Official statement
Other statements from this video 10 ▾
- □ Les chaînes de redirections bloquent-elles vraiment le crawl de Google sur votre site ?
- □ Pourquoi l'écart entre URLs découvertes et indexées révèle-t-il des problèmes critiques ?
- □ Pourquoi les problèmes d'indexation se concentrent-ils sur certains dossiers de votre site ?
- □ Le no-index libère-t-il vraiment du crawl budget pour les pages importantes ?
- □ Les chaînes de redirections tuent-elles vraiment l'expérience utilisateur ?
- □ Faut-il vraiment supprimer toutes les redirections internes de votre site ?
- □ Pourquoi Google ralentit-il son crawl quand votre serveur faiblit ?
- □ L'instabilité serveur peut-elle vraiment déclasser votre site dans Google ?
- □ Faut-il vraiment multiplier les outils de crawl pour diagnostiquer efficacement vos problèmes SEO ?
- □ Les Developer Tools du navigateur suffisent-ils vraiment pour auditer vos redirections SEO ?
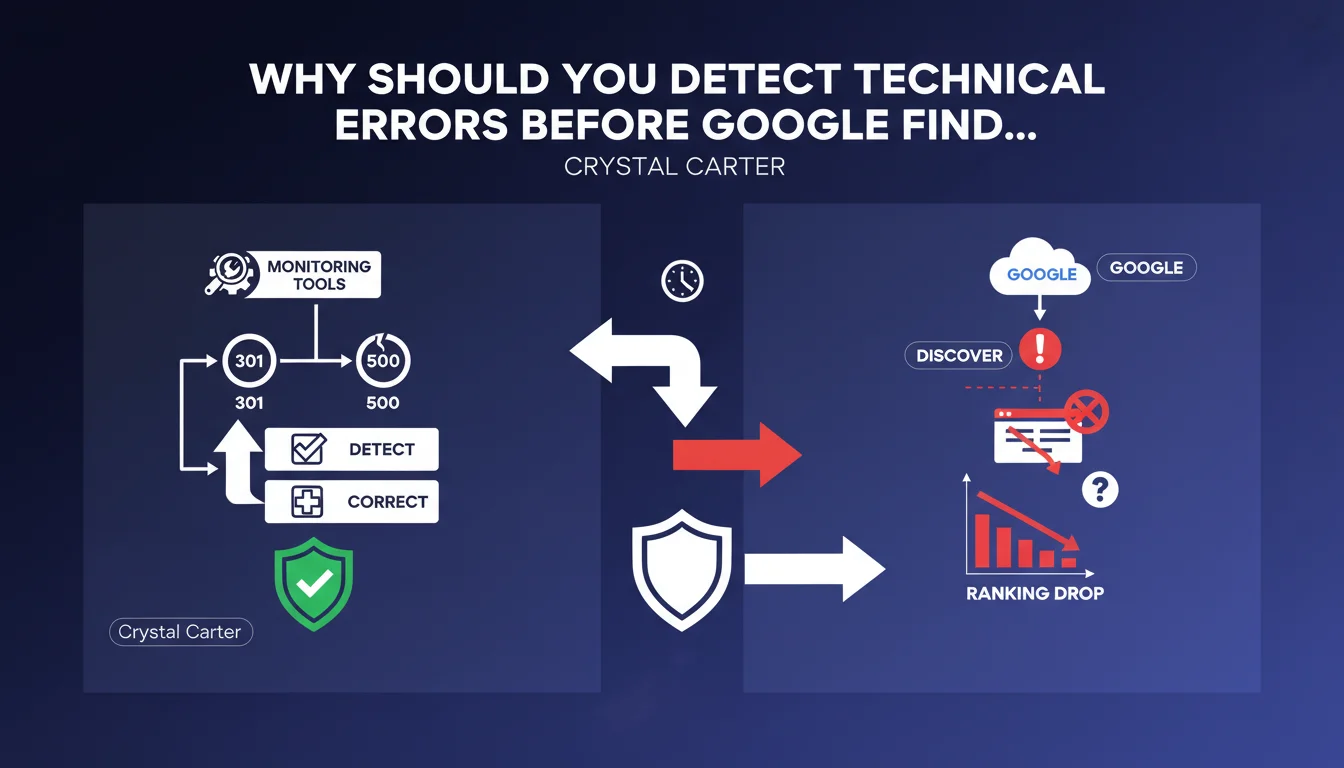
Google recommends using proactive monitoring tools to detect and fix 301 redirects, 500 errors, and other technical issues before Googlebot encounters them. The idea: anticipate problems rather than suffer the consequences of crawler discovery. A clear signal that technical responsiveness is an indirect quality criterion.
What you need to understand
What does "detecting before Google" really mean?
Google suggests that a well-managed site identifies its own malfunctions before Googlebot encounters them during a crawl. In practical terms: if an unexpected 301 appears or an entire section of your site returns 500 errors, it's better to know about it immediately through a monitoring tool rather than discovering it three days later in Google Search Console.
