Official statement
Other statements from this video 10 ▾
- □ Les chaînes de redirections bloquent-elles vraiment le crawl de Google sur votre site ?
- □ Pourquoi les problèmes d'indexation se concentrent-ils sur certains dossiers de votre site ?
- □ Le no-index libère-t-il vraiment du crawl budget pour les pages importantes ?
- □ Les chaînes de redirections tuent-elles vraiment l'expérience utilisateur ?
- □ Faut-il vraiment supprimer toutes les redirections internes de votre site ?
- □ Pourquoi Google ralentit-il son crawl quand votre serveur faiblit ?
- □ L'instabilité serveur peut-elle vraiment déclasser votre site dans Google ?
- □ Faut-il vraiment multiplier les outils de crawl pour diagnostiquer efficacement vos problèmes SEO ?
- □ Pourquoi faut-il détecter les erreurs techniques avant que Google ne les trouve ?
- □ Les Developer Tools du navigateur suffisent-ils vraiment pour auditer vos redirections SEO ?
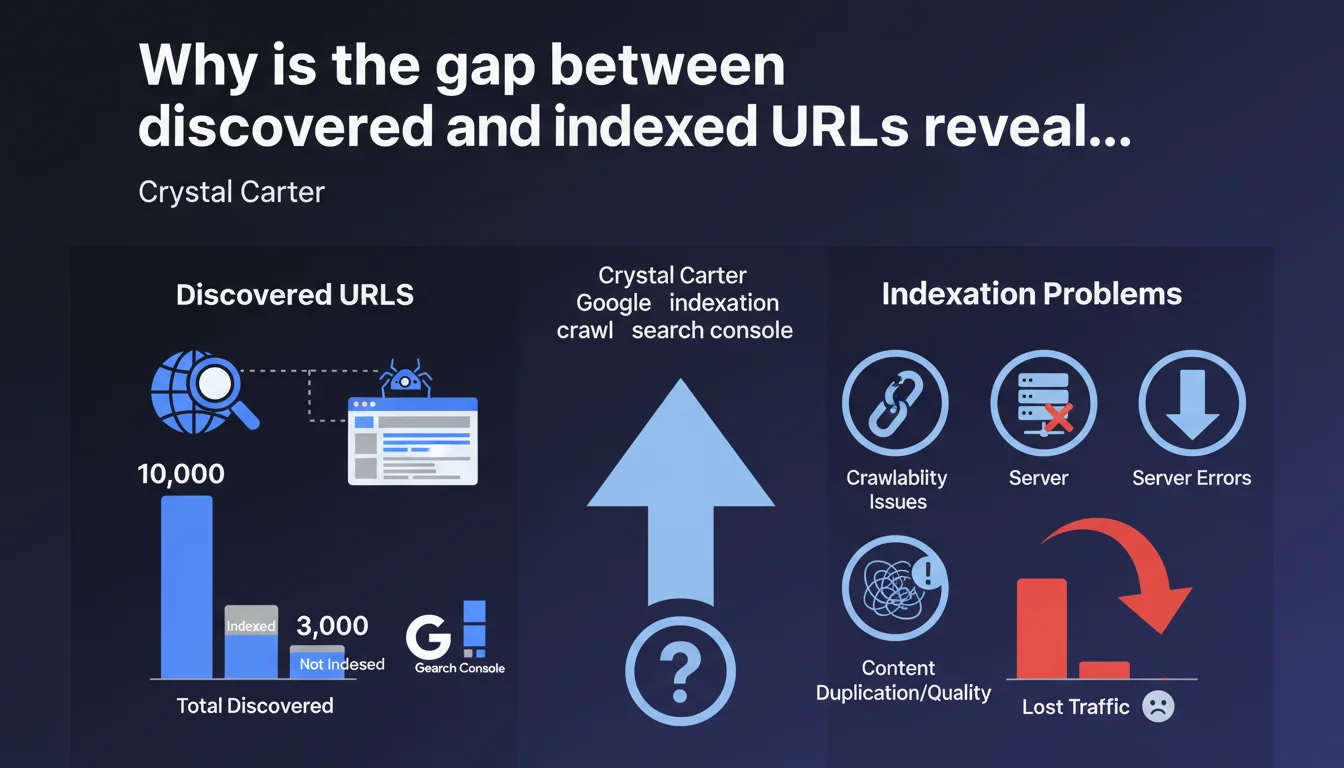
Google Search Console now clearly distinguishes between discovered URLs and those actually indexed. A significant gap between these two metrics signals structural crawlability or indexation issues that block your visibility. This is a key indicator to monitor systematically to diagnose what's preventing your content from reaching the index.
