Official statement
Other statements from this video 9 ▾
- □ Comment Google crawle-t-il vraiment vos pages web ?
- □ Pourquoi Google ne découvre-t-il pas toutes les URLs de votre site ?
- □ Comment Googlebot décide-t-il quelles pages crawler sur votre site ?
- □ Googlebot ralentit-il volontairement sur votre site pour ne pas le surcharger ?
- □ Pourquoi Googlebot ignore-t-il une partie des URLs qu'il découvre ?
- □ Googlebot peut-il vraiment crawler le contenu derrière une page de connexion ?
- □ Pourquoi Google ne voit-il pas votre contenu JavaScript sans rendering ?
- □ Faut-il vraiment un sitemap XML pour être indexé par Google ?
- □ Faut-il vraiment automatiser la génération de vos sitemaps ?
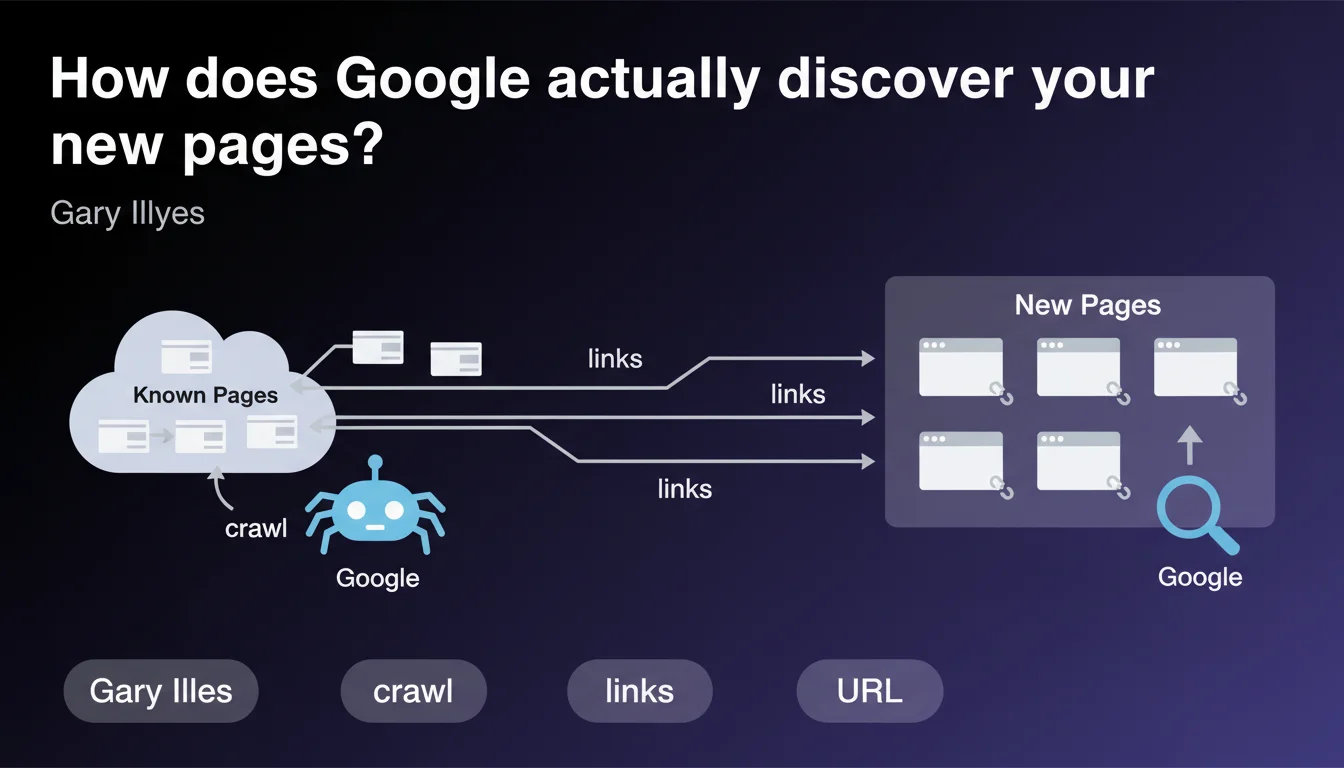
Google discovers most of your new URLs by following links from pages it already knows. Link following remains the dominant discovery method, well ahead of XML sitemaps or the Indexing API. Your internal linking structure and backlinks directly determine how fast and comprehensively Googlebot discovers your content.
What you need to understand
This statement from Gary Illyes reinforces a fundamental principle of how Google works: crawling follows links. Googlebot navigates from page to page like a user, following the URLs it finds in HTML code.
This means your ability to get new content indexed quickly depends directly on the link structure leading to it from pages that are already crawled and cached in Google's index.
Why is this statement coming out now?
Google regularly reminds the SEO community of this mechanism because too many sites still rely exclusively on XML sitemaps to signal new content. Let's be honest: the sitemap is a safety net, not your primary strategy.
Field observations show that pages well-linked from the homepage or from active internal hubs are discovered within minutes, while those isolated in a sitemap may wait days—or even weeks—before their first crawl.
