Declaration officielle
Autres déclarations de cette vidéo 9 ▾
- □ Comment Google crawle-t-il vraiment vos pages web ?
- □ Comment Google découvre-t-il vraiment vos nouvelles pages ?
- □ Comment Googlebot décide-t-il quelles pages crawler sur votre site ?
- □ Googlebot ralentit-il volontairement sur votre site pour ne pas le surcharger ?
- □ Pourquoi Googlebot ignore-t-il une partie des URLs qu'il découvre ?
- □ Googlebot peut-il vraiment crawler le contenu derrière une page de connexion ?
- □ Pourquoi Google ne voit-il pas votre contenu JavaScript sans rendering ?
- □ Faut-il vraiment un sitemap XML pour être indexé par Google ?
- □ Faut-il vraiment automatiser la génération de vos sitemaps ?
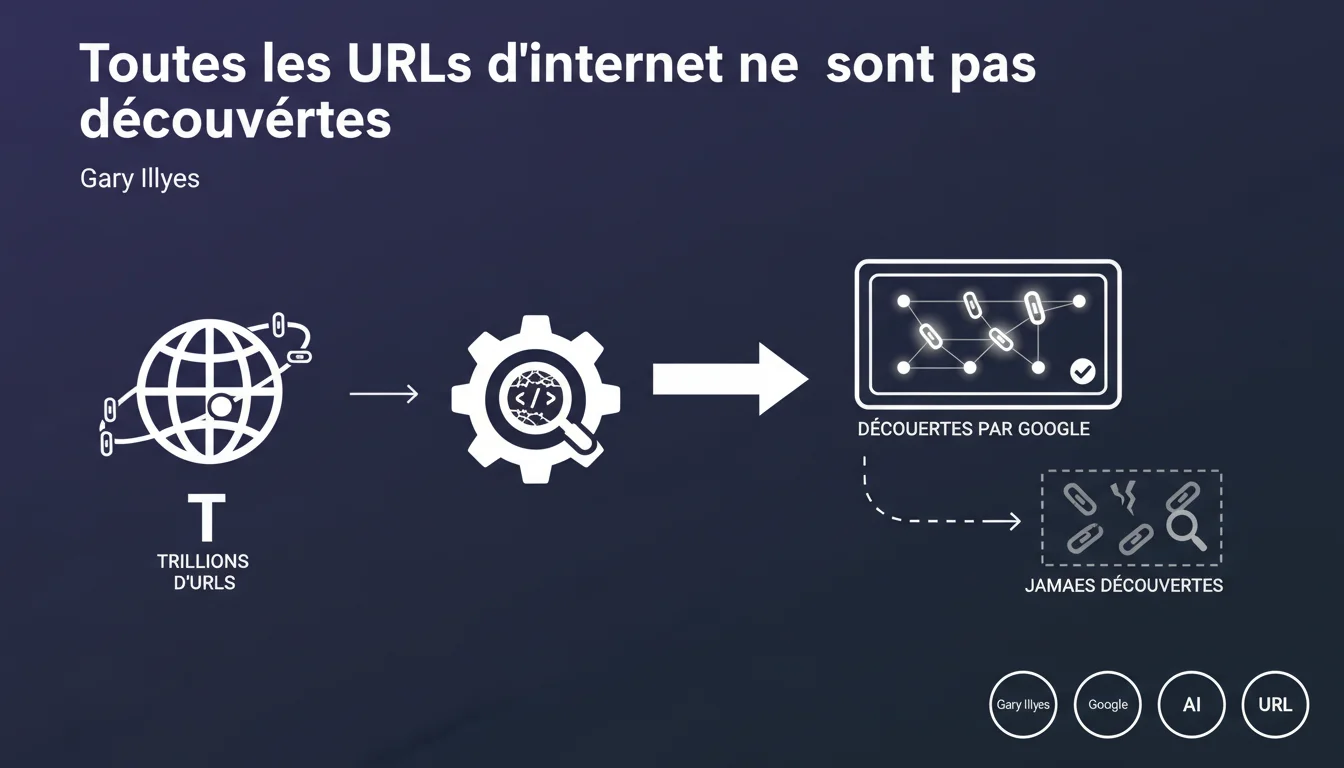
Google affirme que certaines pages ne seront jamais découvertes parmi les trillions d'URLs sur internet. Cette déclaration rappelle que l'indexation n'est pas automatique et que les sites doivent activement faciliter la découverte de leurs contenus. Le crawl budget et la structure technique restent des enjeux critiques.
