Official statement
Other statements from this video 20 ▾
- □ Les liens internes dans le header ou le footer ont-ils moins de valeur SEO ?
- □ Google pénalise-t-il vraiment un site qui achète des liens en masse ?
- □ Faut-il vraiment viser la perfection technique pour bien ranker sur Google ?
- □ Pourquoi Google crawle-t-il moins votre site s'il le trouve de mauvaise qualité ?
- □ Les données structurées invalides peuvent-elles pénaliser votre référencement ?
- □ Faut-il s'inquiéter d'une baisse du nombre de pages indexées ?
- □ Crawlée non indexée vs Découverte non indexée : vraiment équivalent ?
- □ Peut-on vraiment contrôler les images affichées dans les snippets Google ?
- □ Pourquoi Google pénalise-t-il le contenu dupliqué entre sites de franchises ?
- □ CCTLD, sous-domaine ou sous-répertoire : quelle structure pour le géociblage international ?
- □ Le code 503 protège-t-il vraiment vos pages de la désindexation en cas de panne ?
- □ Les liens dofollow accidentels dans vos RP vont-ils vous pénaliser ?
- □ Peut-on vraiment utiliser l'outil de changement d'adresse pour fusionner ou diviser des sites ?
- □ Pourquoi vos données structurées disparaissent-elles sur vos pages localisées ?
- □ Les données structurées améliorent-elles vraiment le référencement ou juste l'affichage ?
- □ Google va-t-il un jour afficher les Core Web Vitals directement dans les résultats de recherche ?
- □ Restructuration d'URL : pourquoi Google provoque-t-il des fluctuations pendant deux mois ?
- □ Le linking interne surpasse-t-il vraiment la structure d'URL pour le SEO ?
- □ Faut-il vraiment calculer le PageRank interne pour optimiser son site ?
- □ Google peut-il vraiment identifier la langue principale d'une page multilingue sans pénaliser votre SEO ?
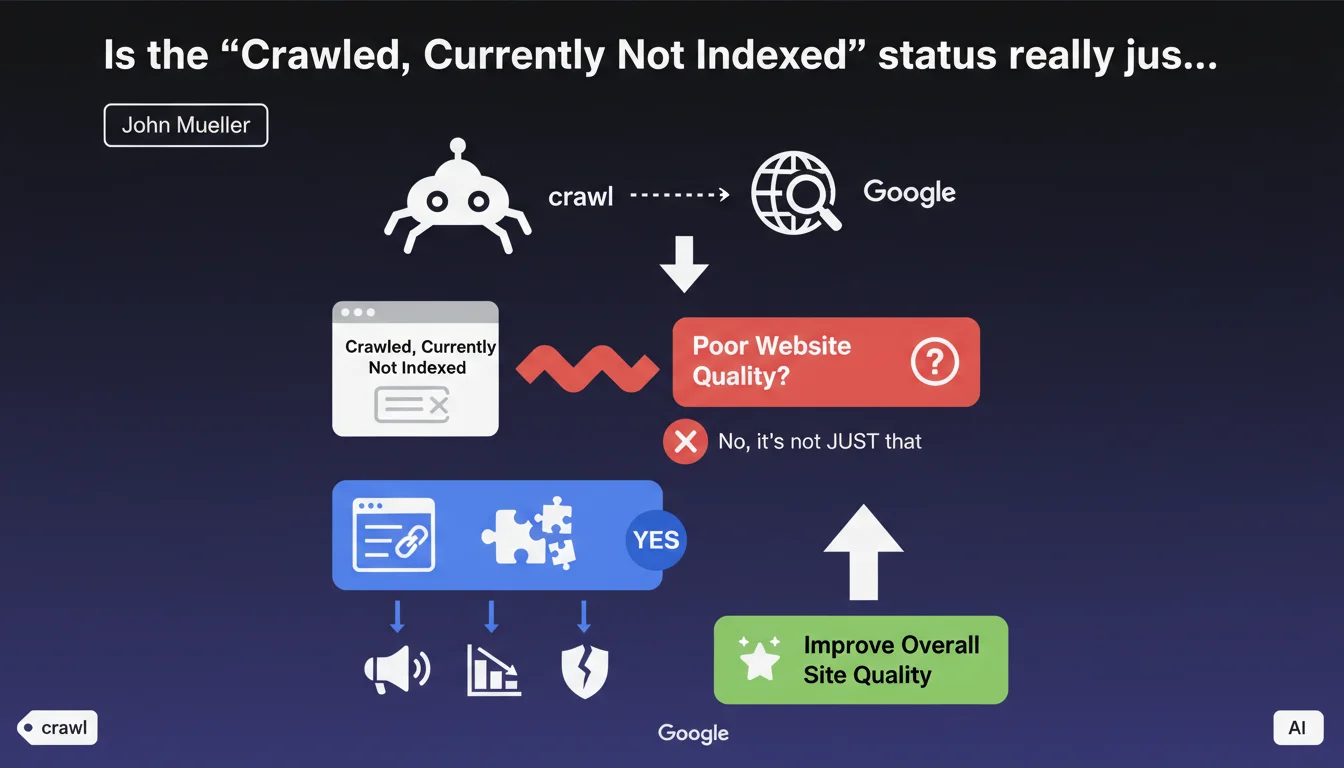
Google states that the 'Crawled, Currently Not Indexed' status generally reflects a lack of confidence in the overall quality of the website. The official recommendation: significantly improve the quality of the entire site, not just the affected pages. Contrary to popular belief, it's not just a technical issue or crawl budget problem.
