Declaration officielle
Autres déclarations de cette vidéo 9 ▾
- □ Comment Google crawle-t-il vraiment vos pages web ?
- □ Comment Google découvre-t-il vraiment vos nouvelles pages ?
- □ Pourquoi Google ne découvre-t-il pas toutes les URLs de votre site ?
- □ Comment Googlebot décide-t-il quelles pages crawler sur votre site ?
- □ Googlebot ralentit-il volontairement sur votre site pour ne pas le surcharger ?
- □ Googlebot peut-il vraiment crawler le contenu derrière une page de connexion ?
- □ Pourquoi Google ne voit-il pas votre contenu JavaScript sans rendering ?
- □ Faut-il vraiment un sitemap XML pour être indexé par Google ?
- □ Faut-il vraiment automatiser la génération de vos sitemaps ?
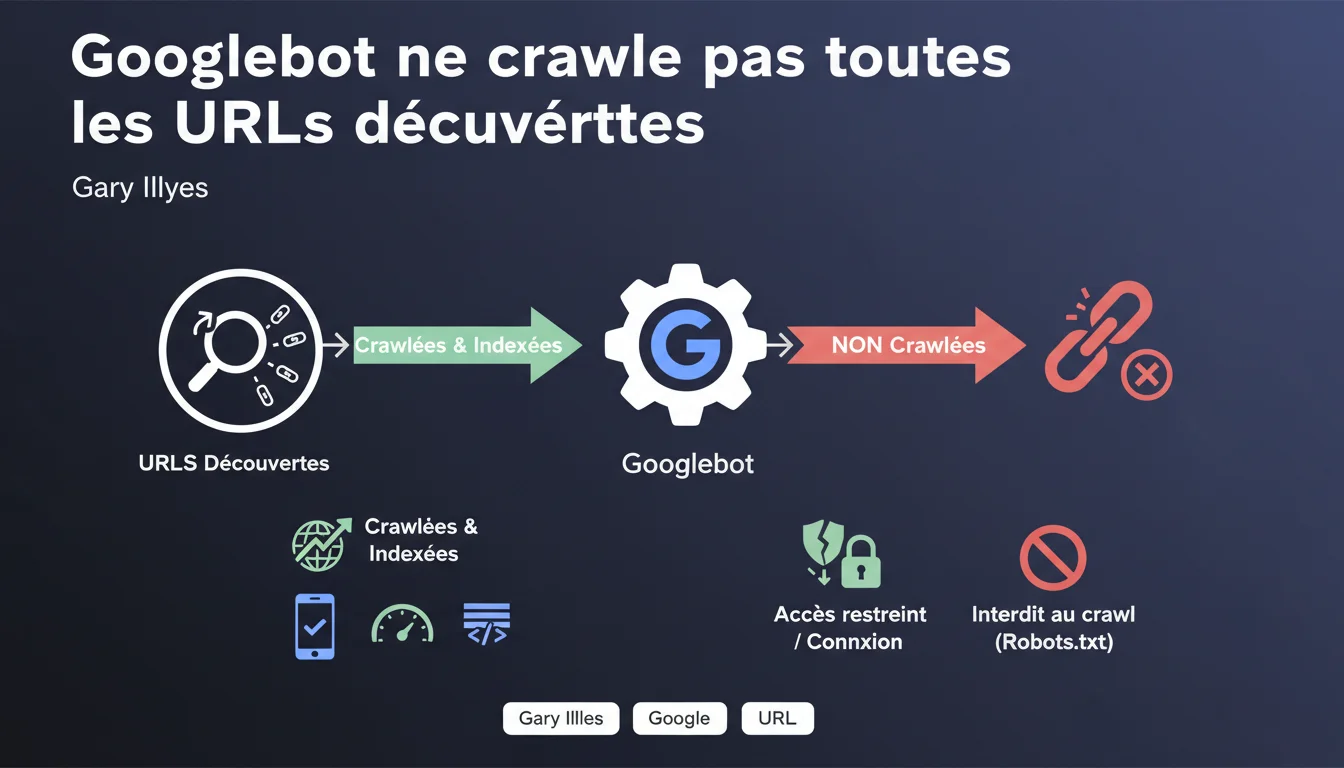
Googlebot ne crawle pas toutes les URLs qu'il détecte. Certaines pages sont écartées car elles appartiennent à des sites qui ne franchissent pas le seuil de qualité minimal pour l'indexation, d'autres sont bloquées techniquement ou nécessitent une authentification. C'est une confirmation que le crawl est conditionné par un filtre qualité en amont, avant même l'indexation.
