Declaration officielle
Autres déclarations de cette vidéo 10 ▾
- □ Les chaînes de redirections bloquent-elles vraiment le crawl de Google sur votre site ?
- □ Pourquoi l'écart entre URLs découvertes et indexées révèle-t-il des problèmes critiques ?
- □ Pourquoi les problèmes d'indexation se concentrent-ils sur certains dossiers de votre site ?
- □ Les chaînes de redirections tuent-elles vraiment l'expérience utilisateur ?
- □ Faut-il vraiment supprimer toutes les redirections internes de votre site ?
- □ Pourquoi Google ralentit-il son crawl quand votre serveur faiblit ?
- □ L'instabilité serveur peut-elle vraiment déclasser votre site dans Google ?
- □ Faut-il vraiment multiplier les outils de crawl pour diagnostiquer efficacement vos problèmes SEO ?
- □ Pourquoi faut-il détecter les erreurs techniques avant que Google ne les trouve ?
- □ Les Developer Tools du navigateur suffisent-ils vraiment pour auditer vos redirections SEO ?
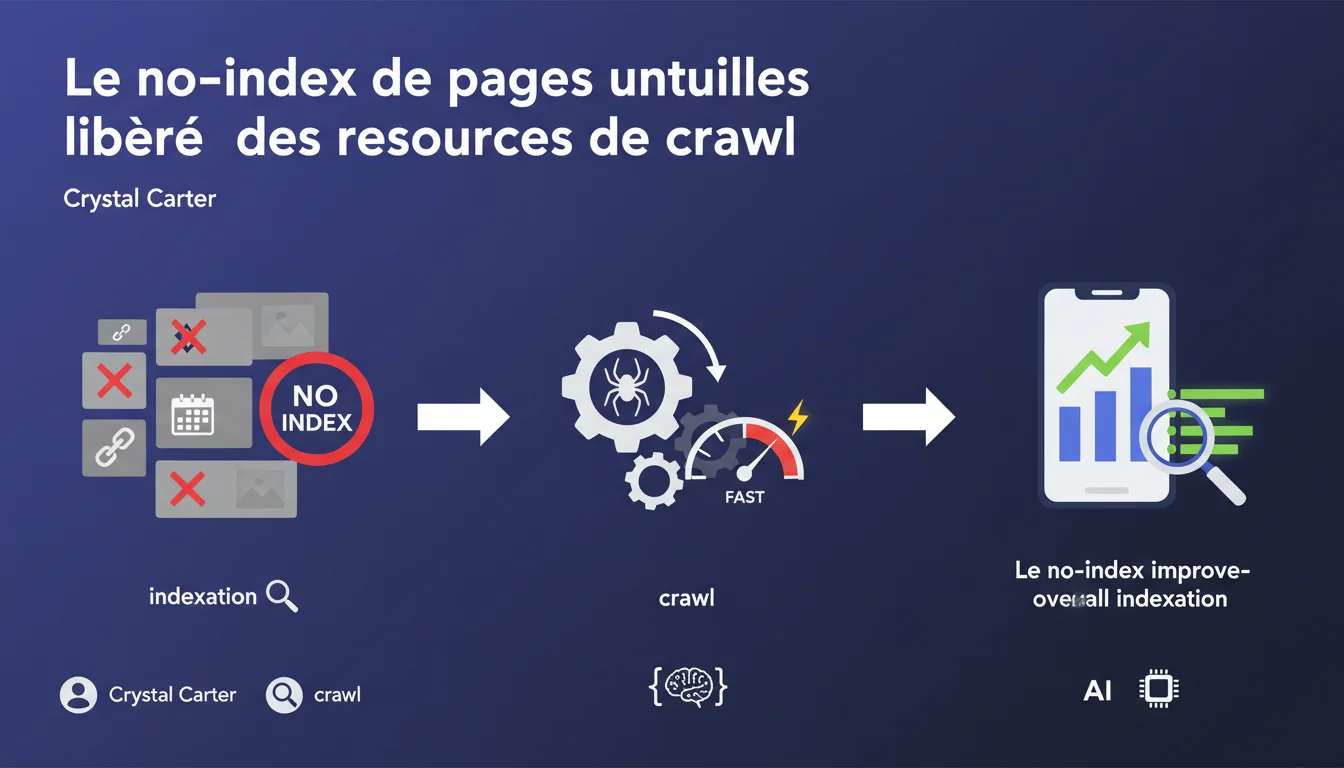
Google confirme qu'ajouter des balises no-index sur les pages non stratégiques libère des ressources de crawl pour le reste du site. Concrètement : moins de pages inutiles indexées = plus de temps bot alloué aux URLs qui comptent. Une déclaration qui valide une pratique terrain déjà bien ancrée.
