Declaration officielle
Autres déclarations de cette vidéo 9 ▾
- □ Comment Google crawle-t-il vraiment vos pages web ?
- □ Pourquoi Google ne découvre-t-il pas toutes les URLs de votre site ?
- □ Comment Googlebot décide-t-il quelles pages crawler sur votre site ?
- □ Googlebot ralentit-il volontairement sur votre site pour ne pas le surcharger ?
- □ Pourquoi Googlebot ignore-t-il une partie des URLs qu'il découvre ?
- □ Googlebot peut-il vraiment crawler le contenu derrière une page de connexion ?
- □ Pourquoi Google ne voit-il pas votre contenu JavaScript sans rendering ?
- □ Faut-il vraiment un sitemap XML pour être indexé par Google ?
- □ Faut-il vraiment automatiser la génération de vos sitemaps ?
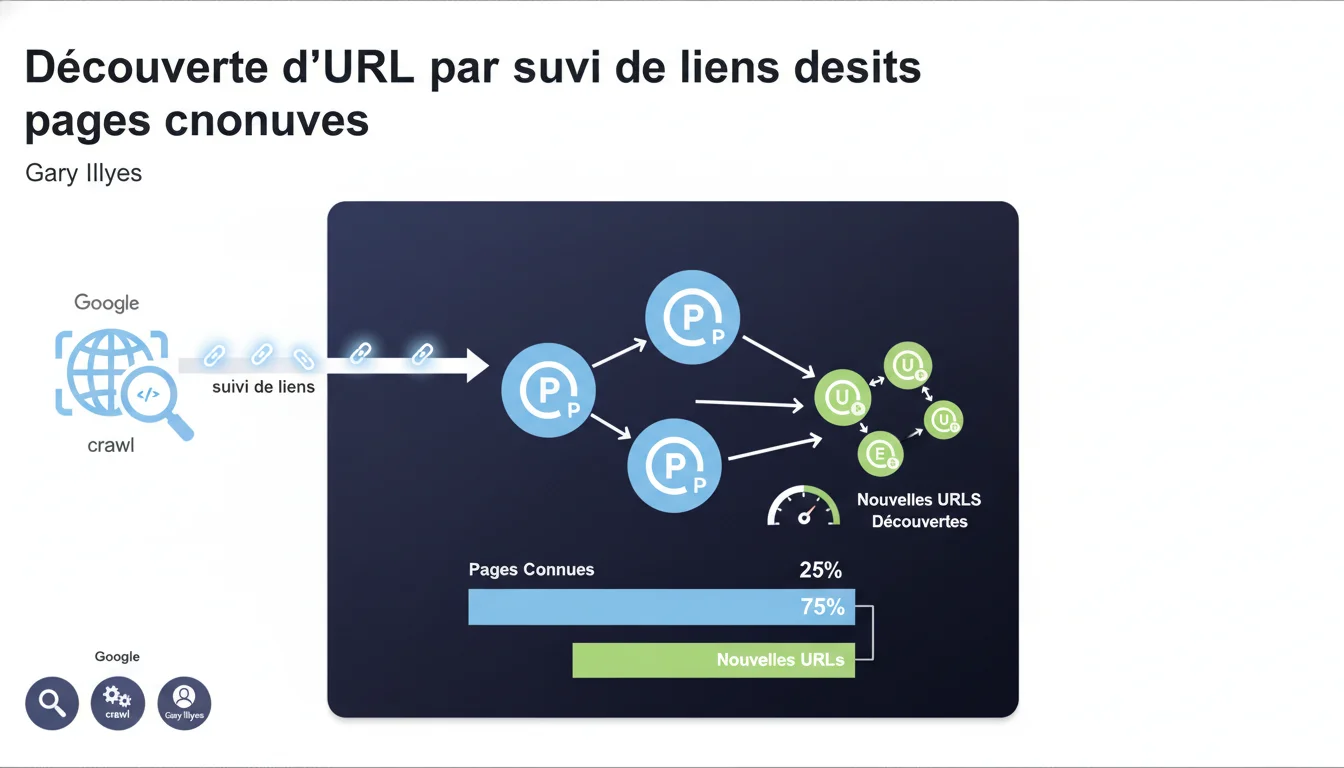
Google découvre l'essentiel de vos nouvelles URLs en suivant des liens depuis des pages qu'il connaît déjà. Le suivi de liens reste le mode de découverte dominant, bien avant les sitemaps XML ou l'API Indexing. Votre maillage interne et vos backlinks déterminent donc directement la vitesse et l'exhaustivité de la découverte de votre contenu par Googlebot.