Ce qu'il faut comprendre
Cette déclaration confirme ce que beaucoup d'entre nous observons sur le terrain : toutes les URLs découvertes ne méritent pas d'être crawlées. Google opère un tri en amont, avant même d'allouer du crawl budget à une page.
Le message de Gary Illyes révèle l'existence d'un filtre qualité préalable qui s'applique au niveau du site ou du domaine. Si votre site ne franchit pas ce seuil, Googlebot peut décider de ne pas crawler certaines URLs qu'il a pourtant découvertes via des liens internes, des sitemaps ou des backlinks.
Quels critères déterminent ce seuil de qualité ?
Google ne précise pas explicitement les critères, mais l'expérience terrain suggère plusieurs indicateurs : l'autorité du domaine, la qualité globale du contenu, les signaux utilisateurs (taux de rebond, temps passé), la fraîcheur des mises à jour, et probablement des métriques liées à l'expertise et à la fiabilité du site.
Ce seuil n'est pas binaire — il existe une gradation. Un site de faible qualité verra une proportion importante de ses URLs ignorées, tandis qu'un site de référence bénéficiera d'un crawl quasi-systématique des nouvelles découvertes.
Quelles URLs sont bloquées pour des raisons techniques ?
Au-delà du filtre qualité, certaines URLs sont techniquement inaccessibles pour Googlebot : pages protégées par robots.txt, URLs derrière un login, contenus nécessitant JavaScript complexe non interprétable, ou encore pages avec des temps de réponse trop longs.
Ces blocages techniques sont souvent intentionnels (zone membre, backoffice), mais parfois accidentels — un robots.txt mal configuré ou une redirection en boucle peut empêcher le crawl d'URLs stratégiques.
- Le crawl est conditionné par un filtre qualité en amont, indépendant de l'indexabilité technique d'une page.
- Googlebot opère un tri sélectif basé sur l'autorité et la qualité perçue du site.
- Les obstacles techniques (robots.txt, authentification) empêchent également le crawl, mais ce sont deux problématiques distinctes.
- Une URL découverte n'est pas une URL crawlée, et encore moins une URL indexée.
Avis d'un expert SEO
Cette logique de seuil qualité est-elle cohérente avec les observations terrain ?
Absolument. Sur des sites à faible autorité ou avec des problèmes de contenu, on observe régulièrement des URLs découvertes mais non crawlées dans la Search Console. Certaines pages restent des mois en statut « Détectée – actuellement non indexée » sans jamais être visitées par Googlebot.
Le problème, c'est que Google ne communique jamais clairement où se situe ce fameux seuil. [A vérifier] — aucune métrique officielle ne permet de savoir si votre site est au-dessus ou en dessous. On est réduit à interpréter des signaux indirects : fréquence de crawl, proportion d'URLs indexées, temps de découverte moyen.
Quelles nuances faut-il apporter à cette déclaration ?
Gary Illyes parle de « seuil de qualité requis pour être indexés », mais soyons précis : il s'agit ici d'un seuil pour être crawlé, pas indexé. C'est une étape encore plus en amont. Une page peut être crawlée et ensuite rejetée à l'indexation pour d'autres raisons (duplicate content, thin content, noindex).
Autre nuance importante — ce filtre s'applique probablement avec des degrés de sévérité variables selon les sections d'un site. Une page produit sur un e-commerce établi aura plus de chances d'être crawlée qu'un article de blog sur un site récent, même si les deux appartiennent à des domaines différents.
