Declaration officielle
Autres déclarations de cette vidéo 13 ▾
- □ Robots.txt bloque-t-il vraiment l'indexation de vos pages ?
- □ La balise meta 'none' est-elle vraiment l'équivalent de noindex + nofollow ?
- □ Robots.txt est-il vraiment inefficace pour bloquer l'indexation ?
- □ Peut-on bloquer l'indexation de répertoires entiers via des modules serveur plutôt que robots.txt ?
- □ Faut-il vraiment indexer les pages de connexion de votre site ?
- □ Faut-il vraiment préférer rel=canonical à noindex pour les contenus anciens ?
- □ La balise noarchive empêche-t-elle réellement Google d'archiver vos pages ?
- □ Faut-il bloquer les snippets avec nosnippet pour protéger son contenu sensible ?
- □ Faut-il vraiment utiliser max-snippet et max-image-preview pour contrôler l'affichage dans les SERP ?
- □ Faut-il privilégier l'attribut nofollow individuel ou la balise meta robots nofollow pour contrôler le PageRank ?
- □ Comment bloquer l'indexation de PDFs et fichiers non-HTML sans accès aux headers HTTP ?
- □ Pourquoi robots.txt bloque-t-il vraiment les images et vidéos mais pas les pages web ?
- □ Comment Google transforme-t-il vraiment vos PDFs en contenu indexable ?
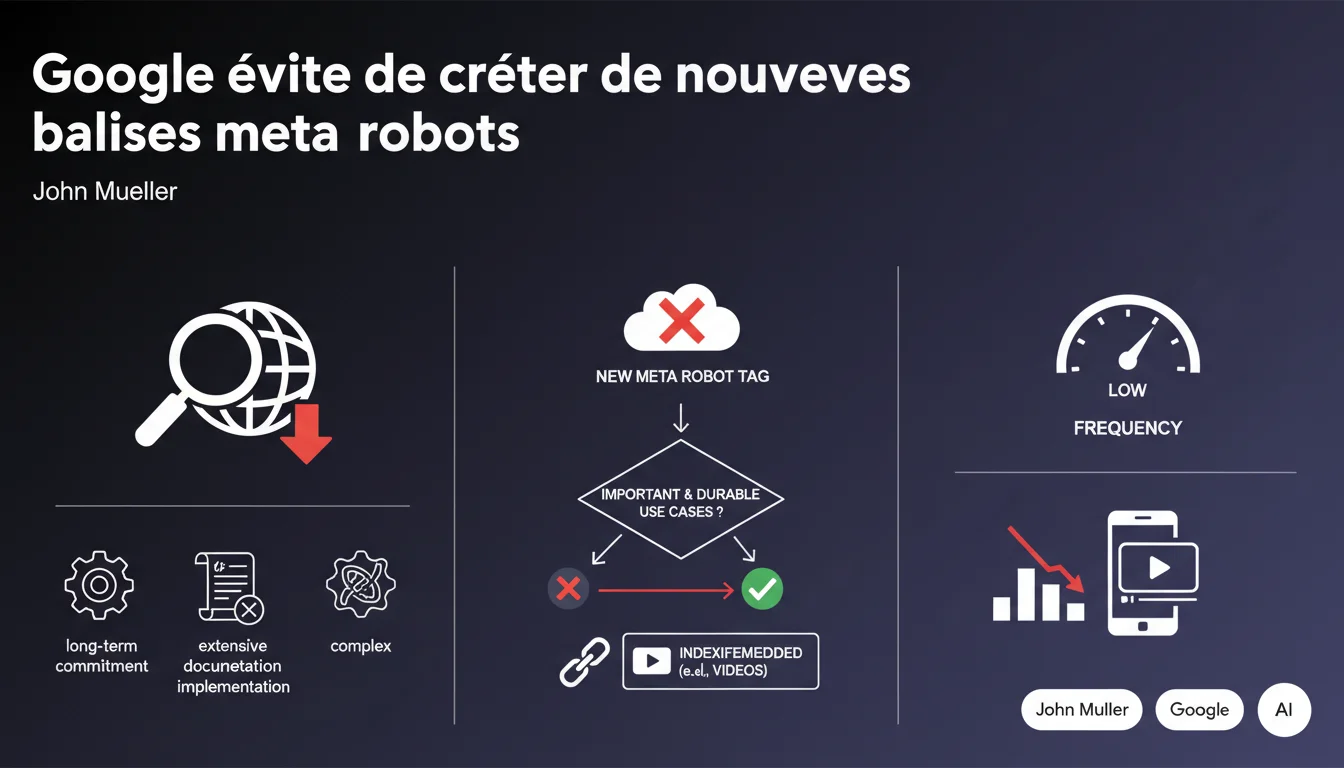
Google limite drastiquement la création de nouvelles balises meta robots à cause de l'engagement de maintenance à long terme qu'elles impliquent. Seuls les cas d'usage critiques et pérennes justifient leur développement, comme 'indexifembedded' pour les vidéos. Ne comptez pas sur de nouvelles directives robots pour résoudre vos problèmes d'indexation spécifiques.
Ce qu'il faut comprendre
Qu'est-ce qui freine Google dans le développement de nouvelles directives robots ?
La position de John Mueller est claire : chaque nouvelle balise meta robots représente un engagement technique et documentaire permanent. Une fois introduite, Google doit la supporter indéfiniment, maintenir la documentation à jour et gérer les cas limites d'implémentation.
Concrètement, cela signifie que l'équipe de Google doit arbitrer entre faciliter la vie des webmasters et la complexité croissante de leur propre infrastructure. Chaque directive supplémentaire multiplie les combinaisons possibles et les risques de conflits ou d'interprétations ambiguës.
