Declaration officielle
Autres déclarations de cette vidéo 13 ▾
- □ La balise meta 'none' est-elle vraiment l'équivalent de noindex + nofollow ?
- □ Robots.txt est-il vraiment inefficace pour bloquer l'indexation ?
- □ Peut-on bloquer l'indexation de répertoires entiers via des modules serveur plutôt que robots.txt ?
- □ Faut-il vraiment indexer les pages de connexion de votre site ?
- □ Faut-il vraiment préférer rel=canonical à noindex pour les contenus anciens ?
- □ La balise noarchive empêche-t-elle réellement Google d'archiver vos pages ?
- □ Faut-il bloquer les snippets avec nosnippet pour protéger son contenu sensible ?
- □ Faut-il vraiment utiliser max-snippet et max-image-preview pour contrôler l'affichage dans les SERP ?
- □ Faut-il privilégier l'attribut nofollow individuel ou la balise meta robots nofollow pour contrôler le PageRank ?
- □ Pourquoi Google refuse-t-il de créer de nouvelles balises meta robots ?
- □ Comment bloquer l'indexation de PDFs et fichiers non-HTML sans accès aux headers HTTP ?
- □ Pourquoi robots.txt bloque-t-il vraiment les images et vidéos mais pas les pages web ?
- □ Comment Google transforme-t-il vraiment vos PDFs en contenu indexable ?
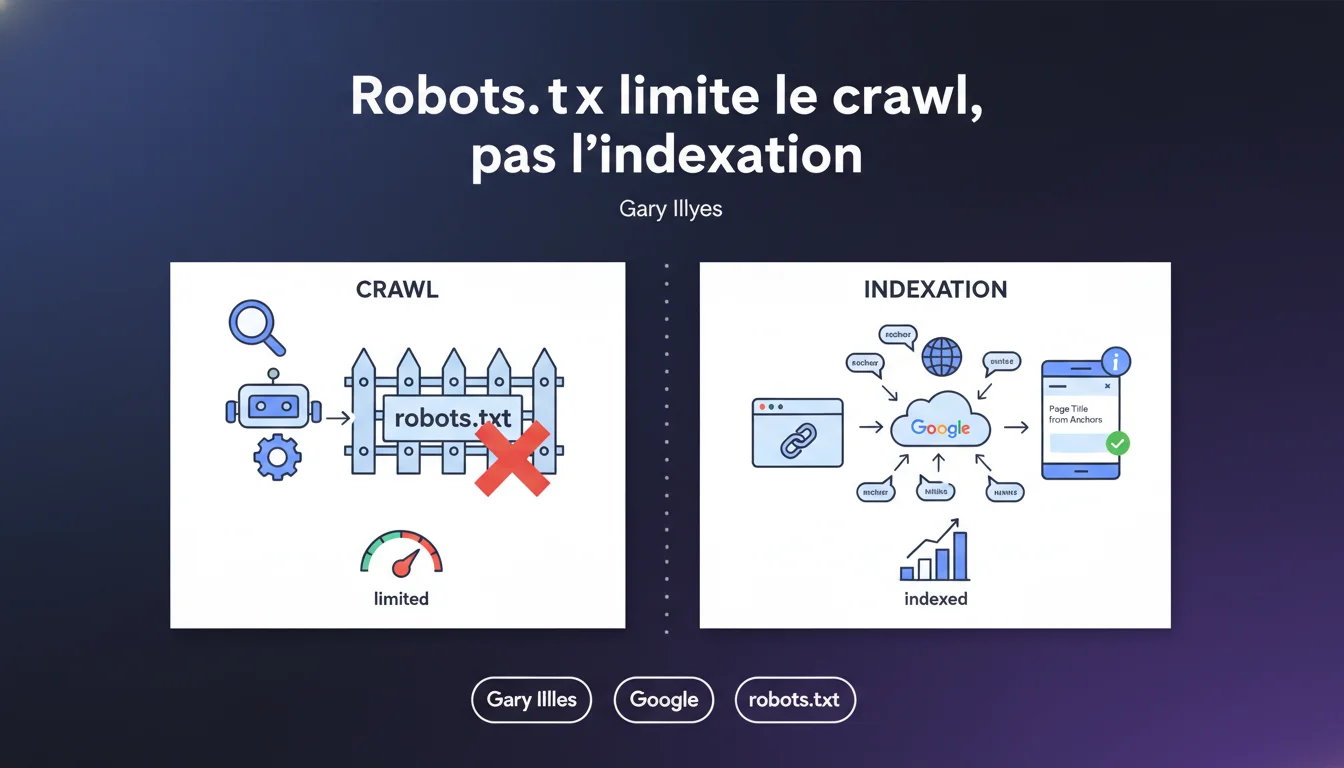
Le robots.txt empêche le crawl, pas l'indexation. Si une URL reçoit suffisamment de backlinks, Google peut l'indexer sans jamais avoir crawlé son contenu — elle apparaîtra dans les résultats avec un titre déduit des ancres et sans meta description. Cette confusion coûte cher à beaucoup de sites qui croient se protéger avec un simple Disallow.
Ce qu'il faut comprendre
Quelle est la différence entre crawl et indexation ?
Le crawl est l'action de visiter une page pour en récupérer le contenu. L'indexation est la décision de stocker cette URL dans l'index de Google pour qu'elle apparaisse dans les résultats. Ce sont deux processus distincts — et c'est là que tout se complique.
Quand vous bloquez une URL dans robots.txt, vous interdisez à Googlebot de la visiter. Mais si cette page accumule des backlinks externes, Google sait qu'elle existe. Il peut alors choisir de l'indexer sans jamais avoir lu son contenu, en se basant uniquement sur les signaux externes.
