Official statement
Other statements from this video 9 ▾
- □ Comment Google crawle-t-il vraiment vos pages web ?
- □ Comment Google découvre-t-il vraiment vos nouvelles pages ?
- □ Pourquoi Google ne découvre-t-il pas toutes les URLs de votre site ?
- □ Googlebot ralentit-il volontairement sur votre site pour ne pas le surcharger ?
- □ Pourquoi Googlebot ignore-t-il une partie des URLs qu'il découvre ?
- □ Googlebot peut-il vraiment crawler le contenu derrière une page de connexion ?
- □ Pourquoi Google ne voit-il pas votre contenu JavaScript sans rendering ?
- □ Faut-il vraiment un sitemap XML pour être indexé par Google ?
- □ Faut-il vraiment automatiser la génération de vos sitemaps ?
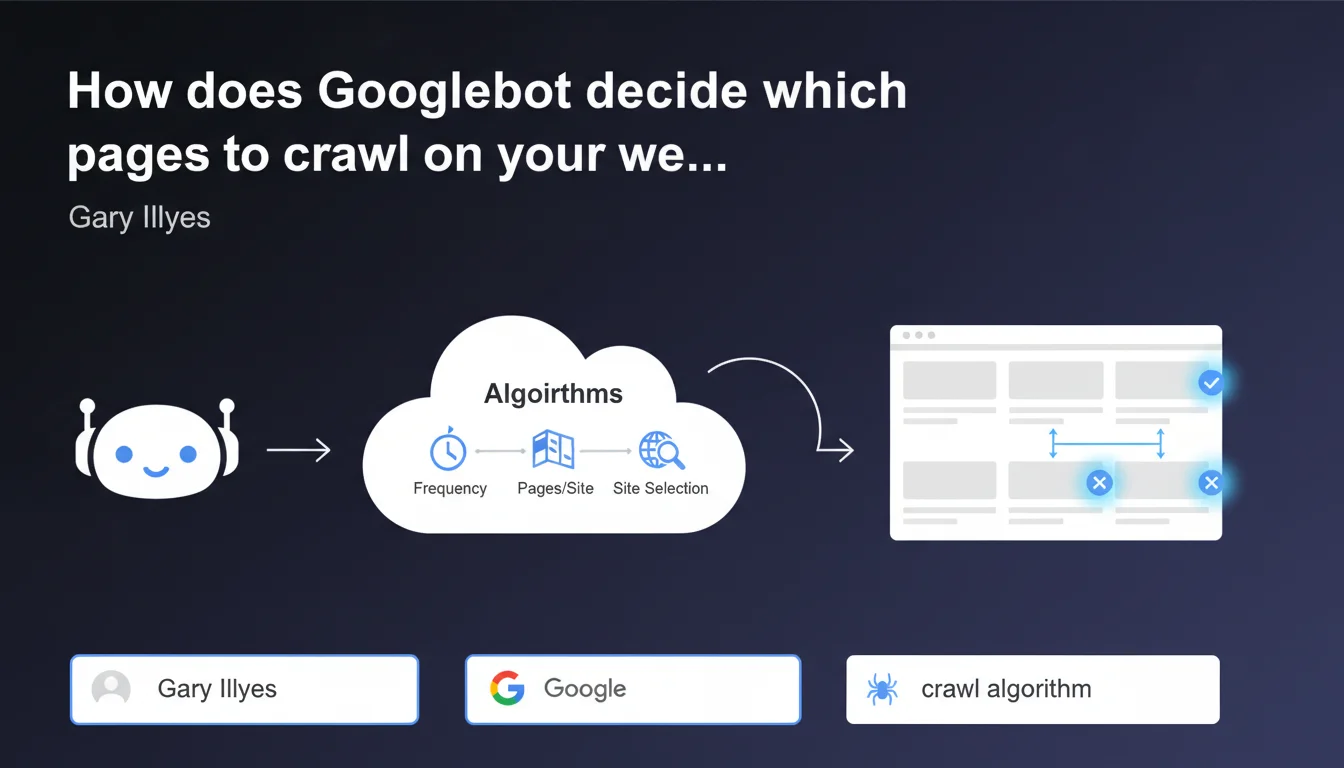
Googlebot relies on algorithms to determine which sites to explore, how frequently, and how many pages to fetch from each site. This statement confirms that there is no universal rule: each site is evaluated individually according to criteria that Google does not detail precisely. The challenge for SEOs is to optimize the signals sent to Googlebot to maximize the crawl of strategic pages.
What you need to understand
What criteria does Googlebot use to prioritize crawl?
Google does not provide the exhaustive list of criteria used by its crawl algorithms. However, we know that content update frequency, domain authority, quality of backlinks, and page popularity play a decisive role.
