Declaration officielle
Autres déclarations de cette vidéo 9 ▾
- □ Comment Google découvre-t-il vraiment vos nouvelles pages ?
- □ Pourquoi Google ne découvre-t-il pas toutes les URLs de votre site ?
- □ Comment Googlebot décide-t-il quelles pages crawler sur votre site ?
- □ Googlebot ralentit-il volontairement sur votre site pour ne pas le surcharger ?
- □ Pourquoi Googlebot ignore-t-il une partie des URLs qu'il découvre ?
- □ Googlebot peut-il vraiment crawler le contenu derrière une page de connexion ?
- □ Pourquoi Google ne voit-il pas votre contenu JavaScript sans rendering ?
- □ Faut-il vraiment un sitemap XML pour être indexé par Google ?
- □ Faut-il vraiment automatiser la génération de vos sitemaps ?
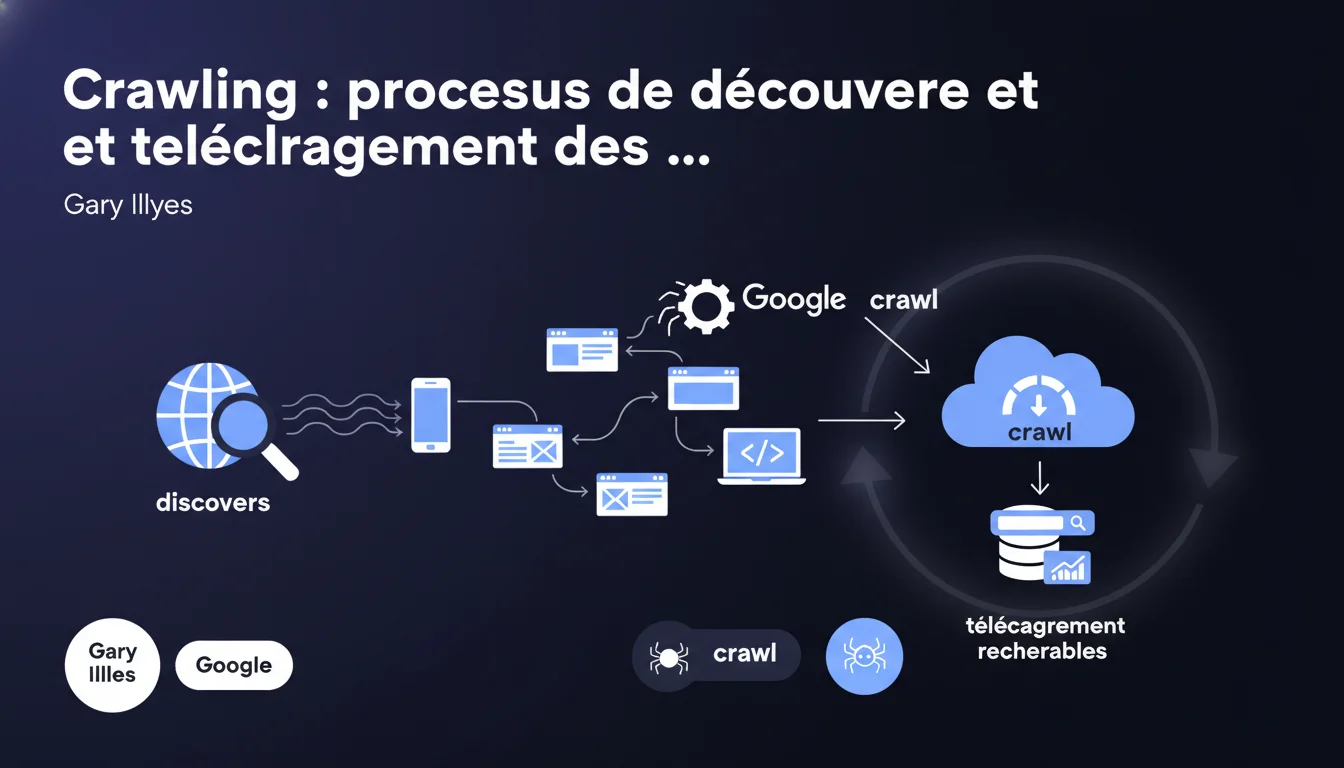
Google utilise des robots automatisés (crawlers) pour découvrir, télécharger et indexer les pages web. Le crawling est la première étape indispensable pour qu'une page devienne recherchable. Sans crawl, pas de présence dans les résultats de recherche.
Ce qu'il faut comprendre
Le crawling constitue la première brique du système d'indexation de Google. Avant qu'une page puisse apparaître dans les résultats, elle doit être visitée, téléchargée et analysée par un robot.
Cette déclaration officielle rappelle un fondamental : Google ne découvre pas vos contenus par magie. Il suit des liens, scanne des sitemaps, surveille les flux RSS et retourne périodiquement sur les URLs qu'il connaît déjà.
Pourquoi Google insiste-t-il sur cette distinction entre crawl et indexation ?
Parce que beaucoup de praticiens confondent les deux. Une page peut être crawlée sans être indexée — et c'est là que tout se complique.
Le téléchargement mentionné dans la déclaration implique que Google récupère l'intégralité du contenu HTML, CSS, JavaScript pour l'analyser. Ce n'est pas une simple lecture en surface.
Qu'est-ce qui déclenche le passage d'un crawler sur une page ?
Trois leviers principaux : la découverte par lien (interne ou externe), la soumission via sitemap XML, et les signaux de fraîcheur (fréquence de mise à jour, popularité).
Google alloue un budget de crawl différent selon la santé technique du site, sa popularité et la vitesse de réponse du serveur. Un site lent ou truffé d'erreurs 404 verra son budget rogné.
Quels sont les obstacles qui empêchent un crawl efficace ?
