Official statement
Other statements from this video 9 ▾
- □ Comment Google crawle-t-il vraiment vos pages web ?
- □ Comment Google découvre-t-il vraiment vos nouvelles pages ?
- □ Pourquoi Google ne découvre-t-il pas toutes les URLs de votre site ?
- □ Comment Googlebot décide-t-il quelles pages crawler sur votre site ?
- □ Googlebot ralentit-il volontairement sur votre site pour ne pas le surcharger ?
- □ Googlebot peut-il vraiment crawler le contenu derrière une page de connexion ?
- □ Pourquoi Google ne voit-il pas votre contenu JavaScript sans rendering ?
- □ Faut-il vraiment un sitemap XML pour être indexé par Google ?
- □ Faut-il vraiment automatiser la génération de vos sitemaps ?
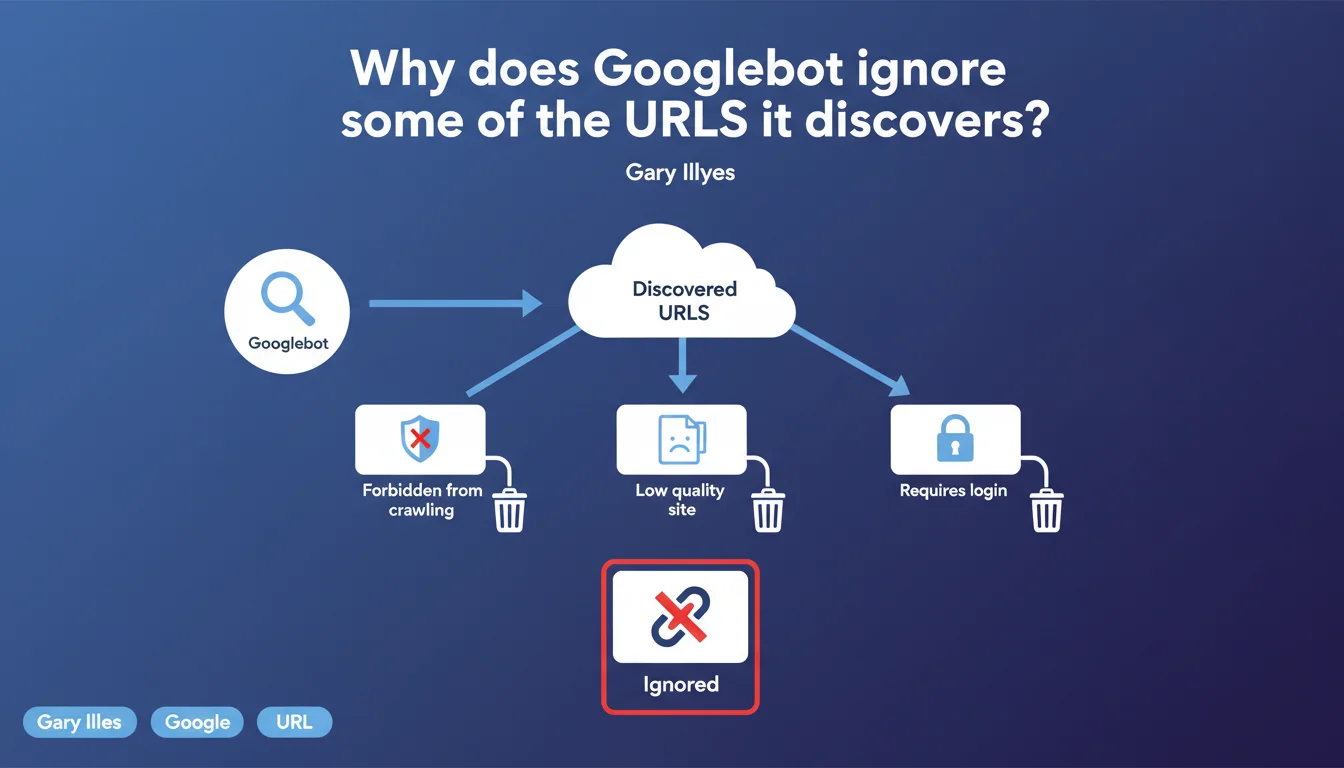
Googlebot does not crawl all the URLs it detects. Some pages are excluded because they belong to sites that do not meet the minimum quality threshold for indexing, while others are blocked technically or require authentication. This confirms that crawling is conditioned by an upstream quality filter, even before indexation.
What you need to understand
This statement confirms what many of us observe in the field: not all discovered URLs deserve to be crawled. Google performs a filtering process upstream, before even allocating crawl budget to a page.
Gary Illyes's message reveals the existence of an upstream quality filter that applies at the site or domain level. If your site does not pass this threshold, Googlebot may decide not to crawl certain URLs it has discovered through internal links, sitemaps, or backlinks.
What criteria determine this quality threshold?
Google does not explicitly specify the criteria, but field experience suggests several indicators: domain authority, overall content quality, user signals (bounce rate, time on page), update freshness, and likely metrics related to site expertise and trustworthiness.
