Declaration officielle
Autres déclarations de cette vidéo 10 ▾
- □ Les chaînes de redirections bloquent-elles vraiment le crawl de Google sur votre site ?
- □ Pourquoi les problèmes d'indexation se concentrent-ils sur certains dossiers de votre site ?
- □ Le no-index libère-t-il vraiment du crawl budget pour les pages importantes ?
- □ Les chaînes de redirections tuent-elles vraiment l'expérience utilisateur ?
- □ Faut-il vraiment supprimer toutes les redirections internes de votre site ?
- □ Pourquoi Google ralentit-il son crawl quand votre serveur faiblit ?
- □ L'instabilité serveur peut-elle vraiment déclasser votre site dans Google ?
- □ Faut-il vraiment multiplier les outils de crawl pour diagnostiquer efficacement vos problèmes SEO ?
- □ Pourquoi faut-il détecter les erreurs techniques avant que Google ne les trouve ?
- □ Les Developer Tools du navigateur suffisent-ils vraiment pour auditer vos redirections SEO ?
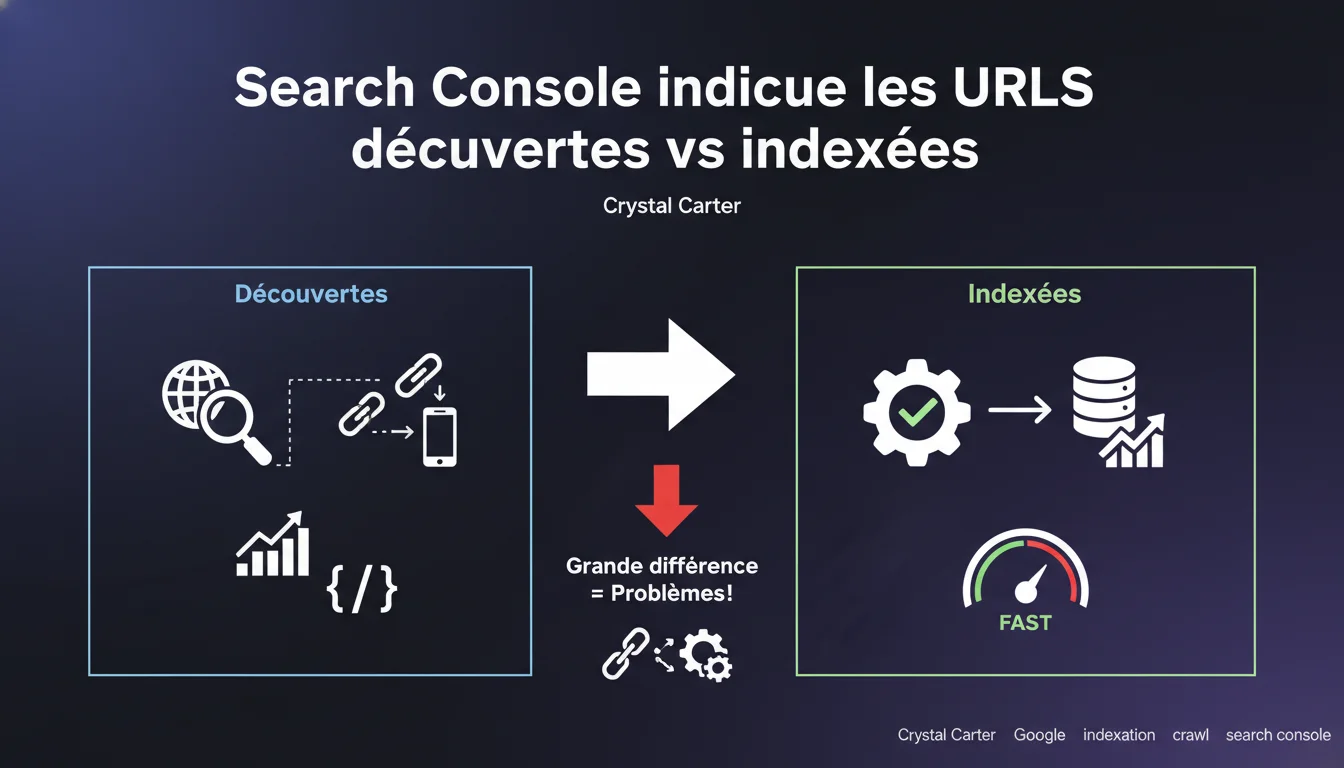
Google Search Console distingue désormais clairement les URLs découvertes de celles effectivement indexées. Un écart important entre ces deux métriques signale des problèmes structurels de crawlabilité ou d'indexation qui bloquent votre visibilité. C'est un indicateur à surveiller systématiquement pour diagnostiquer ce qui empêche vos contenus d'atteindre l'index.
Ce qu'il faut comprendre
Quelle différence entre découverte et indexation dans Search Console ?
Google découvre une URL quand son crawler la détecte — via un sitemap, un lien interne, un backlink externe. Mais découvrir ne signifie pas indexer. L'indexation intervient après le crawl, quand Google décide de stocker la page dans son index et de la rendre éligible au classement.
Search Console expose maintenant ces deux états séparément. Vous voyez combien d'URLs Google connaît, et combien il a réellement indexées. L'écart entre les deux, c'est votre angle mort.
Pourquoi cet écart devrait-il vous inquiéter ?