Ce qu'il faut comprendre
Que signifie vraiment cette déclaration de Google ?
Gary Illyes rappelle une réalité souvent sous-estimée : Google ne crawle pas l'intégralité du web. Avec des trillions d'URLs en ligne, le moteur opère des choix. Certaines pages ne seront jamais visitées, d'autres découvertes avec des mois de retard.
Cette affirmation n'est pas nouvelle, mais elle mérite d'être prise au sérieux. Les sites qui comptent sur la découverte passive via le crawl naturel prennent un risque — surtout ceux qui génèrent massivement du contenu ou qui souffrent de problèmes techniques.
Pourquoi certaines URLs ne sont-elles jamais découvertes ?
Plusieurs facteurs limitent la découverte : absence de liens entrants, profondeur excessive dans l'arborescence, fichiers robots.txt mal configurés, pages orphelines sans maillage interne. Google ne devine pas l'existence d'une page si aucun signal ne la rend visible.
Le crawl budget joue aussi un rôle central. Les sites avec des milliers de pages mais peu d'autorité ou des temps de réponse médiocres voient leur budget alloué se réduire drastiquement. Résultat : des pans entiers du site restent dans l'ombre.
Quelles sont les conséquences directes pour un site ?
Une page non découverte ne sera jamais indexée. Pas d'indexation, pas de classement possible. C'est aussi simple que cela. Les contenus stratégiques — fiches produits, articles de fond, pages de conversion — peuvent se retrouver invisibles si rien n'est fait pour les signaler à Google.
- Crawl budget limité : Google alloue un temps de crawl fini par site, proportionnel à son autorité et sa santé technique.
- Profondeur d'arborescence : Plus une page est enfouie, moins elle a de chances d'être crawlée rapidement.
- Absence de liens : Aucun lien interne ou externe vers une page = aucune découverte naturelle.
- Signaux techniques négatifs : Temps de réponse élevés, erreurs 5xx récurrentes, redirections en chaîne nuisent à la découverte.
- Pages orphelines : Contenus créés mais jamais reliés au reste du site.
Avis d'un expert SEO
Cette déclaration est-elle cohérente avec ce qu'on observe sur le terrain ?
Absolument. On constate régulièrement que des sites avec des milliers de pages n'ont qu'une fraction de leurs URLs indexées. Google Search Console le confirme : certains sites voient 30 à 40 % de leurs pages « découvertes mais non explorées » ou « explorées mais non indexées ».
Le problème se pose surtout pour les sites e-commerce avec filtres à facettes, les forums, les sites d'annonces ou les agrégateurs de contenu. Ces plateformes génèrent des URLs à la chaîne — et Google n'a ni le temps ni l'intérêt de toutes les visiter.
Que faut-il nuancer dans cette affirmation ?
Gary Illyes parle de « trillions d'URLs », mais il ne précise pas la proportion de pages réellement utiles ou de qualité dans ce volume. [À vérifier] : combien de ces URLs non découvertes sont du spam, des duplicatas techniques ou des contenus sans valeur ajoutée ?
Soyons honnêtes — une part non négligeable des pages non crawlées mérite probablement de rester dans l'oubli. Le vrai enjeu, c'est de s'assurer que vos pages stratégiques ne font pas partie de ce lot. Et là, les données manquent. Google ne fournit aucun seuil, aucune métrique claire pour évaluer si votre site est concerné de manière problématique.
