Declaration officielle
Autres déclarations de cette vidéo 10 ▾
- □ Les chaînes de redirections bloquent-elles vraiment le crawl de Google sur votre site ?
- □ Pourquoi l'écart entre URLs découvertes et indexées révèle-t-il des problèmes critiques ?
- □ Pourquoi les problèmes d'indexation se concentrent-ils sur certains dossiers de votre site ?
- □ Le no-index libère-t-il vraiment du crawl budget pour les pages importantes ?
- □ Les chaînes de redirections tuent-elles vraiment l'expérience utilisateur ?
- □ Faut-il vraiment supprimer toutes les redirections internes de votre site ?
- □ L'instabilité serveur peut-elle vraiment déclasser votre site dans Google ?
- □ Faut-il vraiment multiplier les outils de crawl pour diagnostiquer efficacement vos problèmes SEO ?
- □ Pourquoi faut-il détecter les erreurs techniques avant que Google ne les trouve ?
- □ Les Developer Tools du navigateur suffisent-ils vraiment pour auditer vos redirections SEO ?
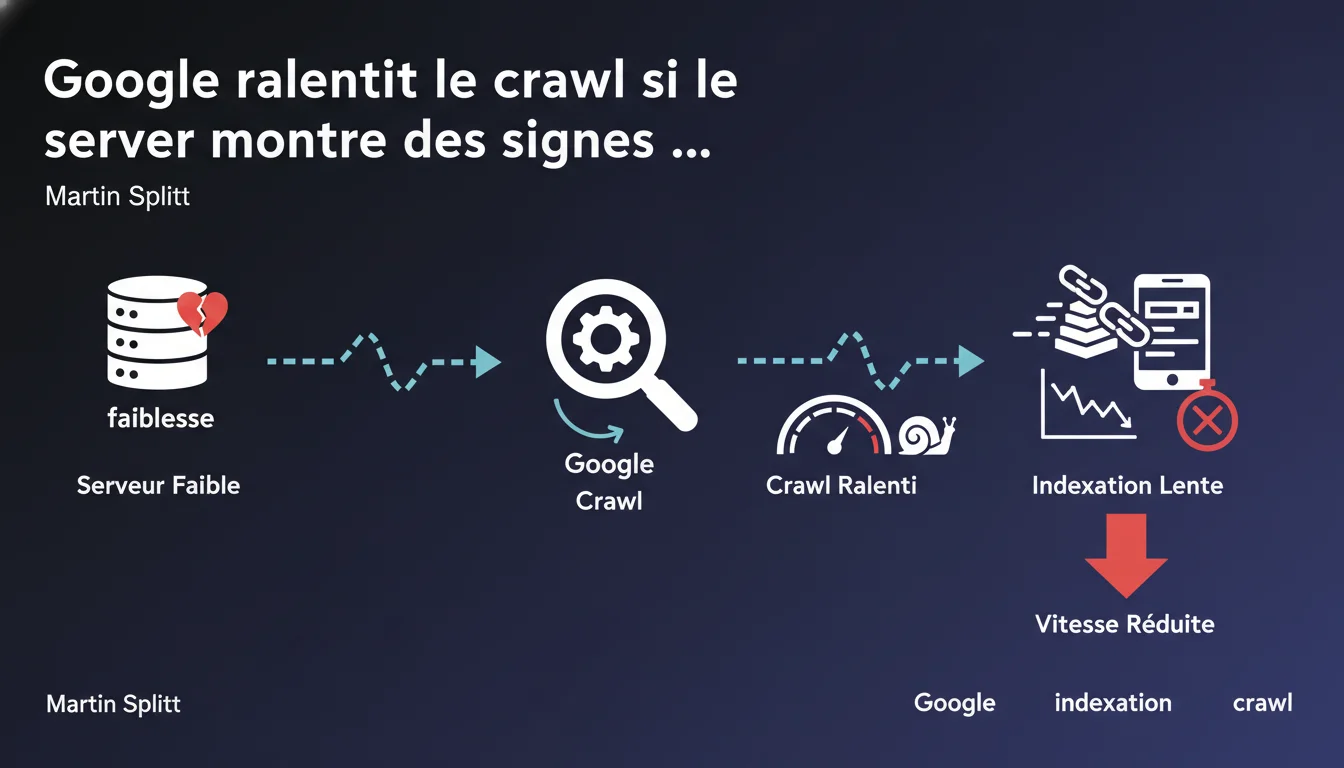
Google ajuste automatiquement sa vitesse de crawl à la baisse dès qu'il détecte des signes de faiblesse côté serveur — pour éviter d'aggraver la situation et de pénaliser vos visiteurs réels. Conséquence directe : votre indexation ralentit, parfois drastiquement, tant que le problème persiste.
Ce qu'il faut comprendre
Qu'est-ce que ce mécanisme de protection révèle sur la logique du Googlebot ?
Le crawl de Google n'est pas un processus uniforme. Le bot ajuste en permanence son rythme d'exploration en fonction de la capacité du serveur à absorber la charge.
Concrètement, Googlebot surveille les temps de réponse, les erreurs 5xx et d'autres signaux de stress — et recule si votre infrastructure montre des signes de saturation. L'objectif : ne pas transformer une situation tendue en catastrophe complète.
Quels signaux déclenchent ce ralentissement ?
Les erreurs 503 (Service Unavailable) et les timeouts fréquents sont les déclencheurs classiques. Mais une dégradation progressive des temps de réponse suffit parfois.