This threshold is not binary — there is a gradation. A low-quality site will see a large proportion of its URLs ignored, while a high-authority site will benefit from quasi-systematic crawling of newly discovered pages.
Which URLs are blocked for technical reasons?
Beyond the quality filter, certain URLs are technically inaccessible to Googlebot: pages protected by robots.txt, URLs behind a login wall, content requiring complex JavaScript that is not interpretable, or pages with response times that are too long.
These technical blocks are often intentional (member areas, backend), but sometimes accidental — a misconfigured robots.txt or a redirect loop can prevent crawling of strategic URLs.
- Crawling is conditioned by an upstream quality filter, independent of the technical indexability of a page.
- Googlebot performs selective sorting based on perceived authority and quality of the site.
- Technical obstacles (robots.txt, authentication) also prevent crawling, but these are two distinct issues.
- A discovered URL is not a crawled URL, and even less an indexed URL.
SEO Expert opinion
Is this quality threshold logic consistent with field observations?
Absolutely. On sites with low authority or content issues, we regularly observe discovered but non-crawled URLs in Search Console. Some pages remain for months in "Discovered – currently not indexed" status without ever being visited by Googlebot.
The problem is that Google never clearly communicates where this threshold sits. [To verify] — no official metric allows you to know whether your site is above or below it. We are reduced to interpreting indirect signals: crawl frequency, proportion of indexed URLs, average discovery time.
What nuances should be added to this statement?
Gary Illyes speaks of "quality threshold required for indexing", but let's be precise: this is a threshold for being crawled, not indexed. This is an even earlier stage. A page can be crawled and then rejected from indexing for other reasons (duplicate content, thin content, noindex).
Another important nuance — this filter likely applies with varying degrees of severity depending on sections of a site. A product page on an established e-commerce site will have a better chance of being crawled than a blog post on a new site, even if both belong to different domains.
In which cases does this rule not apply strictly?
Sites with very high authority (national media, institutions, major platforms) appear to benefit from privileged treatment: their new URLs are generally crawled very quickly, sometimes within minutes. The quality threshold matters less — or rather, these sites exceed it by default.
Similarly, a URL widely shared from reliable sources can force crawling even if the hosting site is of average quality. The external signal (quality backlinks) partially compensates for the inherent weakness of the domain.
Practical impact and recommendations
What should you concretely do to improve your URLs' crawl rate?
First priority: strengthen the perceived quality of your site overall. This involves original and in-depth content, regular updates, expertise signals (authorship, author bio, external citations), and improved Core Web Vitals.
Next, rationalize your architecture. If Google believes your site does not deserve exhaustive crawling, you need to prioritize strategic URLs: remove low-value pages, consolidate internal linking toward priority content, and avoid diluting crawl budget across thousands of undifferentiated pages.
What mistakes should you avoid at all costs?
Do not waste time massively submitting URLs via the Indexing API if your site is below the quality threshold — it will not change anything. Google has already decided upstream that these pages are not worth immediate crawling.
Another common mistake: believing that an XML sitemap is enough to guarantee crawling. A sitemap signals URLs, but does not force Googlebot to visit them if the site does not meet the quality threshold. It is a discovery tool, not a guaranteed indexing lever.
How can you verify that your site is above the threshold?
Two indicators in Search Console are revealing. First signal: the average time between URL discovery (via sitemap or internal link) and its first crawl. If it exceeds several weeks for new content, that's a bad sign.
Second signal: the ratio between detected URLs and indexed URLs. A massive gap (e.g., 10,000 detected, 2,000 indexed) indicates either a content quality issue or a site below threshold. Cross-reference with crawl statistics to confirm.
- Audit the real quality of your content — be honest about the added value you provide.
- Remove or consolidate low-value pages to concentrate crawl budget.
- Strengthen internal linking toward strategic URLs.
- Monitor the discovery/crawl delay in Search Console to detect potential filtering.
- Do not multiply manual submissions if the problem is structural — it will not speed anything up.
- Build domain authority through quality backlinks and trust signals (mentions, citations).
Optimizing to pass this quality threshold requires a holistic approach: content, technical aspects, authority, and user signals. These levers are interdependent and require a strategic vision over several months.
For sites facing persistent blocks or large volumes of non-crawled URLs, it may be worthwhile to engage a specialized SEO agency capable of thoroughly auditing the quality signals perceived by Google and piloting structured domain authority growth.
❓ Frequently Asked Questions
Combien de temps faut-il attendre avant qu'une URL découverte soit crawlée ?
Soumettre une URL via l'outil d'inspection force-t-il le crawl ?
Un sitemap XML garantit-il que toutes les URLs listées seront crawlées ?
Comment savoir si mon site est en dessous du seuil qualité ?
Les backlinks vers une URL non crawlée peuvent-ils forcer Googlebot à la visiter ?
🎥 From the same video 9
Other SEO insights extracted from this same Google Search Central video · published on 22/02/2024
🎥 Watch the full video on YouTube →
💬 Comments (0)
Be the first to comment.