Comment Google indexe-t-il une page bloquée par robots.txt ?
Google découvre l'URL via des liens entrants. Sans accès au contenu, il construit le résultat de recherche avec ce qu'il a : les ancres de liens pointant vers la page servent à générer un titre approximatif. La meta description reste vide ou affiche un message générique.
Le résultat est moche, peu cliquable, mais présent dans l'index. Pour des pages sensibles (admin, staging, contenus privés), c'est un problème de sécurité potentiel — l'URL est visible publiquement même si le contenu reste inaccessible.
Pourquoi cette confusion persiste-t-elle chez tant de professionnels ?
Parce que pendant longtemps, la documentation Google a été floue sur ce point. Beaucoup de SEO pensent encore que robots.txt = protection totale. C'est faux. Un Disallow protège votre crawl budget, pas votre confidentialité.
- Le robots.txt contrôle uniquement ce que Googlebot peut explorer, pas ce qu'il peut indexer
- Une page bloquée mais très linkée peut apparaître dans les SERP avec un snippet vide
- Pour vraiment bloquer l'indexation, il faut une balise noindex (qui nécessite que la page soit crawlable)
- Le robots.txt ne protège pas les contenus sensibles — utilisez l'authentification ou les en-têtes HTTP
Avis d'un expert SEO
Cette déclaration est-elle cohérente avec les observations terrain ?
Oui, à 100%. Sur des milliers d'audits, j'ai vu des dizaines de sites indexés sur des URLs bloquées en robots.txt — staging environments, paramètres de filtres, pages admin. Le pattern est toujours le même : backlinks externes + robots.txt mal configuré = fuite d'indexation.
Le cas classique : un dev met un site de preprod en robots.txt Disallow complet, mais oublie de couper les liens depuis la prod. Résultat ? Google indexe l'URL de staging avec un titre générique type "Index of /staging". Visible dans les SERP, désastre en termes d'image.
Où cette règle montre-t-elle ses limites ?