Plusieurs blocages techniques peuvent saboter le travail des crawlers : fichier robots.txt trop restrictif, balises meta noindex, redirections en chaîne, temps de réponse serveur trop longs, pagination mal gérée.
Les sites JavaScript lourds posent encore problème si le rendu côté serveur (SSR) ou la prérendu ne sont pas configurés correctement. Google crawle le HTML brut en priorité.
- Le crawling précède toujours l'indexation — une page non crawlée ne peut pas être indexée
- Budget de crawl limité — Google n'explore pas toutes vos pages à chaque visite
- Les signaux de qualité influencent la fréquence — un site technique sain et populaire est crawlé plus souvent
- Les obstacles techniques (robots.txt, redirections, erreurs serveur) bloquent ou ralentissent le crawl
- JavaScript complexe peut retarder ou empêcher la découverte de contenu si mal implémenté
Avis d'un expert SEO
Cette déclaration est-elle vraiment nouvelle ou juste un rappel ?
Soyons honnêtes : Gary Illyes ne révolutionne rien ici. Il reformule un principe de base du SEO que tout praticien devrait maîtriser depuis des années.
Ce qui est intéressant, c'est que Google continue de marteler ce message. Pourquoi ? Parce que trop de sites perdent encore du trafic à cause de problèmes de crawl basiques — et ça, c'est vérifiable dans n'importe quel audit technique.
Quelles nuances faut-il apporter à cette vision simplifiée ?
La réalité du crawl est plus complexe que cette définition. Google utilise plusieurs types de crawlers : Googlebot Desktop, Googlebot Mobile, Googlebot Image, etc. Chacun a ses priorités et ses limites.
Le passage d'un crawler ne garantit aucunement l'indexation. J'ai vu des sites avec des millions de pages crawlées mais seulement quelques milliers indexées — souvent à cause de contenu dupliqué, de thin content ou de cannibalisation.
Et c'est là que ça coince : Google ne précise jamais combien de temps il garde en cache une page crawlée avant de la recrawler, ni comment il priorise les URLs dans son budget. [À vérifier] via vos propres logs serveur.
Dans quels cas cette règle ne s'applique-t-elle pas complètement ?
Certaines pages peuvent apparaître dans les résultats sans avoir été entièrement crawlées — Google peut indexer une URL basée uniquement sur des signaux externes (liens, ancres) si le contenu n'est pas accessible.
Les contenus protégés par login, les PDF sans version HTML alternative, les contenus générés dynamiquement sans SSR : autant de zones grises où le crawl classique ne fonctionne pas comme décrit.
Impact pratique et recommandations
Que faut-il faire concrètement pour optimiser le crawl de votre site ?
Premier réflexe : analysez vos logs serveur. Aucun outil tiers ne vous donnera une vision aussi précise de ce que Googlebot fait réellement sur votre site — quelles pages, à quelle fréquence, avec quel taux d'erreur.
Ensuite, nettoyez votre robots.txt. Trop de sites bloquent accidentellement des ressources critiques (CSS, JS) ou des sections entières par méconnaissance. Testez-le dans Google Search Console.
Optimisez votre maillage interne pour faciliter la découverte. Les pages orphelines (sans lien entrant) ne seront jamais crawlées naturellement — même si elles sont dans votre sitemap.
Quelles erreurs éviter absolument ?
Ne surchargez pas votre sitemap avec des URLs non stratégiques. Un sitemap de 50 000 URLs dont 40 000 sont du contenu pauvre dilue le signal et gaspille le budget de crawl.
Évitez les chaînes de redirections (A → B → C). Chaque saut consomme du budget et ralentit le crawl. Une redirection directe (A → C) est toujours préférable.
Ne négligez pas la vitesse serveur. Un TTFB (Time To First Byte) supérieur à 500ms freine Googlebot, qui adapte son agressivité pour ne pas surcharger votre infrastructure.
Comment vérifier que votre site est crawlé efficacement ?
Utilisez le rapport de couverture dans Google Search Console pour identifier les URLs exclues, les erreurs de crawl et les pages découvertes mais non indexées.
Comparez le nombre de pages crawlées (logs serveur) avec le nombre de pages indexées (commande site: ou GSC). Un écart important signale un problème de qualité ou de structure.
- Installer un outil d'analyse de logs serveur (Oncrawl, Screaming Frog Log Analyzer, etc.)
- Vérifier le fichier robots.txt avec l'outil de test de Google Search Console
- Auditer le maillage interne pour éliminer les pages orphelines
- Optimiser le sitemap XML en ne gardant que les URLs stratégiques et canoniques
- Corriger toutes les chaînes de redirections et les erreurs 404 récurrentes
- Améliorer le TTFB et la vitesse de réponse serveur (CDN, cache, compression)
- Implémenter le rendu côté serveur (SSR) pour les sites JavaScript lourds
- Monitorer régulièrement le rapport de couverture dans GSC
Le crawl est le maillon invisible mais critique de votre visibilité organique. Sans stratégie technique solide, vous perdez du potentiel avant même que Google n'évalue votre contenu.
Ces optimisations — de l'analyse des logs à l'architecture du maillage interne — demandent une expertise pointue et des outils spécialisés. Si vous n'avez ni le temps ni les ressources en interne, faire appel à une agence SEO spécialisée peut accélérer significativement vos résultats et éviter des erreurs coûteuses.
❓ Questions frequentes
Quelle est la différence entre crawl et indexation ?
Comment savoir si Google crawle mon site régulièrement ?
Mon sitemap suffit-il pour garantir le crawl de toutes mes pages ?
Pourquoi certaines pages sont crawlées mais jamais indexées ?
Le budget de crawl est-il un problème pour les petits sites ?
🎥 De la même vidéo 9
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 22/02/2024
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.