Declaration officielle
Autres déclarations de cette vidéo 13 ▾
- □ Robots.txt bloque-t-il vraiment l'indexation de vos pages ?
- □ La balise meta 'none' est-elle vraiment l'équivalent de noindex + nofollow ?
- □ Peut-on bloquer l'indexation de répertoires entiers via des modules serveur plutôt que robots.txt ?
- □ Faut-il vraiment indexer les pages de connexion de votre site ?
- □ Faut-il vraiment préférer rel=canonical à noindex pour les contenus anciens ?
- □ La balise noarchive empêche-t-elle réellement Google d'archiver vos pages ?
- □ Faut-il bloquer les snippets avec nosnippet pour protéger son contenu sensible ?
- □ Faut-il vraiment utiliser max-snippet et max-image-preview pour contrôler l'affichage dans les SERP ?
- □ Faut-il privilégier l'attribut nofollow individuel ou la balise meta robots nofollow pour contrôler le PageRank ?
- □ Pourquoi Google refuse-t-il de créer de nouvelles balises meta robots ?
- □ Comment bloquer l'indexation de PDFs et fichiers non-HTML sans accès aux headers HTTP ?
- □ Pourquoi robots.txt bloque-t-il vraiment les images et vidéos mais pas les pages web ?
- □ Comment Google transforme-t-il vraiment vos PDFs en contenu indexable ?
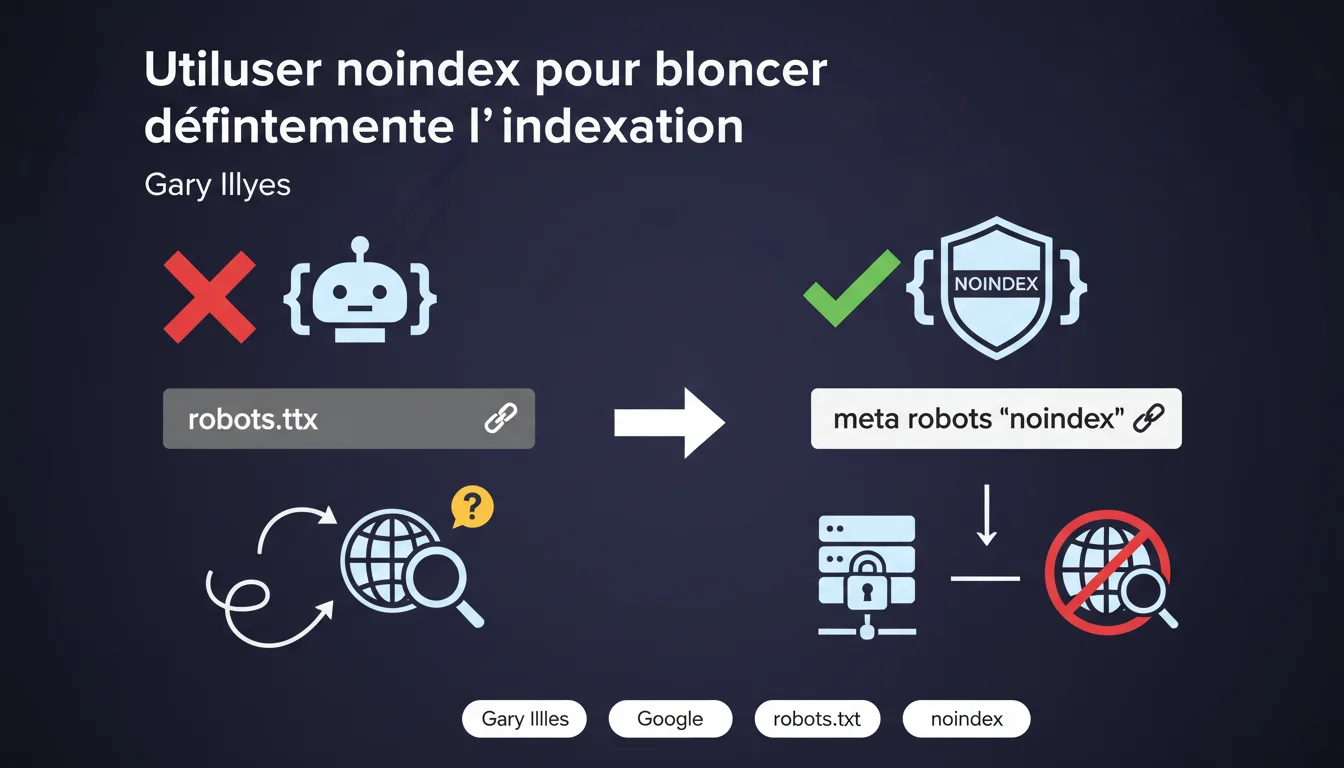
Gary Illyes affirme que robots.txt ne garantit pas le blocage de l'indexation dans Google Search. Seule la balise meta robots 'noindex' offre une protection fiable. Cette distinction technique n'est pas anodine : un fichier robots.txt empêche le crawl, mais n'empêche pas Google d'indexer une URL découverte par d'autres moyens.