Ce qu'il faut comprendre
Cette déclaration de Gary Illyes rappelle un principe fondamental du fonctionnement de Google : le crawl suit les liens. Googlebot navigue de page en page comme un utilisateur, en suivant les URLs qu'il trouve dans le code HTML.
Cela signifie que votre capacité à faire indexer rapidement du nouveau contenu dépend directement de la structure de liens qui y mène depuis des pages déjà crawlées et en cache dans l'index de Google.
Pourquoi cette déclaration sort-elle maintenant ?
Google rappelle régulièrement ce mécanisme parce que trop de sites comptent encore exclusivement sur les sitemaps XML pour signaler leurs nouveaux contenus. Soyons honnêtes : le sitemap est un filet de sécurité, pas votre stratégie principale.
Les observations terrain montrent que les pages bien maillées depuis la home ou depuis des hubs internes actifs sont découvertes en quelques minutes, tandis que celles isolées dans un sitemap peuvent attendre des jours — voire des semaines — avant un premier crawl.
Qu'est-ce que ça change concrètement pour mon SEO ?
Si vos nouvelles pages ne reçoivent pas de liens internes depuis des pages régulièrement crawlées, elles resteront invisibles pour Googlebot pendant un temps imprévisible. Le crawl budget n'est pas infini, et Google priorise les chemins de liens qu'il connaît déjà.
Cela signifie également que votre profil de backlinks joue un rôle double : il transmet du jus SEO, certes, mais il accélère aussi la découverte de nouvelles sections de votre site si ces liens externes pointent vers des pages qui elles-mêmes maillent vos nouveaux contenus.
- Le crawl suit les liens : sans lien entrant, pas de découverte rapide
- Le maillage interne est votre principal levier de contrôle sur la vitesse de découverte
- Les sitemaps XML sont un complément, pas une solution de premier rang
- Les backlinks externes accélèrent la découverte s'ils pointent vers des pages qui maillent vos nouveaux contenus
- Les pages orphelines (sans lien entrant interne ou externe) ont peu de chances d'être découvertes naturellement
Le sitemap XML est-il donc inutile ?
Non. Mais son rôle est souvent surestimé. Il sert surtout de filet de rattrapage pour les URLs que Googlebot n'aurait pas découvertes autrement — typiquement des pages profondes ou récemment publiées sans maillage optimal.
Le sitemap accélère rarement la découverte autant qu'un bon lien interne depuis une page à forte fréquence de crawl. C'est une assurance, pas un turbo.
Avis d'un expert SEO
Cette déclaration est-elle cohérente avec les pratiques observées ?
Oui, totalement. Les logs serveur le confirment sans ambiguïté : les nouvelles pages liées depuis la home, depuis des pages catégories actives ou depuis des articles récents bien crawlés apparaissent dans les logs en quelques minutes. Les pages isolées dans un sitemap peuvent attendre des jours.
J'ai observé sur des sites e-commerce que les fiches produits liées depuis des landing pages SEO actives sont crawlées 10 à 50 fois plus vite que celles découvertes uniquement via sitemap. Le delta est énorme.
Quelles nuances faut-il apporter ?
Gary Illyes dit « la plupart » des nouvelles URLs, pas « toutes ». Il existe d'autres canaux de découverte : les sitemaps XML, l'API Indexing (réservée à certains types de contenus), les redirections, les mentions d'URLs dans des flux RSS, etc.
Mais [A vérifier] : Google ne publie aucune statistique précise sur la part réelle de chaque canal. On ne sait pas si « la plupart » signifie 60 %, 80 % ou 95 %. Cette opacité est frustrante pour qui veut optimiser finement son crawl budget.