Google dit "si une page devient très populaire avec de nombreux liens". Mais combien de liens ? Quel PageRank minimum ? [À vérifier] — cette partie reste volontairement vague. Sur le terrain, j'ai observé des indexations avec aussi peu que 3-4 backlinks de sites moyennement autoritaires.
Autre zone grise : que se passe-t-il si vous ajoutez un robots.txt Disallow sur une page déjà indexée ? Google maintient l'indexation, mais ne peut plus recrawler pour mettre à jour le contenu. L'URL reste dans l'index, figée dans le temps — souvent avec des infos obsolètes. Pratique quand on veut effacer une page rapidement ? Non. Il faut attendre la désindexation naturelle ou passer par la Search Console.
Quand cette logique devient-elle problématique ?
Pour les sites avec contenus sensibles. J'ai vu des tableaux de prix B2B, des accès clients, des pages de politique interne apparaître dans Google — URL visible, contenu protégé par robots.txt. Techniquement conforme à ce que dit Gary Illyes, mais catastrophique en pratique.
Impact pratique et recommandations
Que faut-il faire concrètement pour éviter ce piège ?
D'abord, arrêtez d'utiliser robots.txt comme outil de désindexation. Son rôle est de gérer le crawl budget et de protéger des ressources serveur, pas de cacher des contenus. Pour désindexer proprement, la seule méthode fiable : balise meta noindex ou en-tête HTTP X-Robots-Tag.
Ensuite, auditez vos URLs bloquées actuellement. Allez dans Google Search Console > Paramètres > Fichier robots.txt, récupérez la liste des Disallow, puis vérifiez combien sont indexées avec un site:votredomaine.com/url-bloquee. Vous serez surpris.
Comment corriger une page indexée malgré un robots.txt ?
Paradoxe : pour désindexer, Google doit pouvoir recrawler la page. Donc vous devez temporairement retirer le Disallow, ajouter une balise noindex, attendre la désindexation (quelques jours à quelques semaines selon la fréquence de crawl), puis remettre le robots.txt si nécessaire.
Alternative rapide mais risquée : demande de suppression d'URL via Search Console. Ça masque l'URL pendant ~6 mois, mais ce n'est pas permanent. Si la page reste crawlable et sans noindex, elle reviendra.
Quelles erreurs éviter absolument ?
- Ne bloquez JAMAIS en robots.txt une page que vous voulez désindexer — utilisez noindex
- Ne mettez pas de noindex sur une page bloquée en robots.txt — Google ne pourra pas lire la directive
- Ne comptez pas sur robots.txt pour protéger des données sensibles — authentifiez au niveau serveur
- Ne bloquez pas /wp-admin/ ou /admin/ en robots.txt si ces URLs reçoivent des backlinks — indexation garantie
- Vérifiez régulièrement les URLs indexées malgré un Disallow avec un site: search
Le robots.txt est un outil de gestion du crawl, pas une barrière d'indexation. Pour vraiment contrôler ce qui apparaît dans Google, vous devez maîtriser la différence entre crawl, indexation, et les directives adaptées à chaque cas.
Ces distinctions techniques peuvent sembler subtiles, mais leurs implications sont majeures — une mauvaise configuration expose des URLs sensibles ou gaspille du crawl budget sur des pages inutiles. Si votre architecture combine paramètres dynamiques, contenus en staging et zones privées, l'accompagnement d'une agence SEO spécialisée peut vous éviter des erreurs coûteuses et accélérer la mise en conformité.
❓ Questions frequentes
Puis-je utiliser robots.txt pour empêcher Google d'indexer une page ?
Comment désindexer une page actuellement bloquée en robots.txt ?
Combien de backlinks suffisent pour qu'une page bloquée soit indexée ?
Que se passe-t-il si j'ajoute un robots.txt sur une page déjà indexée ?
Comment protéger vraiment des contenus sensibles de l'indexation ?
🎥 De la même vidéo 13
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 30/06/2022
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.