Quand cette règle ne s'applique-t-elle pas ?
Si votre site est petit (quelques centaines de pages), bien structuré, avec des sitemaps XML propres et un maillage interne cohérent, vous n'avez probablement rien à craindre. Google découvrira l'essentiel sans difficulté.
En revanche, dès que vous franchissez le cap des milliers d'URLs — avec du contenu généré automatiquement, des filtres de recherche infinis ou des archives de forum — la situation change radicalement. Là, la déclaration de Gary Illyes devient un avertissement direct.
Impact pratique et recommandations
Que faut-il faire concrètement pour maximiser la découverte de vos pages ?
Soumettez vos sitemaps XML via Google Search Console. C'est le moyen le plus direct de signaler vos URLs importantes. Veillez à ce que ces sitemaps soient à jour, sans erreurs 404 ni redirections, et qu'ils ne contiennent que les pages que vous souhaitez réellement indexer.
Optimisez votre maillage interne. Chaque page stratégique doit être accessible en 3 clics maximum depuis la page d'accueil. Utilisez des ancres descriptives et variez les chemins de navigation pour multiplier les opportunités de découverte.
Travaillez votre crawl budget. Éliminez les URLs inutiles (paramètres de tri, filtres redondants, sessions utilisateur), corrigez les erreurs serveur, réduisez les temps de réponse. Chaque milliseconde gagnée permet à Google de crawler davantage de pages utiles.
Quelles erreurs éviter absolument ?
Ne bloquez pas par erreur des sections entières de votre site via robots.txt ou balises noindex. Vérifiez régulièrement vos règles d'exploration dans Google Search Console et testez-les sur des URLs critiques.
Évitez les pages orphelines. Si une page n'est reliée à rien, Google ne la trouvera probablement jamais. Faites un audit régulier pour identifier ces contenus isolés et les rattacher à votre arborescence.
Ne comptez pas uniquement sur les sitemaps. Ils aident, mais Google privilégie la découverte via les liens. Un contenu sans aucun lien interne ou externe restera probablement invisible, même s'il figure dans un sitemap.
Comment vérifier que votre site est correctement découvert ?
Consultez le rapport de couverture d'index dans Google Search Console. Identifiez les pages « découvertes mais non explorées » et demandez-vous pourquoi : crawl budget insuffisant ? Pages trop profondes ? Problèmes techniques ?
Utilisez un crawler SEO (Screaming Frog, Oncrawl, Botify) pour simuler le comportement de Googlebot. Comparez les URLs découvertes par votre outil et celles indexées par Google. L'écart vous donnera une idée des zones à problème.
- Soumettre et maintenir à jour les sitemaps XML dans Google Search Console
- Vérifier que toutes les pages stratégiques sont accessibles en 3 clics maximum depuis la page d'accueil
- Éliminer les URLs inutiles qui dilapident le crawl budget (filtres, sessions, duplicatas)
- Corriger les erreurs serveur (5xx) et optimiser les temps de réponse
- Auditer régulièrement les pages orphelines et les rattacher au maillage interne
- Analyser le rapport de couverture dans Google Search Console pour identifier les blocages
- Utiliser un crawler SEO pour simuler le comportement de Googlebot et détecter les écarts
- Obtenir des backlinks vers les pages importantes pour faciliter leur découverte naturelle
❓ Questions frequentes
Combien de pages Google peut-il découvrir sur mon site ?
Les sitemaps XML garantissent-ils la découverte de toutes mes pages ?
Pourquoi certaines de mes pages sont « découvertes mais non explorées » ?
Faut-il bloquer les URLs inutiles dans robots.txt ou via noindex ?
Combien de temps faut-il à Google pour découvrir une nouvelle page ?
🎥 De la même vidéo 9
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 22/02/2024
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.