Declaration officielle
Autres déclarations de cette vidéo 10 ▾
- □ Faut-il baliser les programmes de fidélité pour améliorer ses résultats enrichis ?
- □ Pourquoi Google abandonne-t-il 7 types de données structurées et que faut-il faire maintenant ?
- □ Faut-il maintenir les données structurées si Google arrête d'en afficher certaines ?
- 4:56 Pourquoi Google refuse-t-il de s'engager sur l'avenir des AI Overviews ?
- 6:24 Pourquoi Google n'indexe-t-il pas toutes vos pages et comment l'anticiper ?
- 8:48 Peut-on empêcher Google de nous positionner sur certains mots-clés ?
- 9:56 La qualité d'une page suffit-elle pour garantir son indexation ?
- 9:56 Combien de temps Google met-il vraiment à reconnaître les changements SEO ?
- 12:00 Faut-il vraiment compter le nombre exact d'URLs de son site ?
- 15:15 Faut-il vraiment soumettre son sitemap tous les jours ?
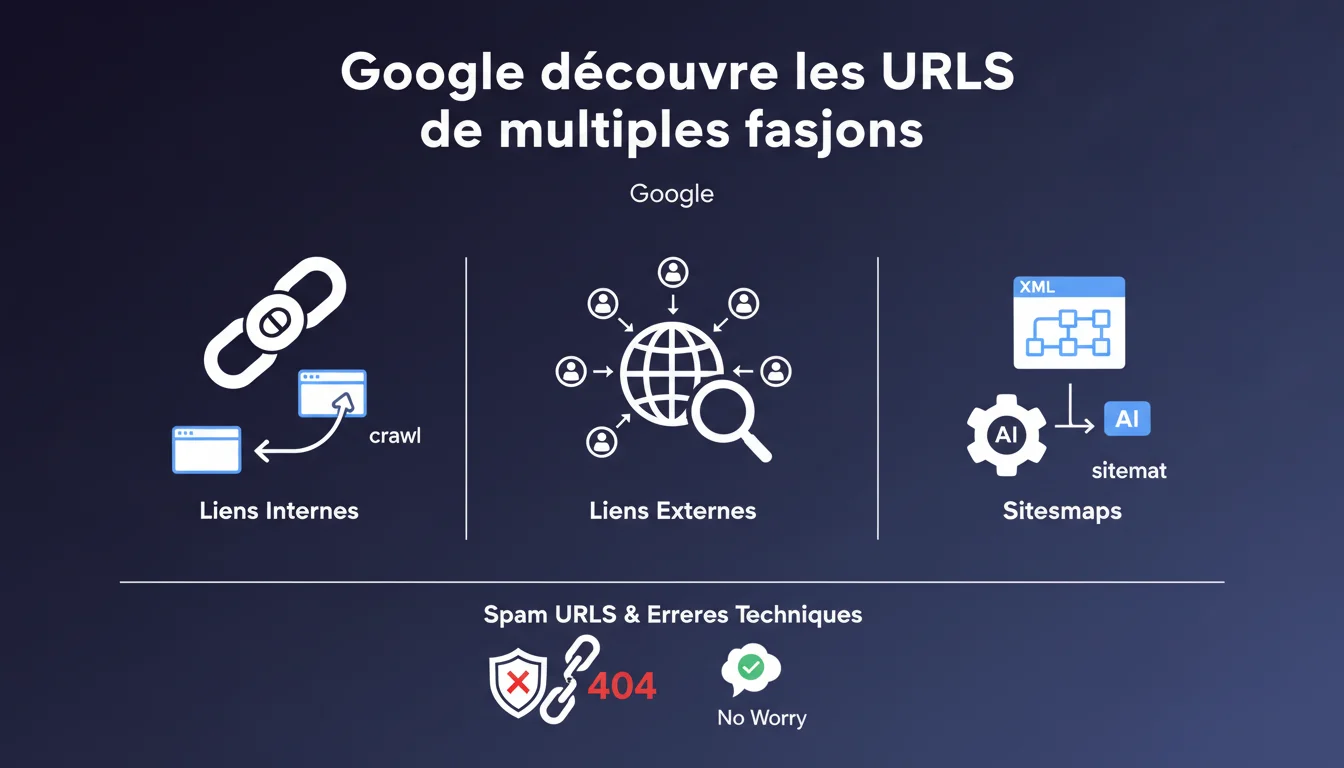
Google crawle les URLs via trois canaux principaux : liens internes, liens externes et sitemaps. Pas besoin de paniquer face aux URLs spam ou techniques que Google détecte, surtout si elles renvoient vers des 404. Le moteur gère lui-même le tri.