What you need to understand
What's the actual difference between discovery and indexation in Search Console?
Google discovers a URL when its crawler detects it — through a sitemap, an internal link, or an external backlink. But discovery doesn't mean indexation. Indexation happens after crawling, when Google decides to store the page in its index and make it eligible for ranking.
Search Console now exposes these two states separately. You see how many URLs Google knows about, and how many it has actually indexed. The gap between the two is your blind spot.
Why should this gap concern you?
A discovered but non-indexed URL is invisible content. No matter how high quality, it generates zero organic traffic. Possible causes include insufficient crawl budget, accidental noindex tags, duplicate content, misconfigured canonicals, orphaned pages without internal linking, or content simply deemed irrelevant by Google.
If you're seeing thousands of discovered URLs but only a fraction indexed, you have a structural problem. Not a one-off anomaly — a systemic symptom worthy of investigation.
How do you interpret this metric concretely?
A discovered-to-indexed ratio close to 1:1 indicates Google considers your content worthy of indexation. A 10:1 ratio or worse signals you're producing or exposing content that Google deliberately ignores or can't process correctly.
- Discovered > Indexed: crawlability issue, content quality, or contradictory indexation directives
- Indexed > Discovered: abnormal configuration, indexed URLs you don't know about (risk of leakage or index pollution)
- Stable ratio over time: good sign, your architecture is working
- Growing gap: you're creating content faster than Google can or wants to index it
SEO Expert opinion
Was this distinction truly new?
Let's be honest: Google always made this distinction internally. What's changed is that Search Console makes it explicit. Before, we hacked around with site: commands, sitemap exports, Apache logs. Now it's displayed in black and white.
But be careful — the fact that Google displays this metric doesn't mean it's new to how it operates. It already existed, just hidden. What's new is the transparency, not the phenomenon itself.
Should you really aim for 100% indexation?
No. And that's where most people get it wrong. Not every discovered URL deserves to be indexed. Product filter facets, internal search result pages, poorly managed pagination URLs — these are all content you might want Google to discover (to follow links) but not index.
The real indicator is the gap between what you want indexed and what actually is. If 5,000 strategic URLs are discovered but only 2,000 are indexed, you have a problem. If 10,000 pagination URLs are discovered and 0 are indexed thanks to your noindex tags, that's perfect. [To verify]: Google provides no clear directive on the acceptable ratio by site type.
Does this metric replace other diagnostics?
No. It's a symptom, not a diagnosis. It tells you there's a problem, but not which one. You need to cross-reference with server logs, coverage reports, canonicals, HTTP status codes, and average crawl time.
Practical impact and recommendations
What should you concretely do with this data?
Start by exporting both lists: discovered URLs vs indexed URLs. Identify pages discovered but missing from the index. Classify them by type (categories, product sheets, editorial content, technical pages). You'll quickly spot where the blockage is.
Next, for each problem segment, ask yourself three questions: does this page have unique, useful content? Is it accessible without blocking JavaScript or redirect chains? Is it properly linked from important pages?
What mistakes must you absolutely avoid?
Don't force indexation of weak content just to improve the ratio. Google won't thank you for it. Don't manually submit thousands of URLs via the inspection tool — it won't fix anything if the problem is structural.
And most importantly, don't confuse crawling and indexation. A URL can be crawled 50 times a day without ever being indexed if Google deems it irrelevant. Increasing crawl frequency doesn't guarantee indexation.
How do you diagnose the source of the blockage?
- Check robots.txt directives: are they blocking entire site sections?
- Inspect meta robots tags: accidental noindex on entire templates?
- Analyze canonicals: do they point to undesired URLs?
- Examine server logs: is Googlebot actually accessing discovered URLs?
- Evaluate content quality: thin content, duplication, auto-generated pages?
- Map your internal linking: are pages reachable in fewer than 3 clicks from home?
- Check XML sitemaps: do they contain URLs you don't want indexed?
- Measure crawl budget: is Google allocating enough resources to your site?
❓ Frequently Asked Questions
Un écart important entre URLs découvertes et indexées signifie-t-il systématiquement un problème ?
Combien de temps faut-il pour que Google indexe une URL découverte ?
Peut-on forcer Google à indexer les URLs découvertes mais ignorées ?
Cette métrique remplace-t-elle la commande site: pour estimer l'indexation ?
Faut-il supprimer les URLs découvertes mais non indexées du sitemap ?
🎥 From the same video 10
Other SEO insights extracted from this same Google Search Central video · published on 29/11/2022
🎥 Watch the full video on YouTube →
💬 Comments (0)
Be the first to comment.