The technical structure of the site also plays a role: server response time, page depth, quality of internal linking, and presence of errors directly influence Googlebot's ability to explore your content effectively.
Is the crawl budget the same for all sites?
No. Each site has a crawl budget — an allocation of resources that Googlebot devotes to exploration. This budget varies depending on the size, authority, and technical health of the site.
A small blog will never have the same crawl budget as an e-commerce site with 100,000 pages. Google dynamically adjusts this allocation based on observed performance and indexation demand.
Does this algorithmic approach mean a loss of control for SEOs?
Partially. You cannot force Googlebot to crawl a specific page at a given frequency. But you retain control over the technical and semantic signals that guide its decisions.
The robots.txt file, the XML sitemap, canonical directives and noindex, as well as loading speed remain actionable levers. The challenge is to maximize crawl efficiency on your high-value pages.
- Googlebot uses opaque algorithms to decide what to crawl and how frequently
- Crawl budget varies significantly from site to site based on several criteria
- Technical structure, content freshness, and authority influence these decisions
- SEOs retain optimization levers but do not directly control crawl frequency
SEO Expert opinion
Is this statement consistent with what we observe in the field?
Yes, overall. Observations align: sites with clean architecture, frequently updated content, and solid authority benefit from more intensive crawling. Conversely, neglected technical sites or content farms see their crawl budget drastically reduced.
However, Google remains deliberately vague about the precise criteria and their respective weighting. It's impossible to know whether server speed carries more weight than page depth, for example. [To verify]: the exact impact of each technical factor remains largely opaque.
What nuances does this statement mask?
First point: saying that Googlebot "uses algorithms" provides no concrete information. It's obvious — but it explains nothing about the underlying logic.
Second point: the wording suggests that the system is entirely automated. Yet we know that Google can manually adjust the crawl of certain sites in case of penalty or major technical issues. This statement therefore simplifies a more complex reality.
Third point — and this is crucial: crawl frequency does not guarantee indexation. Googlebot may visit your pages daily without ever indexing them if they are deemed low quality or redundant. [To verify]: many sites still confuse "being crawled" and "being indexed," two distinct steps in the process.
In what cases does this rule not apply?
Certain types of content escape classic crawl budget rules. Content blocked by robots.txt will never be crawled (logical). Orphan pages — without internal or external incoming links — can slip under the radar for months.
Practical impact and recommendations
How to optimize your site to maximize crawl of strategic pages?
First action: audit your server logs to identify which pages Googlebot actually crawls, how frequently, and how many resources it consumes. Without this visibility, you're flying blind.
Second action: prioritize internal linking to your high-value pages. The more internal links a page receives from frequently crawled pages, the more it will be visited by Googlebot. Deep pages (4-5 clicks from the homepage) are often under-crawled.
Third action: eliminate crawl budget drains. Infinite facets, poorly managed paginated pages, duplicate content, URLs with parameters — anything that generates thousands of pages without value should be blocked or canonicalized.
What mistakes should you avoid to not waste your crawl budget?
Never block essential resources (CSS, JS) in robots.txt if they are necessary for rendering. Google needs access to these files to understand your pages. Abusive blocking can harm the assessment of your content.
Avoid chained redirects (A → B → C). Each hop consumes crawl budget unnecessarily. Redirect directly from A to C. Also verify that your HTTP codes are consistent: a page that returns a 200 but should return a 404 pollutes the index.
Don't over-optimize at the expense of user experience. If you block all your images to "save crawl budget," you degrade the perceived quality of your pages — which can ultimately reduce their crawl priority.
Which tools should you use to track and improve your site's crawl?
Search Console provides basic crawl data: errors, crawl statistics, indexation coverage. It's your first checkpoint, but the data is aggregated and sometimes delayed.
For detailed analysis, move to server log analysis with tools like Oncrawl, Botify, or Screaming Frog Log Analyzer. You'll see in real time which pages Googlebot visits, how often, and which resources it ignores.
- Regularly audit your server logs to understand Googlebot's actual behavior
- Optimize internal linking to push crawl toward your strategic pages
- Eliminate crawl budget drains: facets, poorly managed pagination, duplicates
- Fix chained redirects and standardize your HTTP codes
- Never block CSS/JS necessary for rendering in robots.txt
- Monitor crawl evolution with Search Console and log analysis tools
❓ Frequently Asked Questions
Googlebot crawle-t-il toutes les pages de mon site ?
Puis-je forcer Googlebot à crawler une page spécifique plus souvent ?
Le crawl budget est-il un problème pour les petits sites ?
Comment savoir si mon site a un problème de crawl budget ?
La vitesse du serveur impacte-t-elle vraiment le crawl ?
🎥 From the same video 9
Other SEO insights extracted from this same Google Search Central video · published on 22/02/2024
🎥 Watch the full video on YouTube →
💬 Comments (0)
Be the first to comment.