Robots-Tag via modules serveur, lui, fait vraiment le job. [A vérifier] toutefois que votre hébergeur autorise les modifications de configuration serveur — certains mutualisés verrouillent tout.
Y a-t-il des risques opérationnels à connaître ?
Oui, et ils ne sont pas négligeables. Une regex mal fichue dans une règle LocationMatch ou location peut bloquer l'indexation de sections entières de votre site par accident. J'ai vu un cas où un pattern trop large a désindexé toutes les fiches produits d'un site e-commerce pendant 3 semaines.
Autre souci : la priorité des headers. Si votre CMS ou votre thème envoie déjà un X-Robots-Tag (index, follow) et que votre config serveur en envoie un autre (noindex), le comportement peut devenir imprévisible selon l'ordre d'exécution. Testez toujours avec curl -I avant de pousser en prod.
Dans quels cas cette méthode ne suffit-elle pas ?
Si vos URLs à bloquer ne suivent pas de pattern cohérent, les modules serveur deviennent vite ingérables. Par exemple, des URLs /page-123, /article-456, /content-789 sans préfixe commun nécessiteraient une liste exhaustive — autant utiliser des balises dans le CMS directement.
De plus, si le répertoire bloqué contient des ressources que Google doit indexer ponctuellement (PDFs, images), vous devrez créer des exceptions dans vos règles. Ça devient vite un enfer de maintenance. Et comme toujours avec le serveur : pas de rollback facile si vous cassez quelque chose.
Impact pratique et recommandations
Comment implémenter cette solution sur Apache ou Nginx ?
Sur Apache, ajoutez dans votre .htaccess ou dans la config du VirtualHost :
<LocationMatch "^/test">
Header set X-Robots-Tag "noindex, nofollow"
</LocationMatch>
Sur Nginx, dans le bloc server :
location ^~ /test {
add_header X-Robots-Tag "noindex, nofollow";
}
Testez ensuite avec curl -I https://votresite.com/test/page.html pour vérifier que le header X-Robots-Tag apparaît bien dans la réponse. Si ce n'est pas le cas, vérifiez que le module mod_headers est activé (Apache) ou que la directive add_header est dans le bon contexte (Nginx).
Quelles erreurs éviter absolument lors de la mise en place ?
Première erreur classique : appliquer noindex sur des URLs déjà bloquées par robots.txt. Google ne pourra jamais crawler ces pages pour lire le header, donc elles resteront indexées avec leur ancienne version. Déverrouillez d'abord dans robots.txt, attendez le recrawl, puis désindexez.
Deuxième piège : oublier de tester les sous-répertoires imbriqués. Un pattern comme ^/admin peut ne pas matcher /admin/users/edit selon votre configuration. Préférez ^/admin/ ou utilisez des regex exhaustives.
Troisième boulette : ne pas monitorer la Search Console après déploiement. Surveillez l'évolution du nombre de pages indexées et les erreurs de couverture. Une chute brutale peut signaler une règle trop large qui bouffe des sections importantes.
Comment vérifier que la configuration fonctionne correctement ?
- Testez avec
curl -Iplusieurs URLs du répertoire ciblé pour confirmer la présence du header X-Robots-Tag - Utilisez l'outil Inspection d'URL dans Search Console pour voir comment Google crawle une page concernée
- Vérifiez dans les logs serveur que Googlebot accède bien aux URLs (sinon, problème robots.txt résiduel)
- Monitorez le rapport de couverture dans Search Console : les pages doivent passer en "Exclue par la balise 'noindex'"
- Attendez 2-4 semaines pour voir la désindexation complète — Google doit recrawler chaque URL
- Si vous utilisez des CDN ou caches (Cloudflare, Varnish), purgez-les pour que les nouveaux headers soient servis immédiatement
Les modules serveur pour appliquer noindex offrent une solution élégante et scalable pour bloquer l'indexation de larges sections d'un site. Mais cette approche requiert une compréhension fine de la configuration serveur et comporte des risques de désindexation accidentelle non négligeables.
Si votre infrastructure est complexe ou que vous n'êtes pas à l'aise avec les regex et les directives Apache/Nginx, il peut être judicieux de faire appel à une agence SEO spécialisée qui maîtrise ces aspects techniques et pourra auditer votre configuration avant déploiement, limitant ainsi les risques opérationnels.
❓ Questions frequentes
Peut-on combiner robots.txt et X-Robots-Tag noindex sur les mêmes URLs ?
Le X-Robots-Tag fonctionne-t-il aussi sur les fichiers PDF, images, ou autres ressources non-HTML ?
Combien de temps faut-il pour que Google désindexe des pages après l'ajout du header noindex ?
Que se passe-t-il si on envoie plusieurs headers X-Robots-Tag contradictoires (index puis noindex) ?
Cette méthode impacte-t-elle le crawl budget ou seulement l'indexation ?
🎥 De la même vidéo 13
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 30/06/2022
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.