Declaration officielle
Autres déclarations de cette vidéo 9 ▾
- □ Comment Google crawle-t-il vraiment vos pages web ?
- □ Comment Google découvre-t-il vraiment vos nouvelles pages ?
- □ Pourquoi Google ne découvre-t-il pas toutes les URLs de votre site ?
- □ Comment Googlebot décide-t-il quelles pages crawler sur votre site ?
- □ Pourquoi Googlebot ignore-t-il une partie des URLs qu'il découvre ?
- □ Googlebot peut-il vraiment crawler le contenu derrière une page de connexion ?
- □ Pourquoi Google ne voit-il pas votre contenu JavaScript sans rendering ?
- □ Faut-il vraiment un sitemap XML pour être indexé par Google ?
- □ Faut-il vraiment automatiser la génération de vos sitemaps ?
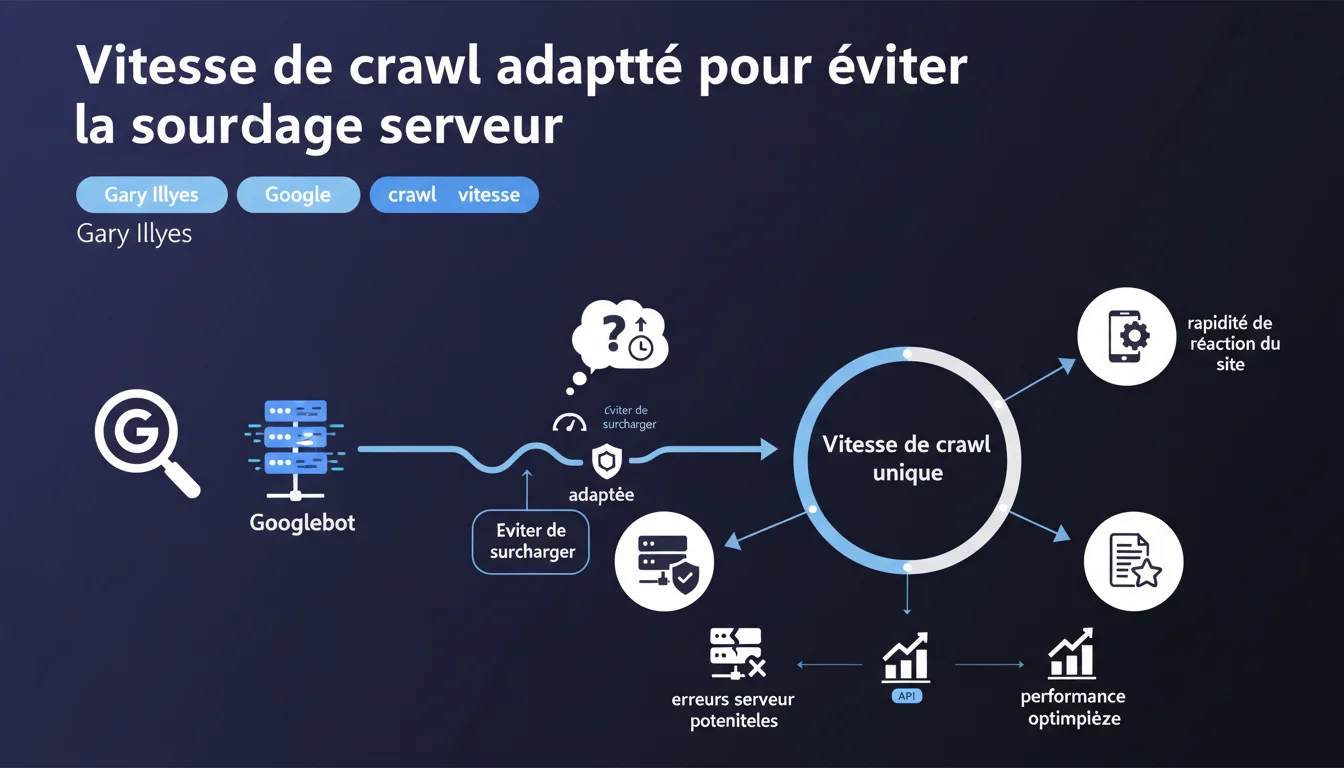
Googlebot ajuste sa vitesse de crawl site par site pour éviter de surcharger vos serveurs. Cette vitesse dépend de trois facteurs : la rapidité de réponse du serveur, la qualité du contenu découvert, et la fréquence des erreurs techniques rencontrées.
Ce qu'il faut comprendre
Comment Googlebot décide-t-il de sa vitesse de crawl sur un site ?
Google ne crawle pas tous les sites à la même cadence. Chaque domaine se voit attribuer une vitesse de crawl personnalisée, que l'algorithme recalcule en permanence selon trois paramètres : la capacité du serveur à répondre rapidement, la proportion de contenu jugé qualitatif, et le taux d'erreurs techniques (500, timeouts, DNS failures).
Concrètement ? Si votre serveur met 800 ms à répondre en moyenne, Googlebot espacera ses requêtes pour ne pas aggraver la situation. À l'inverse, un serveur ultra-réactif avec du contenu régulièrement mis à jour bénéficiera d'un crawl plus agressif.