Une URL découverte mais non indexée, c'est un contenu invisible. Peu importe sa qualité, il ne génère aucun trafic organique. Les causes possibles : budget de crawl insuffisant, balises noindex accidentelles, contenus dupliqués, canonicales mal configurées, pages orphelines sans maillage, ou simplement du contenu jugé non pertinent par Google.
Si vous constatez des milliers d'URLs découvertes mais seulement une fraction indexée, vous avez un problème structurel. Pas une anomalie ponctuelle — un symptôme systémique qui mérite investigation.
Comment interpréter cette métrique concrètement ?
Un ratio découvert/indexé proche de 1:1 indique que Google juge vos contenus dignes d'indexation. Un ratio de 10:1 ou pire signale que vous produisez ou exposez du contenu que Google ignore volontairement ou ne peut pas traiter correctement.
- Découvert > Indexé : problème de crawlabilité, qualité du contenu, ou directives d'indexation contradictoires
- Indexé > Découvert : configuration anormale, URLs indexées que vous ne connaissez pas (risque de fuite ou pollution d'index)
- Ratio stable dans le temps : bon signe, votre architecture fonctionne
- Écart croissant : vous créez du contenu plus vite que Google ne peut ou ne veut l'indexer
Avis d'un expert SEO
Cette distinction était-elle vraiment nouvelle ?
Soyons honnêtes : Google a toujours fait cette différence en interne. Ce qui change, c'est que Search Console la rend explicite. Avant, on bricolait avec des commandes site:, des exports de sitemaps, des logs Apache. Maintenant, c'est affiché noir sur blanc.
Mais attention — le fait que Google affiche cette métrique ne signifie pas qu'elle soit nouvelle dans son fonctionnement. Elle existait déjà, simplement opaque. Ce qui est nouveau, c'est la transparence, pas le phénomène.
Faut-il vraiment viser 100% d'indexation ?
Non. Et c'est là que beaucoup se plantent. Tous les contenus découverts ne méritent pas d'être indexés. Des facettes de filtres produits, des pages de résultats de recherche interne, des URLs de pagination mal gérées — autant de contenus que vous voulez peut-être que Google découvre (pour suivre les liens) mais pas qu'il indexe.
Le vrai indicateur, c'est l'écart entre ce que vous voulez indexer et ce qui l'est effectivement. Si 5000 URLs stratégiques sont découvertes mais seulement 2000 indexées, vous avez un problème. Si 10000 URLs de pagination sont découvertes et 0 indexées grâce à vos balises noindex, c'est parfait. [A vérifier] : Google ne donne aucune directive précise sur le ratio acceptable par typologie de site.
Cette métrique remplace-t-elle les autres diagnostics ?
Non. C'est un symptôme, pas un diagnostic. Elle vous dit qu'il y a un problème, mais pas lequel. Vous devez croiser avec les logs serveur, les rapports de couverture, les canoniques, les statuts HTTP, le temps de crawl moyen.
Impact pratique et recommandations
Que faut-il faire concrètement avec cette donnée ?
Commencez par exporter les deux listes : URLs découvertes vs URLs indexées. Identifiez les pages découvertes mais absentes de l'index. Classez-les par typologie (catégories, fiches produits, contenus éditoriaux, pages techniques). Vous verrez vite où se situe le blocage.
Ensuite, pour chaque segment problématique, posez-vous trois questions : cette page a-t-elle du contenu unique et utile ? Est-elle accessible sans JavaScript bloquant ou redirections en chaîne ? Est-elle correctement maillée depuis des pages importantes ?
Quelles erreurs éviter absolument ?
Ne forcez pas l'indexation de contenus faibles juste pour améliorer le ratio. Google ne vous en remerciera pas. Ne soumettez pas manuellement des milliers d'URLs via l'outil d'inspection — ça ne résout rien si le problème est structurel.
Et surtout, ne confondez pas crawl et indexation. Une URL peut être crawlée 50 fois par jour sans jamais être indexée si Google la juge non pertinente. Augmenter la fréquence de crawl ne garantit pas l'indexation.
Comment diagnostiquer l'origine du blocage ?
- Vérifier les directives robots.txt : bloquent-elles des sections entières du site ?
- Inspecter les balises meta robots : noindex accidentel sur des templates entiers ?
- Analyser les canoniques : pointent-elles vers des URLs non désirées ?
- Examiner les logs serveur : Googlebot accède-t-il réellement aux URLs découvertes ?
- Évaluer la qualité du contenu : thin content, duplication, pages auto-générées ?
- Cartographier le maillage interne : les pages sont-elles atteignables en moins de 3 clics depuis la home ?
- Contrôler les sitemaps XML : contiennent-ils des URLs que vous ne voulez pas indexer ?
- Mesurer le budget de crawl : Google alloue-t-il suffisamment de ressources à votre site ?
❓ Questions frequentes
Un écart important entre URLs découvertes et indexées signifie-t-il systématiquement un problème ?
Combien de temps faut-il pour que Google indexe une URL découverte ?
Peut-on forcer Google à indexer les URLs découvertes mais ignorées ?
Cette métrique remplace-t-elle la commande site: pour estimer l'indexation ?
Faut-il supprimer les URLs découvertes mais non indexées du sitemap ?
🎥 De la même vidéo 10
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 29/11/2022
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.