Google ne publie pas de seuils précis — chaque site est évalué dans son propre contexte. Ce qui compte : la régularité du signal. Un pic isolé ne déclenche rien ; une tendance lourde, oui.
Pourquoi c'est un problème pour l'indexation ?
Si Googlebot ralentit, il explore moins de pages par jour. Les nouvelles URLs mettent plus de temps à être découvertes, les pages mises à jour restent obsolètes dans l'index plus longtemps.
Pour un site e-commerce avec rotation rapide de produits, ou un média qui publie plusieurs fois par jour, l'impact peut être sévère. Le contenu frais arrive en retard — ou n'arrive jamais.
- Google protège votre serveur en ralentissant automatiquement son crawl
- Les signaux de stress (erreurs 5xx, timeouts) déclenchent cet ajustement
- Conséquence : vitesse d'indexation réduite, contenu découvert avec retard
- Le problème se résout quand les performances serveur reviennent à la normale
Avis d'un expert SEO
Cette logique est-elle cohérente avec ce qu'on observe sur le terrain ?
Absolument. Les cas de crawl budget throttling suite à des incidents serveur sont documentés depuis des années. Ce n'est pas une nouveauté, mais une confirmation officielle de ce qui était déjà observable.
Ce qui est intéressant ici : Martin Splitt explicite le raisonnement. Google ne cherche pas à punir — il cherche à éviter d'aggraver une situation fragile. C'est une forme d'auto-régulation du système.
Quelles nuances faut-il apporter à cette déclaration ?
Premier point : tous les sites ne sont pas égaux face au crawl budget. Un petit blog avec 200 pages ne verra jamais le problème, même avec un serveur à genoux. Un site avec 500 000 URLs, oui — et rapidement.
Deuxième nuance — et c'est là que ça coince. La déclaration ne précise pas combien de temps dure le ralentissement après résolution du problème. Est-ce quelques heures ? Quelques jours ? [A vérifier] sur des cas réels, parce que Google reste vague sur ce timing.
Enfin, attention : certains signaux peuvent être mal interprétés. Un CDN mal configuré peut générer des erreurs intermittentes sans que le serveur d'origine soit réellement en difficulté. Googlebot réagit à ce qu'il voit — pas forcément à la réalité infrastructure.
Dans quels cas cette protection peut-elle devenir contre-productive ?
Quand un site subit une attaque DDoS ou un pic de trafic légitime mais inhabituel, les mécanismes de défense (rate limiting, WAF) peuvent bloquer ou ralentir Googlebot par erreur. Le bot interprète ça comme un stress serveur — et ralentit encore plus.
Résultat : double peine. Vous gérez une crise de trafic, et en prime votre indexation se fige. C'est rare, mais ça arrive — et c'est pénible à débugger en temps réel.
Impact pratique et recommandations
Que faut-il surveiller pour détecter ce ralentissement ?
Première action : Google Search Console, onglet Statistiques d'exploration. Si vous voyez une chute nette du nombre de requêtes par jour, sans changement éditorial de votre côté, c'est le signal d'alarme.
Croisez avec vos logs serveur : cherchez les erreurs 5xx, les timeouts, les pics de latence inhabituels. Si les deux courbes bougent en même temps, vous avez confirmation.
Comment corriger le problème rapidement ?
Identifiez la source du stress. Souvent, c'est un plugin mal codé, une requête SQL qui explose, un cache qui ne fait plus son job. Parfois, c'est juste que votre hébergement est sous-dimensionné face à la croissance du trafic.
Une fois le problème résolu côté serveur, Googlebot reprend son rythme normal — mais pas instantanément. Il faut lui laisser le temps de constater la stabilité retrouvée. Patience : quelques jours peuvent être nécessaires.
Si vous êtes pressé, vous pouvez forcer le crawl de quelques URLs stratégiques via l'outil d'inspection d'URL dans la Search Console. Mais ça ne remplace pas un retour à la normale global.
Quelles erreurs éviter absolument ?
Ne bloquez jamais Googlebot dans votre robots.txt ou via rate limiting pour "économiser" des ressources. C'est contre-productif : Google interprète ça comme un signal de faiblesse et ralentit encore plus.
Évitez aussi de sur-solliciter l'API Indexing de Google pour compenser. Elle est réservée aux contenus très volatils (offres d'emploi, livestreams). L'utiliser massivement pour forcer l'indexation post-incident peut vous valoir une suspension d'accès.
- Monitorer quotidiennement les Statistiques d'exploration dans la Search Console
- Corréler les baisses de crawl avec les erreurs serveur (logs Apache/Nginx, monitoring APM)
- Dimensionner l'hébergement en fonction du trafic réel + marge pour absorber Googlebot
- Configurer des alertes automatiques sur les erreurs 5xx et les timeouts
- Tester la résilience de l'infrastructure avec des outils de stress testing avant migration ou refonte
- Ne jamais bloquer Googlebot pour économiser des ressources — c'est l'effet inverse garanti
❓ Questions frequentes
Combien de temps dure le ralentissement du crawl après résolution du problème serveur ?
Est-ce que tous les sites sont concernés par ce mécanisme de protection ?
Un CDN peut-il empêcher Google de détecter les faiblesses du serveur d'origine ?
Peut-on forcer Google à reprendre un crawl normal après incident ?
Les erreurs 503 temporaires pendant une maintenance déclenchent-elles ce ralentissement ?
🎥 De la même vidéo 10
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 29/11/2022
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.