Ce qu'il faut comprendre
Quels sont les trois modes de découverte d'URLs par Google ?
Google identifie les pages à indexer via trois mécanismes distincts : le crawl des liens internes présents sur votre site, la détection de liens externes (backlinks) pointant vers vos pages, et la lecture de vos sitemaps XML. Ces trois canaux fonctionnent en parallèle et se complètent.
Concrètement ? Une page peut être découverte par Google même si elle n'apparaît pas dans votre sitemap, à condition qu'un lien interne ou externe y mène. Inversement, une URL présente uniquement dans le sitemap sera crawlée, mais avec une priorité potentiellement différente selon les signaux externes.
Pourquoi Google précise-t-il qu'il ne faut pas s'inquiéter des URLs spam crawlées ?
Cette nuance vise les propriétaires de sites qui paniquent en voyant dans la Search Console des URLs techniques ou parasites apparaître dans les rapports de crawl. Google signale que le simple fait qu'une URL soit crawlée ne signifie pas qu'elle sera indexée.
Si ces URLs redirigent vers des 404 ou des codes 410, Google les traite comme inexistantes à terme. Le moteur ajuste son comportement : pas de gaspillage du crawl budget sur des impasses qui persistent. Soyons honnêtes — c'est une tentative de rassurer les webmasters qui surveillent leurs logs comme des paranoïaques.
Qu'est-ce qui change pour un site bien structuré ?
Rien de fondamental si votre architecture est propre. Les sites avec un maillage interne cohérent, des sitemaps à jour et une gestion rigoureuse des redirections et erreurs 404 n'ont aucune raison de modifier leur approche.
Le problème se pose davantage pour les sites avec des milliers d'URLs générées automatiquement, des facettes non contrôlées ou des injections de spam dans les paramètres. Là, Google dit en substance : « On crawle, on voit, on ignore si c'est de la pollution. »
- Google utilise trois sources principales pour découvrir vos URLs : liens internes, backlinks, sitemaps.
- Le crawl d'une URL spam ou technique ne signifie pas indexation automatique.
- Les pages renvoyant des 404 ou 410 sont progressivement retirées du périmètre de crawl actif.
- Pas besoin de bloquer manuellement chaque URL parasite si elle ne mène nulle part — Google s'en charge.
Avis d'un expert SEO
Cette déclaration correspond-elle aux observations terrain ?
Oui, dans les grandes lignes. On constate effectivement que Google crawle des URLs absurdes — paramètres GET sans fin, IDs de session, URLs injectées par des bots. Ces URLs apparaissent dans les rapports de couverture, mais disparaissent rapidement si elles renvoient des erreurs HTTP.
Cependant — et c'est là que ça coince — Google ne précise pas à quelle vitesse il ajuste son comportement de crawl face à ces impasses. Sur un gros site e-commerce avec des milliers de facettes dynamiques, le moteur peut continuer à crawler des URLs inutiles pendant des semaines, voire des mois, avant d'ajuster son allocation de ressources. [A vérifier] : la notion de « pas nécessaire de s'inquiéter » reste floue pour les sites à fort volume.
Quelles nuances faut-il apporter selon le type de site ?
Pour un blog WordPress classique ou un site vitrine avec quelques dizaines de pages, cette déclaration est parfaitement valable. Le trio liens internes + backlinks + sitemap suffit amplement. Aucun risque de saturation du crawl budget.
En revanche, sur une plateforme marketplace, un site d'annonces ou un média avec pagination infinie, la situation diffère radicalement. Les URLs techniques (filtres, tris, paginations mal gérées) peuvent monopoliser une partie significative du crawl budget. Dire « Google s'en occupe tout seul » devient alors insuffisant — il faut intervenir avec des robots.txt ciblés, des canonicals et un sitemap scrupuleusement nettoyé.