Dans quels cas cette règle ne s'applique-t-elle pas strictement ?
Les sites à très forte autorité (médias nationaux, institutions, plateformes majeures) semblent bénéficier d'un traitement privilégié : leurs nouvelles URLs sont généralement crawlées très rapidement, parfois en quelques minutes. Le seuil qualité joue moins — ou plutôt, ces sites le franchissent largement par défaut.
De même, une URL massivement relayée sur des sources fiables peut forcer le crawl même si le site hébergeur est de qualité moyenne. Le signal externe (backlinks de qualité) compense partiellement la faiblesse intrinsèque du domaine.
Impact pratique et recommandations
Que faut-il faire concrètement pour améliorer le taux de crawl de vos URLs ?
Première priorité : renforcer la qualité perçue de votre site dans son ensemble. Ça passe par du contenu original et approfondi, une mise à jour régulière, des signaux d'expertise (authorship, bio auteur, citations externes), et une amélioration des Core Web Vitals.
Ensuite, rationalisez votre architecture. Si Google considère que votre site ne mérite pas un crawl exhaustif, il faut prioriser les URLs stratégiques : supprimez les pages à faible valeur, consolidez le maillage interne vers les contenus prioritaires, et évitez de diluer le crawl budget sur des milliers de pages peu différenciées.
Quelles erreurs éviter absolument ?
Ne perdez pas de temps à soumettre massivement des URLs via l'API Indexing si votre site est sous le seuil qualité — ça ne change rien. Google a déjà décidé en amont que ces pages ne valaient pas un crawl immédiat.
Autre erreur fréquente : croire qu'un sitemap XML suffit à garantir le crawl. Un sitemap signale des URLs, mais ne force pas Googlebot à les visiter si le site ne franchit pas le seuil qualité. C'est un outil de découverte, pas un levier d'indexation garanti.
Comment vérifier que votre site est au-dessus du seuil ?
Deux indicateurs dans la Search Console sont révélateurs. Premier signal : le délai moyen entre la découverte d'une URL (via sitemap ou lien interne) et son premier crawl. Si ça dépasse plusieurs semaines sur des contenus neufs, c'est mauvais signe.
Deuxième signal : le ratio entre URLs détectées et URLs indexées. Un écart massif (ex : 10 000 détectées, 2 000 indexées) indique soit un problème de qualité de contenu, soit un site sous le seuil. Croisez avec les stats de crawl pour confirmer.
- Auditez la qualité réelle de votre contenu — soyez honnête sur la valeur ajoutée apportée.
- Supprimez ou consolidez les pages à faible valeur pour concentrer le crawl budget.
- Renforcez le maillage interne vers les URLs stratégiques.
- Surveillez le délai découverte/crawl dans la Search Console pour détecter un éventuel filtrage.
- Ne multipliez pas les soumissions manuelles si le problème est structurel — ça n'accélérera rien.
- Travaillez l'autorité du domaine via des backlinks qualitatifs et des signaux de confiance (mentions, citations).
L'optimisation pour franchir ce seuil qualité demande une approche holistique : contenu, technique, autorité, signaux utilisateurs. Ces leviers sont interdépendants et nécessitent une vision stratégique sur plusieurs mois.
Pour les sites confrontés à des blocages persistants ou des volumes importants d'URLs non crawlées, il peut être judicieux de faire appel à une agence SEO spécialisée capable d'auditer finement les signaux qualité perçus par Google et de piloter une montée en autorité structurée.
❓ Questions frequentes
Combien de temps faut-il attendre avant qu'une URL découverte soit crawlée ?
Soumettre une URL via l'outil d'inspection force-t-il le crawl ?
Un sitemap XML garantit-il que toutes les URLs listées seront crawlées ?
Comment savoir si mon site est en dessous du seuil qualité ?
Les backlinks vers une URL non crawlée peuvent-ils forcer Googlebot à la visiter ?
🎥 De la même vidéo 9
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 22/02/2024
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.