Declaration officielle
Autres déclarations de cette vidéo 13 ▾
- □ Robots.txt bloque-t-il vraiment l'indexation de vos pages ?
- □ La balise meta 'none' est-elle vraiment l'équivalent de noindex + nofollow ?
- □ Robots.txt est-il vraiment inefficace pour bloquer l'indexation ?
- □ Peut-on bloquer l'indexation de répertoires entiers via des modules serveur plutôt que robots.txt ?
- □ Faut-il vraiment indexer les pages de connexion de votre site ?
- □ Faut-il vraiment préférer rel=canonical à noindex pour les contenus anciens ?
- □ Faut-il bloquer les snippets avec nosnippet pour protéger son contenu sensible ?
- □ Faut-il vraiment utiliser max-snippet et max-image-preview pour contrôler l'affichage dans les SERP ?
- □ Faut-il privilégier l'attribut nofollow individuel ou la balise meta robots nofollow pour contrôler le PageRank ?
- □ Pourquoi Google refuse-t-il de créer de nouvelles balises meta robots ?
- □ Comment bloquer l'indexation de PDFs et fichiers non-HTML sans accès aux headers HTTP ?
- □ Pourquoi robots.txt bloque-t-il vraiment les images et vidéos mais pas les pages web ?
- □ Comment Google transforme-t-il vraiment vos PDFs en contenu indexable ?
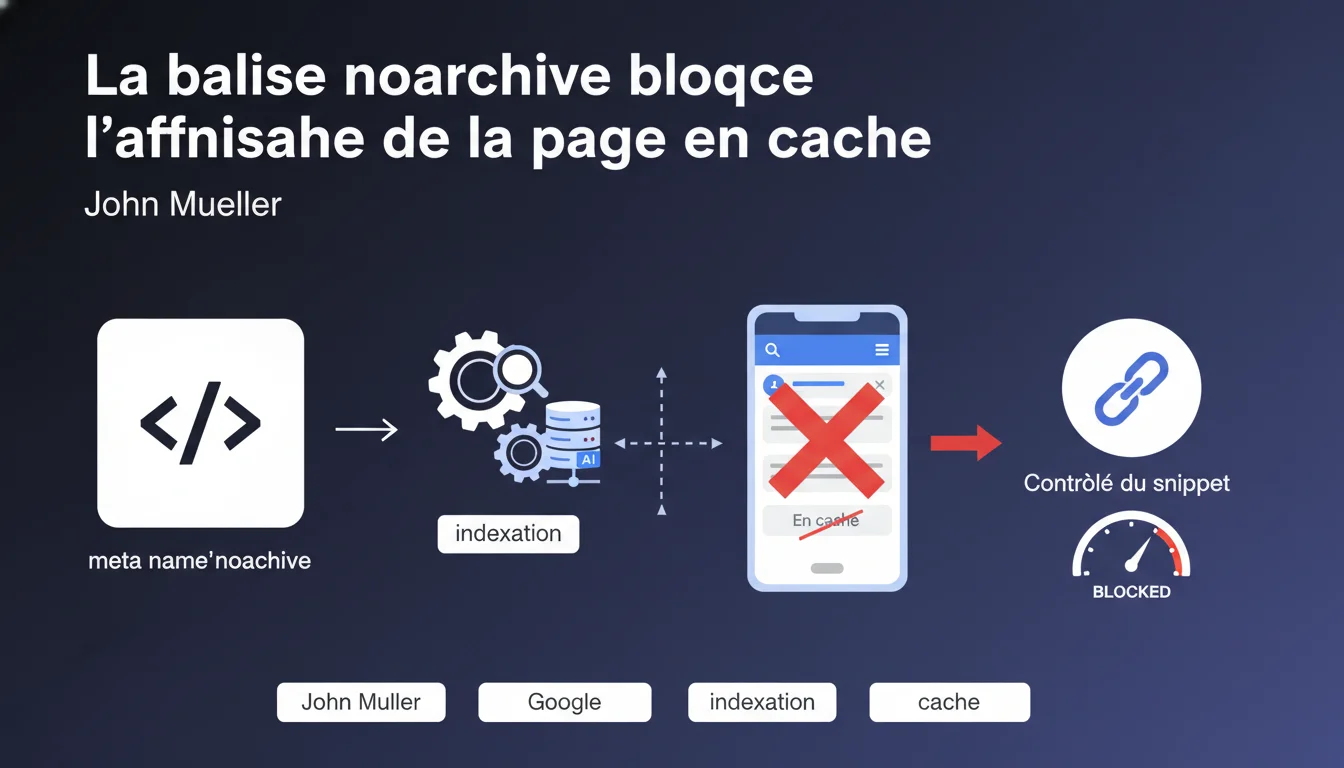
La balise meta 'noarchive' ne bloque pas l'archivage interne de Google — le moteur a besoin de cet archivage pour indexer. Elle supprime simplement le lien 'En cache' dans les SERP. C'est un contrôle d'affichage du snippet, pas une directive d'indexation.
Ce qu'il faut comprendre
Quelle est la différence entre archivage interne et lien 'En cache' ?
Google archive systématiquement les pages qu'il indexe. Cet archivage interne est indispensable au fonctionnement du moteur : il permet de comparer les versions successives d'une page, d'analyser son contenu, de détecter les modifications. Sans cette archive, pas d'indexation possible.