Doit-on vraiment ignorer les URLs spam crawlées par Google ?
Pas toujours. Si ces URLs apparaissent dans vos backlinks (spam négatif SEO classique), Google affirme les ignorer — mais observer leur persistance dans les logs reste utile pour détecter une attaque. Un pic soudain d'URLs parasites peut signaler une faille de sécurité ou une tentative de saturation.
Par ailleurs, certains webmasters constatent que Google continue à crawler des URLs pourtant bloquées en robots.txt ou renvoyant des 410 depuis des mois. Pourquoi ? [A vérifier] : soit un délai d'ajustement anormalement long, soit une réévaluation périodique pour vérifier si le statut HTTP a changé. Google ne dit rien là-dessus.
Impact pratique et recommandations
Que faut-il faire concrètement pour optimiser la découverte de vos URLs ?
Première étape : auditer votre maillage interne. Assurez-vous que chaque page stratégique est accessible en 3 clics maximum depuis la home, et qu'aucun contenu important ne dépend uniquement du sitemap pour être découvert. Le maillage interne reste le levier le plus puissant pour orienter Googlebot.
Ensuite, nettoyez votre sitemap. Retirez les URLs non canoniques, les redirections, les pages bloquées en robots.txt. Un sitemap pollué dilue le signal et ralentit la découverte des contenus prioritaires. Google le lit, mais il ne fait pas le ménage à votre place.
Enfin, surveillez vos backlinks entrants. Utilisez la Search Console pour repérer les liens toxiques ou les URLs parasites que des tiers pointent. Même si Google affirme les ignorer, un afflux massif peut signaler un problème sous-jacent.
Quelles erreurs éviter dans la gestion des URLs techniques ou spam ?
Erreur classique : bloquer en robots.txt des URLs déjà indexées. Résultat : Google ne peut plus crawler ces pages pour détecter leur statut HTTP, elles restent dans l'index avec un snippet vide. Préférez un 410 Gone ou une redirection 301 vers une page pertinente si l'URL a déjà été indexée.
Autre piège : négliger les paramètres GET dynamiques. Si votre CMS génère des URLs avec tri, filtres ou pagination infinie, configurez les URL parameters dans la Search Console ou utilisez des canonicals systématiques. Laisser Google « se débrouiller » sur un site de 50 000 produits, c'est jouer à la roulette russe avec votre crawl budget.
- Auditez votre maillage interne pour garantir une accessibilité optimale des pages stratégiques.
- Nettoyez votre sitemap XML : retirez redirections, canonicals, pages bloquées.
- Surveillez les URLs parasites dans les logs et la Search Console — même si Google dit les ignorer.
- Ne bloquez jamais en robots.txt des URLs déjà indexées — utilisez un 410 Gone ou une redirection.
- Configurez les paramètres d'URL dynamiques pour éviter la duplication de crawl.
- Testez régulièrement vos backlinks pour détecter du spam négatif SEO.
Comment s'assurer que Google crawle efficacement votre site ?
Consultez le rapport de couverture dans la Search Console. Repérez les URLs découvertes mais non explorées : si elles s'accumulent, c'est un signe que votre crawl budget est saturé ou mal alloué. Priorisez alors les pages à forte valeur via le maillage et le sitemap.
Analysez vos logs serveur pour identifier les patterns de crawl : Googlebot revient-il souvent sur des URLs inutiles ? Ignore-t-il des sections entières ? Ces données révèlent souvent des incohérences invisibles dans la Search Console.
❓ Questions frequentes
Google crawle-t-il toutes les URLs présentes dans mon sitemap ?
Dois-je bloquer en robots.txt les URLs spam que Google crawle ?
Les backlinks vers des URLs inexistantes nuisent-ils au SEO ?
Combien de temps Google met-il à arrêter de crawler une URL en 404 ?
Le maillage interne est-il plus important que le sitemap pour la découverte ?
🎥 De la même vidéo 10
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 26/06/2025
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.