Ce qu'il faut comprendre
Pourquoi robots.txt ne bloque-t-il pas l'indexation de manière fiable ?
Le fichier robots.txt est un mécanisme de directive de crawl, pas d'indexation. Il indique aux robots s'ils peuvent ou non explorer une URL. Mais si Google découvre cette URL via un backlink externe ou une mention quelque part, il peut l'indexer sans jamais la crawler.
Résultat : vous retrouvez dans l'index des pages avec une simple URL et un snippet générique, sans contenu visible. C'est exactement ce qui arrive quand on bloque par robots.txt une page qui reçoit des liens.
Quelle est la différence concrète entre noindex et robots.txt ?
Le noindex est une instruction d'indexation. Pour qu'elle soit prise en compte, Google doit pouvoir crawler la page et lire la balise meta ou l'en-tête HTTP. C'est une garantie : si Googlebot voit le noindex, la page sort de l'index ou n'y entre jamais.
À l'inverse, robots.txt empêche l'accès au contenu mais pas nécessairement à l'URL elle-même. Si cette URL est référencée ailleurs, Google peut décider de l'indexer avec les informations partielles dont il dispose.
Dans quels cas cette confusion pose-t-elle problème ?
Le cas classique : un site bloque des pages sensibles (admin, staging, paramètres UTM) via robots.txt en pensant les rendre invisibles. Ces pages continuent parfois d'apparaître dans les SERP avec un snippet tronqué.
Autre exemple fréquent : des landing pages obsolètes ou des pages de test bloquées par robots.txt mais toujours liées depuis d'anciens articles. Elles restent indexées tant que le noindex n'est pas appliqué directement.
- Robots.txt contrôle le crawl, pas l'indexation
- Noindex contrôle l'indexation de manière définitive
- Une URL bloquée par robots.txt peut quand même apparaître dans l'index si elle reçoit des liens
- Pour garantir l'exclusion de l'index, il faut que Googlebot puisse crawler la page et lire le noindex
- Bloquer par robots.txt + noindex simultanément est contradictoire et inefficace
Avis d'un expert SEO
Cette déclaration est-elle cohérente avec les observations terrain ?
Oui, complètement. C'est même un classique des audits SEO : des dizaines de pages indexées avec le message « Aucune information disponible sur cette page » parce qu'elles sont bloquées dans robots.txt mais continuent de recevoir des backlinks.
Le paradoxe ? Certains SEO utilisent encore robots.txt pour « cacher » des contenus sensibles, alors que c'est exactement l'inverse de ce qu'il faut faire. Cette confusion vient probablement d'une époque où les outils étaient moins explicites sur la distinction crawl/indexation.
Quelles nuances faut-il apporter à cette directive ?