Le lien 'En cache' visible dans les résultats de recherche est une fonctionnalité publique distincte. Il offre aux utilisateurs l'accès à la version archivée de la page. La balise noarchive coupe ce lien — mais l'archive interne reste active.
Pourquoi cette distinction existe-t-elle ?
Certains sites ne veulent pas exposer publiquement leurs versions archivées. Contenus confidentiels, prix dynamiques, informations sensibles — les raisons varient. Google respecte ce choix via noarchive, tout en conservant sa capacité technique d'indexation.
C'est un compromis entre besoins techniques du moteur et contrôle éditorial du propriétaire de site.
Qu'est-ce que cela implique pour le snippet ?
Mueller classe explicitement noarchive parmi les contrôles de snippet. Au même titre que nosnippet ou max-snippet, elle modifie ce que Google affiche dans les SERP sans toucher à l'indexation elle-même.
- La balise noarchive supprime uniquement le lien 'En cache' dans les résultats de recherche
- L'archivage interne de Google reste actif — c'est une condition technique de l'indexation
- Il s'agit d'un contrôle d'affichage, pas d'une directive robotique
- Elle peut se combiner avec d'autres directives de snippet (nosnippet, max-snippet)
- Aucun impact sur le crawl budget ou la fréquence d'exploration
Avis d'un expert SEO
Cette clarification résout-elle réellement les confusions terrain ?
Soyons honnêtes : beaucoup de praticiens pensaient que noarchive empêchait toute forme d'archivage. La formulation même — « no archive » — prête à confusion. Mueller clarifie un malentendu ancien, mais la terminologie reste ambiguë.
Sur le terrain, on observe effectivement que des pages avec noarchive continuent d'être indexées normalement, avec des mises à jour régulières. Le comportement de Google correspond à ce qu'il décrit. Pas de surprise ici.
Quels cas d'usage justifient vraiment l'emploi de noarchive ?
En pratique ? Très peu. Les sites qui affichent des prix en temps réel (billets d'avion, hôtels) peuvent vouloir éviter qu'un cache obsolète circule. Idem pour du contenu à accès restreint ou des pages avec données personnelles visibles.
Mais attention — et c'est là que ça coince : si votre contenu est vraiment confidentiel, pourquoi est-il indexable ? La logique voudrait qu'on utilise noindex ou une restriction d'accès via robots.txt. Utiliser noarchive seul relève souvent d'une stratégie mal calibrée.
Y a-t-il un impact SEO indirect à considérer ?
Techniquement, non. Mueller est clair : c'est un contrôle de snippet, pas un signal de classement. [À vérifier] : certains observateurs suggèrent que supprimer systématiquement le cache pourrait nuire à la confiance utilisateur dans les SERP — mais aucune donnée solide là-dessus.
Ce qui est certain : si vous masquez le cache sur des pages clés sans raison, vous privez les utilisateurs d'un point de repli en cas d'indisponibilité de votre serveur. C'est rarement un bon calcul.
Impact pratique et recommandations
Faut-il retirer noarchive de mes pages actuelles ?
Commence par un audit. Identifie toutes les pages portant cette balise — via Screaming Frog, Search Console ou un crawl personnalisé. Pour chaque page, pose-toi la question : y a-t-il une raison légitime de masquer le cache ?
Si la réponse est non, retire la directive. Si la réponse est oui, demande-toi ensuite : cette page devrait-elle même être indexée ? Souvent, la vraie solution est noindex, pas noarchive.
Comment implémenter noarchive correctement si nécessaire ?
La syntaxe est simple : <meta name="robots" content="noarchive"> dans le <head> de la page. Elle peut se combiner avec d'autres directives : content="index, follow, noarchive".
Vérifie que ton serveur ne bloque pas les ressources nécessaires au rendu de la page. Si Google ne peut pas voir la balise parce que ton CSS/JS est bloqué, elle n'aura aucun effet.
Quelles erreurs fréquentes faut-il éviter ?
L'erreur classique : utiliser noarchive comme substitut à noindex sur du contenu vraiment sensible. Ce n'est pas le bon outil. Google archive toujours la page en interne — seul l'affichage public du cache est coupé.
Autre piège : appliquer noarchive en masse via un template global. Certains CMS le font par défaut sur toutes les pages. Résultat : aucun de vos contenus n'affiche de cache, sans raison. C'est contre-productif.
- Auditer les pages portant actuellement la balise noarchive
- Vérifier que chaque usage est justifié par un besoin réel (prix dynamiques, contenu sensible)
- Privilégier noindex pour du contenu vraiment confidentiel
- Tester l'affichage du cache après retrait de la directive (Google Search Console)
- Documenter les exceptions : quelles pages conservent noarchive, et pourquoi
- Éviter l'application globale via templates par défaut
❓ Questions frequentes
La balise noarchive ralentit-elle l'indexation de mes pages ?
Puis-je combiner noarchive avec d'autres directives robots ?
Si je retire noarchive, combien de temps avant que le lien 'En cache' réapparaisse ?
Noarchive empêche-t-il les outils d'archivage tiers comme Wayback Machine ?
Y a-t-il un impact SEO si je masque le cache sur toutes mes pages ?
🎥 De la même vidéo 13
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 30/06/2022
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.