Ce qu'il faut comprendre
Pourquoi Google insiste sur cette histoire de ressources de crawl ?
Googlebot dispose d'un temps limité par site. Si votre serveur se fait marquer des milliers d'URLs sans valeur (filtres à facettes, paramètres de session, pages de tags vides), le bot perd du temps à les explorer et à les réévaluer. Résultat : vos pages stratégiques attendent plus longtemps avant d'être crawlées à nouveau.
Le no-index signale à Google : « Cette page peut rester en crawl, mais inutile de l'inclure dans l'index. » Le bot passe moins de cycles à traiter ces URLs, théoriquement. Libérer ces ressources permet au crawl de se concentrer sur les contenus à forte valeur ajoutée — ceux qui génèrent du trafic organique.
Quels types de pages devraient porter un no-index ?
Les candidats classiques : pages de remerciement après formulaire, pages de résultats de recherche interne, archives de tags sans contenu, paramètres UTM, versions paginées dupliquées, pages de connexion/compte utilisateur. Tout ce qui n'apporte rien à un visiteur externe et pollue l'index.
Attention — on ne parle pas ici de bloquer le crawl via robots.txt, ce qui empêcherait Google de voir la balise no-index. L'idée est de laisser Googlebot accéder à la page, lire le no-index, et passer son chemin sans gaspiller de budget sur le traitement indexation.
Cette directive améliore-t-elle réellement l'indexation globale ?
Oui, mais sous certaines conditions. Si votre site compte 500 pages et que vous en no-indexez 50 peu pertinentes, l'impact peut être nul. En revanche, sur un gros site e-commerce avec 100 000 URLs dont 30% de pages parasites, le gain devient mesurable : réduction du temps moyen de recrawl, meilleure fraîcheur des contenus stratégiques.
- No-index ≠ blocage crawl : la page reste accessible, mais sort de l'index
- Applicable principalement sur les gros sites où le crawl budget est un facteur limitant
- Permet de concentrer les ressources bot sur les pages génératrices de trafic
- Évite la dilution de signal dans l'index avec du contenu sans valeur
Avis d'un expert SEO
Cette déclaration est-elle cohérente avec ce qu'on observe sur le terrain ?
Totalement. Les audits techniques montrent régulièrement des sites où 40 à 60% des pages indexées ne génèrent aucun trafic organique. Dès qu'on nettoie l'index via no-index + suppression progressive, on voit souvent un recrawl plus fréquent des URLs stratégiques — surtout sur les sites lourds en pagination ou en facettes.
Maintenant, soyons honnêtes : Crystal Carter ne précise pas le seuil de pages à partir duquel l'amélioration devient significative. Pour un blog de 200 articles, l'effet sera marginal. Pour un marketplace avec 500 000 fiches produits dont 200 000 obsolètes, c'est une autre histoire. [À vérifier] sur chaque site via log analysis.
Quelles nuances faut-il apporter à cette recommandation ?