This approach is based on the idea that unresolved technical problems generate negative signals — inaccessible pages, blocked resources, wasted crawl budget. The longer a problem remains undetected, the more it impacts crawlability and potentially ranking.
Why does Google insist on this proactive detection?
Because Googlebot doesn't crawl in real time. It may take hours or even days to revisit a page depending on its crawl frequency. If an error persists between two visits, the bot records a failure — and repeats the operation until it's fixed.
Result: wasted crawl time, risk of temporary deindexing if the error lasts, an implicit signal that the site isn't maintained with rigor. Google values technical reliability — a site that fixes problems before being asked shows that it controls its infrastructure.
What tools enable this upstream monitoring?
Solutions like Uptime Robot, Pingdom, or OnCrawl detect anomalies in near real-time: unusual HTTP codes, degraded response times, redirect chains. Other tools (Screaming Frog in scheduled crawl mode, Botify Analytics) alert on structural variations.
The key: set up automatic alerts on critical KPIs — ratio of 4xx/5xx errors, server response time, unplanned redirects. Don't wait for the weekly Search Console report.
- Proactive monitoring reduces the delay between incident and fix
- Googlebot records every crawl failure — the fewer there are, the better
- Technical responsiveness becomes an indirect signal of site quality
- External tools offer greater granularity and responsiveness than Search Console
SEO Expert opinion
Is this recommendation really new?
No. For years, experienced SEO professionals have used monitoring — nothing revolutionary here. What's interesting is that Google states it publicly: it's an indirect admission that the engine values sites that monitor themselves.
Let's be honest: Google doesn't explicitly say "we penalize sites that let 500 errors linger." But the subtext is clear — a site that detects and fixes its errors quickly sends a signal of professionalism that the engine can interpret as a reliability criterion.
In what cases does this rule not really apply?
On a static site with few updates, proactive monitoring delivers limited value. If you publish three articles per month and your infrastructure is stable, a weekly crawl is more than sufficient. [To verify]: Google never quantifies at what threshold of technical failures a measurable SEO impact becomes apparent.
Another nuance: not all 500 errors are equal. A single timeout at 3 AM on a minor page won't have the same impact as a recurring server error on your category pages. Proactive monitoring helps especially in distinguishing background noise from real problems.
What does this statement reveal about Google's priorities?
It confirms that Google expects mature webmasters — those who manage their infrastructure like a product, not like a personal blog. This aligns with the overall trend: the engine favors players who invest in technical quality, not those who improvise.
But again, Google remains vague about thresholds. How many 500 errors per day does it tolerate? What downtime duration triggers deindexing? No numerical answers — leaving practitioners in the dark.
Practical impact and recommendations
What do you need to implement concretely?
Set up an HTTP monitoring tool that checks your critical pages (homepage, categories, pages with significant SEO traffic) every 5-10 minutes. Configure alerts in case of 4xx/5xx codes, unexpected redirects, or response times > 3 seconds.
Also integrate a scheduled crawl daily or weekly (depending on site size) to detect structural anomalies: orphan pages, redirect chains, blocked resources. The idea: cross-reference real-time monitoring with structural analysis.
Which KPIs should you prioritize?
Focus on recurring server errors (500, 502, 503), unplanned redirects (especially if they affect indexed URLs), and TTFB (Time To First Byte) response times that spike. A TTFB > 1 second on important pages should trigger an alert.
Also monitor crawl rate variations in Google Search Console — a sudden drop may indicate that Googlebot encounters too many errors and is reducing its frequency. It's a late indicator, but useful for correlating with incidents detected by your tools.
How do you avoid false positives?
Define intelligent alert thresholds: a single isolated 500 error doesn't justify an immediate alert. Set rules like "alert if > 3 errors in 10 minutes on the same URL" or "if > 5% of crawled URLs return 4xx."
Exclude test pages, publicly accessible staging environments, and URLs with dynamically generated parameters. Effective monitoring shouldn't drown the team in unnecessary alerts — better to have 10 critical alerts per month than 200 notifications where 90% is noise.
- Install an HTTP monitoring tool with real-time alerts on critical pages
- Configure a scheduled crawl (daily or weekly) to detect structural anomalies
- Monitor 4xx/5xx codes, unexpected redirects, TTFB > 1s
- Set intelligent alert thresholds to avoid false positives
- Cross-reference monitoring data with Search Console reports (crawl rate, crawl errors)
- Document every technical incident and its resolution to identify recurring patterns
❓ Frequently Asked Questions
Quels outils de monitoring sont recommandés pour détecter les erreurs avant Google ?
Combien de temps Google tolère-t-il une erreur 500 avant de désindexer une page ?
Faut-il surveiller toutes les pages d'un site ou seulement les plus importantes ?
Une redirection 301 détectée en amont change-t-elle quelque chose si Google la découvre après ?
Le monitoring proactif a-t-il un impact direct sur le ranking ?
🎥 From the same video 10
Other SEO insights extracted from this same Google Search Central video · published on 29/11/2022
🎥 Watch the full video on YouTube →
💬 Comments (0)
Be the first to comment.