Quels critères déterminent la création d'une nouvelle balise ?
Google n'introduit une nouvelle directive que si le cas d'usage est à la fois massif et impossible à résoudre autrement. L'exemple d''indexifembedded' illustre ce seuil : il répondait à un besoin structurel pour les plateformes vidéo, pas à une demande marginale.
Cette approche restrictive force les praticiens SEO à composer avec l'arsenal existant plutôt que d'attendre des solutions sur mesure. Si votre problème d'indexation ne concerne qu'une poignée de sites, il ne justifiera jamais une nouvelle balise.
Comment cette politique impacte-t-elle la boîte à outils SEO ?
La limitation volontaire du nombre de directives robots contraint les SEO à maîtriser parfaitement les balises existantes et leurs combinaisons. Noindex, nofollow, unavailable_after, max-snippet : chacune doit être exploitée dans toute sa subtilité.
- Google privilégie la stabilité technique à long terme plutôt que l'innovation rapide
- Les nouvelles balises sont réservées aux cas d'usage structurels affectant des millions de pages
- Les praticiens doivent composer avec un ensemble de directives relativement figé depuis des années
- La documentation et le support de chaque balise pèsent lourd dans les arbitrages de Google
- Les solutions créatives passent par la combinaison intelligente des outils existants, pas par l'attente de nouveaux
Avis d'un expert SEO
Cette frilosité est-elle vraiment nouvelle ?
Soyons honnêtes : Google n'a jamais été prolixe en matière de nouvelles balises meta. La dernière introduction significative remonte à plusieurs années. Ce que Mueller formalise ici, c'est une politique qui existe de facto depuis longtemps.
Ce qui change, c'est la transparence assumée sur les raisons. Et c'est là que ça coince : la question n'est pas tant de savoir si Google peut créer de nouvelles balises, mais si leur architecture actuelle le leur permet sans risques. L'argument du « coût de maintenance » cache peut-être une réalité technique plus contraignante qu'ils ne veulent l'admettre.
Quelles zones d'ombre subsistent dans cette déclaration ?
Mueller reste évasif sur ce qui constitue exactement un « cas d'usage important et durable ». [À vérifier] Combien de sites doivent être concernés ? Sur quelle durée ? Quels critères quantitatifs précis ?
De plus, cette position ignore complètement les demandes répétées de la communauté SEO pour des directives plus granulaires. Par exemple, une balise permettant de différencier contenu principal et contenu périphérique sans passer par le balisage schema – mais visiblement, ce besoin ne franchit pas le seuil de criticité de Google.
Cette position est-elle cohérente avec les pratiques observées ?
Sur le terrain, on constate effectivement que Google préfère modifier le comportement de balises existantes plutôt qu'en créer de nouvelles. L'évolution du traitement de 'nofollow' en « hint » plutôt qu'en directive absolue en est l'exemple parfait.
Ce que Mueller ne dit pas : cette stratégie transfère la complexité du côté de Google vers celui des webmasters. Au lieu d'une nouvelle balise claire, on se retrouve avec des comportements nuancés difficiles à anticiper et des cas limites non documentés.
Impact pratique et recommandations
Que faut-il faire concrètement avec cette information ?
Arrêtez d'attendre des solutions magiques de Google. Si votre problématique d'indexation nécessite une directive spécifique qui n'existe pas, elle n'existera probablement jamais. Concentrez-vous sur l'optimisation des leviers disponibles.
Cela signifie aussi qu'il faut documenter scrupuleusement vos choix d'implémentation actuels, car les balises que vous utilisez aujourd'hui seront supportées dans 5 ou 10 ans. Pas de risque d'obsolescence programmée — mais pas d'évolution non plus.
Quelles erreurs éviter face à cette limitation ?
Ne tombez pas dans le piège de sur-complexifier vos implémentations en combinant trop de directives. Chaque couche supplémentaire augmente le risque d'effets de bord non anticipés.
Autre erreur classique : utiliser des solutions JavaScript pour simuler des comportements que les balises meta ne permettent pas. Google crawle le JavaScript, certes, mais ajouter une couche d'abstraction fragilise votre architecture et complique le debugging.
Comment s'adapter stratégiquement à cette contrainte ?
L'approche la plus robuste consiste à concevoir l'architecture de vos sites en tenant compte des limites actuelles, pas de ce que vous aimeriez que Google propose. Si une fonctionnalité nécessite une balise inexistante, repensez la fonctionnalité.
- Auditer vos implémentations actuelles de balises meta robots pour identifier les usages non standard ou approximatifs
- Documenter précisément l'intention derrière chaque directive utilisée (pour maintenir la cohérence à long terme)
- Privilégier la simplicité : une directive claire vaut mieux que trois directives combinées dont l'interaction est floue
- Former vos équipes techniques sur les nuances des balises existantes plutôt que d'attendre de nouveaux outils
- Surveiller les mises à jour de la documentation Google sur les directives robots — les modifications de comportement sont plus probables que les nouveautés
- Prévoir des solutions architecturales alternatives pour les cas d'usage non couverts par les balises standards
❓ Questions frequentes
Google va-t-il créer une balise pour désindexer temporairement du contenu ?
Combien de balises meta robots Google supporte-t-il actuellement ?
Peut-on combiner plusieurs directives dans une seule balise meta robots ?
Que faire si mon besoin d'indexation n'est couvert par aucune balise existante ?
La balise indexifembedded est-elle vraiment utile pour tous les sites ?
🎥 De la même vidéo 13
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 30/06/2022
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.