Gary Illyes ne précise pas un point essentiel : pour que le noindex fonctionne, il faut autoriser le crawl. Si vous bloquez une page dans robots.txt ET que vous ajoutez un noindex dessus, Google ne verra jamais la balise. La page risque donc de rester indexée indéfiniment.
Deuxième nuance — la temporalité. Une page en noindex peut mettre plusieurs semaines à sortir de l'index si elle est peu crawlée ou si elle a beaucoup de backlinks. Ce n'est pas instantané, contrairement à ce que certains imaginent. [À vérifier] : Google n'a jamais communiqué de délai officiel pour la désindexation complète d'une page en noindex.
Que faire si vous voulez bloquer le crawl ET l'indexation ?
C'est là que ça coince. Si vous voulez vraiment interdire l'accès ET garantir l'absence d'indexation, la solution propre est double : noindex + authentification serveur (password, IP whitelisting). Ou bien noindex le temps que la page sorte de l'index, puis blocage robots.txt.
Mais dans 90 % des cas, il suffit d'un noindex propre. Le blocage robots.txt est rarement nécessaire pour des raisons d'indexation — il sert surtout à économiser du crawl budget sur des sections inutiles.
Impact pratique et recommandations
Que faut-il faire concrètement sur un site en production ?
Premier réflexe : auditer les pages bloquées par robots.txt qui apparaissent encore dans l'index. Utilisez la commande site:votredomaine.com dans Google et comparez avec votre fichier robots.txt. Toute URL indexée malgré un Disallow est une faille potentielle.
Ensuite, listez toutes les pages que vous voulez réellement exclure de l'index. Pour chacune, appliquez un noindex via meta robots ou en-tête HTTP X-Robots-Tag. Vérifiez que ces pages ne sont PAS bloquées dans robots.txt, sinon Google ne verra jamais la directive.
Quelles erreurs éviter dans la gestion de l'indexation ?
Erreur n°1 : bloquer par robots.txt en pensant que ça désindexe. Ça ne désindexe pas. Ça empêche juste le crawl, et parfois ça maintient l'URL dans l'index si elle reçoit des liens.
Erreur n°2 : appliquer noindex + robots.txt sur la même page. Résultat : Google ne peut pas crawler pour lire le noindex. La page reste potentiellement indexée avec un snippet vide.
Erreur n°3 : croire que le noindex agit instantanément. Non. La désindexation dépend de la fréquence de crawl et de la « force » des signaux externes (backlinks, sitemap, etc.).
Comment vérifier que votre configuration est correcte ?
Utilisez la Google Search Console, outil Inspection d'URL. Entrez l'URL concernée et vérifiez trois points : est-elle crawlable ? Le noindex est-il détecté ? Quel est son statut d'indexation actuel ?
Si la page est indexée malgré un noindex récent, patience. Si elle est indexée et que le noindex n'est pas détecté, vérifiez votre robots.txt. Si le noindex est détecté mais la page toujours présente après plusieurs semaines, [À vérifier] il peut y avoir un problème de signaux contradictoires (sitemap, liens internes massifs).
- Supprimer toutes les directives Disallow dans robots.txt pour les pages que vous voulez désindexer
- Ajouter une balise
<meta name="robots" content="noindex">dans le <head> de chaque page à exclure - Vérifier dans la Search Console que le noindex est bien détecté
- Retirer ces pages du sitemap XML pour éviter les signaux contradictoires
- Surveiller l'indexation avec
site:votredomaine.comtoutes les 2-3 semaines - Garder le crawl autorisé jusqu'à désindexation complète, puis bloquer si nécessaire
❓ Questions frequentes
Peut-on utiliser robots.txt ET noindex sur la même page ?
Combien de temps faut-il pour qu'une page en noindex sorte de l'index ?
Si je bloque une page dans robots.txt, pourquoi apparaît-elle encore dans Google ?
Faut-il retirer une page en noindex du sitemap XML ?
Le noindex fonctionne-t-il aussi en en-tête HTTP ?
🎥 De la même vidéo 13
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 30/06/2022
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.