Le no-index n'est pas un passe-partout. Si vous no-indexez une catégorie intermédiaire qui sert de hub de maillage interne, vous cassez le flux de PageRank et la cohérence sémantique. Résultat : les pages filles peuvent perdre en visibilité, même si elles restent indexées.
Autre piège classique : appliquer le no-index sur des pages qui reçoivent déjà des backlinks. Google continuera de crawler ces URLs (puisqu'elles sont liées depuis l'externe), mais vous perdez leur contribution au ranking. Avant de no-indexer, vérifiez la distribution de liens entrants — un export Ahrefs ou Majestic suffit.
Dans quels cas cette règle ne s'applique-t-elle pas ?
Sur les petits sites (moins de 1 000 pages), le crawl budget n'est pratiquement jamais un facteur limitant. Google a largement la bande passante pour tout crawler plusieurs fois par jour. Ajouter du no-index partout ne changera rien à la fréquence de recrawl — et risque même de créer des erreurs d'implémentation si le CMS n'est pas bien configuré.
Idem sur les sites neufs sans historique : Googlebot explore généralement toutes les URLs découvertes sans friction. Le vrai intérêt du no-index pour libérer du crawl, c'est sur les sites matures avec un index gonflé par des années d'URL creep.
Impact pratique et recommandations
Que faut-il faire concrètement pour libérer ce crawl budget ?
Première étape : identifier les pages indexées à faible valeur. Extrayez votre index via Google Search Console (rapport Couverture) ou un crawl Screaming Frog. Croisez avec vos données Analytics pour repérer les URLs indexées qui génèrent zéro session organique sur 12 mois.
Ensuite, segmentez par type : pages de tags sans contenu, archives vides, URLs avec paramètres de session, facettes produit à faible volume de recherche. Pour chaque segment, ajoutez <meta name="robots" content="noindex, follow"> en <head>. Le follow reste essentiel pour ne pas casser le maillage interne.
Vérifiez ensuite dans les logs serveur que Googlebot continue bien de crawler ces pages — mais qu'il ne les réindexe plus. Surveillez l'évolution de l'index total dans Search Console : une baisse progressive confirme que Google respecte la directive.
Quelles erreurs éviter lors de l'implémentation ?
Ne no-indexez jamais une page par accident en production — un CMS mal configuré peut propager la balise à toute une section stratégique. Testez d'abord sur un échantillon réduit (10-20 URLs), attendez 2-3 semaines, et mesurez l'impact avant de scaler.
Évitez aussi de no-indexer des pages avec du contenu unique de qualité simplement parce qu'elles génèrent peu de trafic aujourd'hui. Parfois, une page dort dans l'index pendant des mois avant qu'une requête longue traîne ne la fasse émerger. Analysez le potentiel sémantique, pas seulement l'historique Analytics.
Dernier piège : ne combinez jamais no-index et canonical vers une autre URL. Google suivra la canonical et ignorera le no-index, créant un signal contradictoire. Si une page doit disparaître de l'index, no-index seul. Si elle est dupliquée, canonical seule.
Comment vérifier que la stratégie fonctionne ?
- Exportez l'index Search Console avant intervention (baseline)
- Appliquez le no-index sur un segment test (ex : tags vides)
- Attendez 3-4 semaines et ré-exportez l'index pour constater la baisse
- Analysez les logs serveur : le taux de recrawl des pages stratégiques augmente-t-il ?
- Surveillez le temps moyen de découverte de nouveaux contenus (Search Console)
- Croisez avec l'évolution du trafic organique sur les pages prioritaires
❓ Questions frequentes
Faut-il utiliser no-index ou robots.txt pour exclure des pages de l'index ?
Le no-index réduit-il le PageRank transmis aux pages liées ?
Combien de temps faut-il pour que Google retire une page no-indexée de l'index ?
Peut-on no-indexer une page tout en la gardant dans le sitemap XML ?
Le no-index améliore-t-il le crawl budget sur un petit site de 300 pages ?
🎥 De la même vidéo 10
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 29/11/2022
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.