Autre point : cette déclaration ne dit rien sur la vitesse de crawl. Découvrir une URL ne signifie pas la crawler immédiatement. Une URL peut être découverte via un lien mais rester en file d'attente si le crawl budget est saturé ou si Google juge la page peu prioritaire.
Dans quels cas cette règle ne s'applique-t-elle pas complètement ?
Les contenus éphémères ou temps réel — offres d'emploi, événements, actualités urgentes — peuvent bénéficier de l'API Indexing qui court-circuite le crawl classique. Mais cette API est réservée à des use cases précis, et Google la limite strictement.
Les très gros sites avec des millions de pages génèrent aussi des découvertes par analyse de patterns d'URLs ou par extraction depuis des bases de données externes (par exemple, des agrégateurs de flux). Mais ces méthodes restent minoritaires et opaques.
Impact pratique et recommandations
Que faut-il faire concrètement pour accélérer la découverte de vos nouvelles pages ?
Placez des liens internes vers vos nouvelles pages depuis vos pages les plus crawlées — typiquement la home, les pages catégories principales, les articles récents à forte visibilité. Plus le lien est proche de la home en nombre de clics, plus la découverte est rapide.
Identifiez vos pages à haute fréquence de crawl via vos logs serveur (Search Console ne suffit pas ici). Ce sont vos « portes d'entrée » pour Googlebot. Utilisez-les comme tremplins pour vos nouveaux contenus.
Évitez les pages orphelines : toute nouvelle page doit recevoir au minimum un lien interne contextuel depuis une page déjà en cache. Un lien dans un menu ou un footer, c'est mieux que rien, mais un lien éditorial dans le corps d'un article récent est bien plus efficace.
Quelles erreurs éviter absolument ?
Ne comptez pas uniquement sur votre sitemap XML pour faire découvrir vos nouvelles pages. C'est un complément, pas une stratégie. Les sites qui publient du contenu sans maillage interne et attendent que Google « fasse le boulot » via le sitemap perdent des jours, voire des semaines.
Évitez aussi de surcharger vos sitemaps avec des millions d'URLs peu prioritaires. Google crawle les sitemaps, certes, mais avec un budget limité. Si votre sitemap contient 90 % de pages sans valeur, les 10 % importantes seront noyées.
Autre erreur classique : créer du maillage interne depuis des pages elles-mêmes jamais crawlées. Un lien depuis une page zombie ne sert à rien. Vérifiez que vos pages « relais » sont effectivement visitées par Googlebot.
Comment vérifier que votre stratégie de découverte fonctionne ?
Analysez vos logs serveur. Repérez le délai entre la publication d'une nouvelle page et son premier crawl par Googlebot. Si ce délai dépasse 24-48h pour des pages stratégiques, c'est un signal d'alarme : votre maillage interne ou votre crawl budget est défaillant.
Dans la Search Console, suivez le rapport de couverture et croisez-le avec vos dates de publication. Les pages « Découvertes mais non explorées » ou « Explorées mais non indexées » révèlent souvent des problèmes de maillage ou de qualité perçue.
- Lier chaque nouvelle page depuis au moins une page à haute fréquence de crawl
- Identifier vos pages « portes d'entrée » pour Googlebot via logs serveur
- Vérifier que vos sitemaps ne sont pas surchargés d'URLs inutiles
- Éviter les pages orphelines : zéro lien entrant = découverte aléatoire
- Suivre le délai de découverte dans vos logs pour ajuster le maillage
- Ne pas compter uniquement sur les sitemaps XML pour les contenus stratégiques
❓ Questions frequentes
Les sitemaps XML sont-ils encore utiles si Google découvre les pages par liens ?
Combien de temps faut-il à Google pour découvrir une nouvelle page via un lien interne ?
Une page découverte est-elle automatiquement indexée ?
Les backlinks externes accélèrent-ils la découverte de nouvelles pages internes ?
Comment savoir si mes nouvelles pages sont découvertes rapidement ?
🎥 De la même vidéo 9
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 22/02/2024
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.