What you need to understand
What does this status really mean in Search Console?
The 'Crawled, Currently Not Indexed' status appears when Googlebot visits a page but deliberately decides not to add it to its index. It's not a bug, nor an accessibility problem. The robot saw the page, analyzed it, and concluded it didn't deserve to be indexed.
The nuance is critical: Google is making a deliberate choice. This isn't a page blocked by robots.txt, nor a server error. The page is technically accessible, but deemed insufficiently relevant or high-quality to occupy a place in the index.
Why does Google emphasize the 'overall' quality of the site?
John Mueller insists on a point rarely understood: this status reflects an evaluation that goes beyond the individual page. Google looks at the site as a whole. If too many pages lack added value, this degrades the overall perception of the domain.
In concrete terms, even a decent page can be excluded if it sits on a site where the majority of content is weak. Google applies a form of trust score to the domain, which influences indexation decisions across the entire site.
What are the main quality factors involved?
- Thin or duplicate content: pages with little unique text, nearly identical variations, automatically generated content without value
- Degraded user experience: excessive load times, intrusive interstitials, problematic page layout
- Lack of authority signals: absence of quality backlinks, low user engagement, new domain without history
- Over-optimization: too many artificially created pages (facets, filters, excessive pagination) without distinct value
- Structural issues: confused architecture, chaotic internal linking, poorly designed silos
SEO Expert opinion
Does this statement match real-world observations?
Yes, largely. Audits of sites showing this status in large quantities almost always reveal systemic quality problems. It's never simply a crawl budget issue — if it were, Google wouldn't even crawl these pages in the first place.
However, the phrase 'significantly improve overall quality' remains intentionally vague. Google doesn't specify exact criteria or thresholds. We do observe, however, that sites with a high ratio of weak content (>40% of pages) are particularly affected. [To verify] : no official data quantifies this threshold.
What nuances should be applied to this rule?
Not all cases of 'Crawled, Not Indexed' necessarily stem from a quality deficit. Some legitimate scenarios exist: order confirmation pages, intermediate steps in funnels, pages with noindex tag that was forgotten then recently removed.
Additionally, new sites often experience this status temporarily, even with decent content. Google adopts a cautious stance with domains lacking history. The phenomenon typically disappears after a few weeks if quality is there.
In what cases is this recommendation insufficient?
Improving overall quality won't solve everything if technical blockers coexist. For example: anarchic canonicalization, poorly managed pagination, or defective hreflang. These issues require specific fixes, not just 'more quality'.
Another limitation: certain e-commerce sites with thousands of very similar product sheets (color, size variations) encounter this status even with correct content. Google can't index everything. In this case, the solution involves strategic consolidation (combined pages, aggressive canonicalization) rather than just copy improvements.
Practical impact and recommendations
What should you concretely do when facing this status?
First, identify the scope of the problem. If 5% of your pages are affected, that's not alarming. If it's 40%, you have a structural issue. Export the list from Search Console and look for patterns: page types, site sections, publication dates.
Next, audit the real quality of these pages. Compare them to indexed pages: are they truly less rich? Shorter? Less internally linked? Often, you'll discover entire categories of weak content that should be merged or removed.
What priority actions should you implement?
- Substantially enrich strategic pages (add a minimum of 300-500 unique words, structured data, quality visuals)
- Remove or consolidate redundant pages without added value (use 301 redirects)
- Strengthen internal linking to important non-indexed pages (contextual links from strong pages)
- Improve engagement signals: speed, Core Web Vitals, mobile responsiveness
- Build backlinks to entire site sections, not just the homepage
- Review architecture: simplify depth levels, clarify thematic silos
How do you measure the effectiveness of corrections?
Track the status evolution in Search Console over 4 to 8 weeks. Quality improvements don't produce immediate effects. Google must recrawl, reevaluate, and adjust its perception of the domain.
Also monitor indirect metrics: overall crawl rate (should increase if Google revalues the site), number of indexed pages (via site: operator), and especially organic traffic to previously non-indexed pages. If nothing changes after 2 months, your improvements are insufficient or poorly targeted.
❓ Frequently Asked Questions
Le statut « Crawlée, non indexée » disparaît-il si je soumets à nouveau les URLs via la Search Console ?
Combien de temps faut-il pour qu'une page passe de « Crawlée, non indexée » à indexée après amélioration ?
Est-ce que toutes les pages d'un site doivent être indexées ?
Supprimer des pages non indexées peut-il aider les autres pages à être indexées ?
Un site récent subit-il ce statut même avec du bon contenu ?
🎥 From the same video 20
Other SEO insights extracted from this same Google Search Central video · published on 21/01/2022
🎥 Watch the full video on YouTube →
💬 Comments (0)
Be the first to comment.