Pourquoi cette limitation existe-t-elle ?
Google ne veut pas que son bot provoque des pannes ou des ralentissements chez ses utilisateurs. La vitesse de crawl est bridée par défaut — ce n'est pas un cadeau, c'est une contrainte technique pour préserver la stabilité du web.
Pour un petit site hébergé sur un serveur partagé, des centaines de requêtes simultanées pourraient saturer les ressources disponibles et rendre le site inaccessible aux visiteurs réels. Google limite donc volontairement son appétit.
Quels sont les critères techniques qui influencent cette vitesse ?
- Temps de réponse serveur : plus vos pages se chargent rapidement, plus Googlebot peut crawler intensément sans risquer de vous mettre à genoux
- Qualité du contenu découvert : si 80% des URLs crawlées renvoient vers du thin content ou des duplicatas, Google ralentit naturellement le rythme
- Taux d'erreurs techniques : erreurs 5xx, timeouts DNS, certificats SSL expirés — chaque anomalie envoie un signal de fragilité qui bride le crawl
- Historique du site : un domaine stable depuis des années inspire plus de confiance qu'un site qui change d'hébergeur tous les trimestres
Avis d'un expert SEO
Cette déclaration est-elle cohérente avec les observations terrain ?
Oui — et non. Sur le principe, c'est vrai : Googlebot ne crawle pas à fond les ballons sans tenir compte de votre infrastructure. Mais la formulation reste vague sur les seuils déclencheurs. À partir de quel temps de réponse moyen Google commence-t-il à freiner ? Aucune métrique officielle.
En pratique, on observe que des sites avec un TTFB supérieur à 600-800 ms voient leur crawl budget sérieusement réduit. Mais Google ne l'admettra jamais noir sur blanc — ça reste de l'observation empirique. [À vérifier] avec vos propres logs serveur.
Quelles nuances faut-il apporter à cette affirmation ?
Gary Illyes parle de "qualité du contenu" comme facteur, mais ça reste un critère subjectif et multifactoriel. Un site peut avoir un contenu objectivement excellent et se faire quand même crawler mollement si son architecture technique est pourrie.
Autre point : le crawl budget n'est pas qu'une question de vitesse maximale autorisée. C'est aussi une question d'allocation de ressources. Google peut décider de crawler lentement parce que votre contenu ne mérite pas mieux, pas forcément parce que votre serveur est fragile.
Dans quels cas cette règle ne s'applique-t-elle pas ?
Sur des sites géants type marketplaces ou agrégateurs de contenu, Google alloue des ressources massives quoi qu'il arrive. Leur crawl budget est structurellement plus élevé — pas parce que leur serveur est meilleur, mais parce que leur contenu est stratégique pour Google.
Inversement, un petit blog WordPress parfaitement optimisé ne verra jamais son crawl rate exploser. La vitesse de crawl maximale théorique importe peu si Google n'a aucune raison de crawler 10 000 URLs par jour.
Impact pratique et recommandations
Que faut-il faire concrètement pour optimiser sa vitesse de crawl ?
Réduire le temps de réponse serveur est la priorité absolue. Un TTFB inférieur à 200 ms sur l'ensemble du site envoie un signal positif à Googlebot. Passez à un hébergement dédié ou cloud si vous êtes encore sur du mutualisé bas de gamme.
Ensuite, nettoyez votre sitemap et robots.txt. Si Googlebot perd du temps à crawler des facettes inutiles, des paramètres d'URL redondants ou des pages paginées sans fin, il consommera son quota sans indexer vos pages stratégiques.
Quelles erreurs éviter absolument ?
Ne bridez pas artificiellement Googlebot dans votre robots.txt avec un Crawl-delay directif — ça ne marche pas avec Google et ça peut même être contre-productif. Google ignore cette directive. Si vous voulez réguler le crawl, passez par la Search Console.
Évitez aussi de multiplier les redirections en chaîne et les liens cassés. Chaque 404 ou 301 inutile grignote du crawl budget sans apporter de valeur. Un audit technique régulier doit identifier et corriger ces points de friction.
Comment vérifier que mon site est correctement crawlé ?
- Analysez vos logs serveur pour mesurer le crawl rate réel (requêtes Googlebot par seconde) et identifier les pics ou creux anormaux
- Consultez le rapport "Statistiques d'exploration" dans la Search Console pour suivre l'évolution du nombre de pages crawlées par jour
- Comparez le nombre de pages crawlées au nombre de pages indexables — un écart important signale un problème de crawl budget
- Vérifiez votre TTFB moyen avec des outils comme WebPageTest ou GTmetrix, ciblez moins de 300 ms
- Traquez les erreurs 5xx et timeouts dans vos logs — un taux supérieur à 1% freine le crawl
- Assurez-vous que vos pages stratégiques sont crawlées au moins une fois par semaine
❓ Questions frequentes
Peut-on augmenter manuellement la vitesse de crawl de Googlebot ?
Un serveur plus puissant garantit-il un meilleur crawl budget ?
Les erreurs 404 impactent-elles la vitesse de crawl ?
Comment savoir si mon site est limité par le crawl budget ?
Le passage en HTTPS améliore-t-il la vitesse de crawl ?
🎥 De la même vidéo 9
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 22/02/2024
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.