What does this actually change for my SEO?
If your new pages don't receive internal links from regularly-crawled pages, they'll remain invisible to Googlebot for an unpredictable amount of time. Crawl budget is not infinite, and Google prioritizes link paths it already knows.
This also means your backlink profile plays a dual role: it passes SEO juice, sure, but it also accelerates the discovery of new sections of your site if those external links point to pages that themselves link to your new content.
- Crawling follows links: without an incoming link, rapid discovery won't happen
- Internal linking is your primary lever for controlling discovery speed
- XML sitemaps are a complement, not a first-tier solution
- External backlinks accelerate discovery if they point to pages that link to your new content
- Orphaned pages (with no internal or external incoming links) have little chance of being naturally discovered
Is the XML sitemap therefore useless?
No. But its role is often overestimated. It mainly serves as a safety net for URLs that Googlebot wouldn't have discovered otherwise—typically deep pages or recently published pages without optimal linking.
The sitemap rarely accelerates discovery as much as a good internal link from a high-crawl-frequency page does. It's insurance, not a turbo boost.
SEO Expert opinion
Is this statement consistent with observed practices?
Yes, absolutely. Server logs confirm it without ambiguity: new pages linked from the homepage, from active category pages, or from recent well-crawled articles appear in logs within minutes. Pages isolated in a sitemap may wait days.
I've observed on e-commerce sites that product pages linked from active SEO landing pages are crawled 10 to 50 times faster than those discovered solely via sitemap. The gap is huge.
What nuances should we add?
Gary Illyes says "most" new URLs, not "all." There are other discovery channels: XML sitemaps, the Indexing API (limited to certain content types), redirects, URL mentions in RSS feeds, etc.
But [To verify]: Google publishes no precise statistics on the actual share of each channel. We don't know if "most" means 60%, 80%, or 95%. This opacity is frustrating for those wanting to fine-tune crawl budget optimization.
Another point: this statement says nothing about crawl speed. Discovering a URL doesn't mean crawling it immediately. A URL can be discovered via a link but remain in queue if crawl budget is saturated or if Google deems the page low priority.
In what cases doesn't this rule apply completely?
Ephemeral or real-time content—job postings, events, breaking news—can benefit from the Indexing API, which bypasses traditional crawling. But this API is limited to specific use cases, and Google restricts it tightly.
Very large sites with millions of pages also generate discoveries through URL pattern analysis or extraction from external databases (for example, feed aggregators). But these methods remain minority and opaque.
Practical impact and recommendations
What should you concretely do to accelerate the discovery of your new pages?
Place internal links to your new pages from your most-crawled pages—typically the homepage, main category pages, and recent articles with high visibility. The closer the link is to the homepage in click distance, the faster the discovery.
Identify your high-crawl-frequency pages via your server logs (Search Console isn't enough here). These are your "entry doors" for Googlebot. Use them as springboards for your new content.
Avoid orphaned pages: every new page should receive at minimum one contextual internal link from an already-cached page. A link in a menu or footer is better than nothing, but an editorial link in the body of a recent article is far more effective.
What mistakes should you avoid at all costs?
Don't rely exclusively on your XML sitemap to get new pages discovered. It's a complement, not a strategy. Sites that publish content without internal linking and wait for Google to "do the work" via the sitemap lose days, even weeks.
Also avoid overloading your sitemaps with millions of low-priority URLs. Google does crawl sitemaps, but with limited budget. If your sitemap contains 90% worthless pages, the important 10% will be buried.
Another classic mistake: creating internal links from pages that are themselves never crawled. A link from a zombie page does nothing. Verify that your "relay" pages are actually visited by Googlebot.
How do you verify that your discovery strategy is working?
Analyze your server logs. Track the delay between publishing a new page and its first crawl by Googlebot. If this delay exceeds 24-48 hours for strategic pages, that's a red flag: your internal linking or crawl budget is failing.
In Search Console, monitor the coverage report and cross-reference it with your publication dates. Pages marked "Discovered but not explored" or "Explored but not indexed" often reveal internal linking or perceived quality issues.
- Link every new page from at least one high-crawl-frequency page
- Identify your "entry door" pages for Googlebot via server logs
- Verify your sitemaps aren't overloaded with useless URLs
- Avoid orphaned pages: zero incoming links = random discovery
- Track discovery delay in your logs to adjust linking strategy
- Don't rely solely on XML sitemaps for strategic content
❓ Frequently Asked Questions
Les sitemaps XML sont-ils encore utiles si Google découvre les pages par liens ?
Combien de temps faut-il à Google pour découvrir une nouvelle page via un lien interne ?
Une page découverte est-elle automatiquement indexée ?
Les backlinks externes accélèrent-ils la découverte de nouvelles pages internes ?
Comment savoir si mes nouvelles pages sont découvertes rapidement ?
🎥 From the same video 9
Other SEO insights extracted from this same Google Search Central video · published on 22/02/2024
🎥 Watch the full video on YouTube →
💬 Comments (0)
Be the first to comment.